Elasticsearch聚合查询详解(附带实例)
在实际项目中,Elasticsearch 用得多的还是聚合查询、分组查询以及结果高亮显示。
在解释什么是聚合之前,首先需要了解两个重要概念:
概括起来,聚合就是由一个或者多个桶、一个或者多个指标组合而成的数据查询统计功能。一个聚合查询可以只有一个桶或者一个指标,或者每样一个。在桶中甚至可以有多个嵌套的桶。比如,我们可以将文档按照其所属国家/地区进行分桶,再按照年龄分桶,最后对每个桶计算其平均薪资(一个指标)。
具体使用流程如下:
下面通过示例演示 AggregationBuilders 的数据统计功能:

图 1 Aggregation 统计查询的运行结果
通过输出发现,category 字段匹配的关键字被加上高亮的样式。我们可以通过 getHighlightField 获取并处理高亮显示的字段。
例如,我们可以按照类别(Category)对所有的书进行分桶,然后对每个桶计算其平均价格(一个指标)。
下面通过示例验证 AggregationBuilders 的分组聚合统计功能。
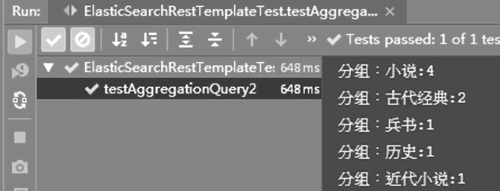
图 2 Aggregation 聚合查询的运行结果
通过输出发现,查询结果按照 category 字段分组聚合,然后统计每一组的数量。其实与数据库的分组比较类似,都是通过某个字段分组,然后进行统计。
上面是简单计算每个分组的数量,我们也可以先聚合,再计算每个 Buckets 的最大值、最小值等统计数据。对上面的示例做一些修改:
单击 Run Test 或在方法上右击,选择 Run 'testAggregationQuery3',运行单元测试方法,验证聚合统计的功能,运行结果如下图所示:
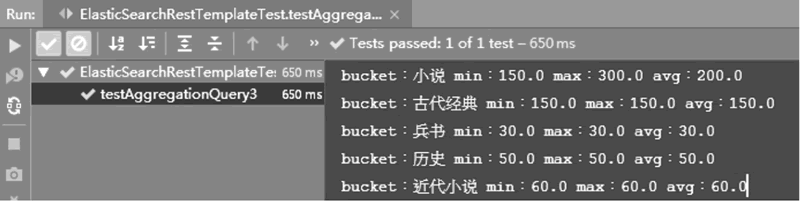
图 3 Aggregation聚合统计查询的运行结果
通过输出发现,查询结果按照 category 字段分组聚合,然后统计每个分组价格的最大值、最小值和平均值。
什么是聚合
聚合(Aggregation)是 Elasticsearch 非常重要的功能,它允许用户在数据上生成复杂的分析统计。它很像 SQL 中的 GROUP BY,但是比 GROUP BY 的功能更强大。在解释什么是聚合之前,首先需要了解两个重要概念:
- Buckets(桶):满足某个条件的文档集合。我们可以将文档数据按照一个或多个条件进行划分,比如按小时、按年龄区间、按地理位置等。当然,还有更加复杂的聚合,比如先将文档按天进行分桶,再将每天的桶按小时分桶。
- Metrics(指标):对某个桶中的文档计算得到的统计信息,比如使用 min、mean、max、sum 等计算得到的统计信息。
概括起来,聚合就是由一个或者多个桶、一个或者多个指标组合而成的数据查询统计功能。一个聚合查询可以只有一个桶或者一个指标,或者每样一个。在桶中甚至可以有多个嵌套的桶。比如,我们可以将文档按照其所属国家/地区进行分桶,再按照年龄分桶,最后对每个桶计算其平均薪资(一个指标)。
Elasticsearch实现统计查询
Elasticsearch 提供了 AggregationBuilders 类用于统计信息,比如最小值(min)、最大值(max)、总和(sum)、数量(count)、平均值(vag)等。具体使用流程如下:
- 使用 QueryBuilders 创建数据查询条件。
- 使用 AggregationBuilders 创建统计指标。
- 构建 NativeSearchQuery,合并数据查询条件和统计指标。
- 执行 search 并输出统计结果。
下面通过示例演示 AggregationBuilders 的数据统计功能:
@Test
public void testAggregationQuery() {
QueryBuilder queryBuilder= QueryBuilders.boolQuery()
.must(QueryBuilders.rangeQuery("price").gte(50));
// 1. 数量
ValueCountAggregationBuilder countAggregationBuilder= AggregationBuilders.count("count_id").field("id");
// 2. 求和
SumAggregationBuilder sumAggregationBuilder= AggregationBuilders.sum("sum_price").field("price");
// 3. 求最小值
MinAggregationBuilder minAggregationBuilder=AggregationBuilders.min("min_price").field("price");
// 4. 求最大值
MaxAggregationBuilder maxAggregationBuilder=AggregationBuilders.max("max_price").field("price");
// 5. 求平均值
AvgAggregationBuilder avgAggregationBuilder=AggregationBuilders.avg("avg_price").field("price");
// 全部统计指标
StatsAggregationBuilder statsAggregationBuilder=AggregationBuilders.stats("stats_price").field("price");
NativeSearchQuery nativeSearchQuery=new NativeSearchQueryBuilder()
.withQuery(queryBuilder)
.addAggregation(countAggregationBuilder)
.addAggregation(sumAggregationBuilder)
.addAggregation(minAggregationBuilder)
.addAggregation(maxAggregationBuilder)
.addAggregation(avgAggregationBuilder)
.addAggregation(statsAggregationBuilder).build();
SearchHits<Book> bookSearchHits=elasticsearchRestTemplate.search(nativeSearchQuery,Book.class,IndexCoordinates.of(Book_INDEX));
Map<String, Aggregation> aggregationMap = bookSearchHits.getAggregations().getAsMap();
ValueCount count = (ValueCount)aggregationMap.get("count_id");
Avg avg = (Avg)aggregationMap.get("avg_price");
Sum sum=(Sum) aggregationMap.get("sum_price");
Min min=(Min) aggregationMap.get("min_price");
Max max=(Max) aggregationMap.get("max_price");
Stats stats=(Stats) aggregationMap.get("stats_price");
System.out.println("count:"+count.getValue());
System.out.println("sum:"+sum.getValue());
System.out.println("min:"+min.getValue());
System.out.println("max:"+max.getValue());
System.out.println("avg:"+avg.getValue());
System.out.println("sum:"+stats.getSumAsString()+" "+
"min:"+stats.getMinAsString()+" "+
"max:"+stats.getMaxAsString()+" "+
"avg:"+stats.getAvgAsString()+" "+
"count:"+stats.getCount());
};
单击 Run Test 或在方法上右击,选择 Run 'testAggregationQuery',运行单元测试方法,验证 StringQuery 查询的效果,运行结果如下图所示:图 1 Aggregation 统计查询的运行结果
通过输出发现,category 字段匹配的关键字被加上高亮的样式。我们可以通过 getHighlightField 获取并处理高亮显示的字段。
Elasticsearch实现聚合查询
聚合是一些桶和指标的组合。一个聚合可以只有一个桶或者一个指标,或者每样一个。在桶中甚至可以有多个嵌套的桶。例如,我们可以按照类别(Category)对所有的书进行分桶,然后对每个桶计算其平均价格(一个指标)。
下面通过示例验证 AggregationBuilders 的分组聚合统计功能。
@Test
public void testAggregationQuery2() {
Query query = new NativeSearchQueryBuilder()
.addAggregation(AggregationBuilders.terms("category").field("category.keyword"))
.build();
SearchHits<Book> searchHits = elasticsearchRestTemplate.search(query, Book.class);
searchHits.getAggregations().asList().forEach(aggregation -> {
((Terms) aggregation).getBuckets()
.forEach(bucket -> System.out.println("分组:"+bucket.getKeyAsString()+":"+ bucket.getDocCount()));
});
};
单击 Run Test 或在方法上右击,选择 Run 'testAggregationQuery2',运行单元测试方法,验证分组查询功能,运行结果如下图所示:图 2 Aggregation 聚合查询的运行结果
通过输出发现,查询结果按照 category 字段分组聚合,然后统计每一组的数量。其实与数据库的分组比较类似,都是通过某个字段分组,然后进行统计。
上面是简单计算每个分组的数量,我们也可以先聚合,再计算每个 Buckets 的最大值、最小值等统计数据。对上面的示例做一些修改:
@Test
public void testAggregationQuery3() {
QueryBuilder queryBuilder= QueryBuilders.boolQuery()
.must(QueryBuilders.rangeQuery("price").gte(5));
TermsAggregationBuilder aggregationBuilder=AggregationBuilders.terms("category").field("category.keyword");
AggregationBuilder minAggregation=AggregationBuilders.min("min_price").field("price");
AggregationBuilder maxAggregation=AggregationBuilders.max("max_price").field("price");
AggregationBuilder avgAggregation=AggregationBuilders.avg("avg_price").field("price");
aggregationBuilder.subAggregation(minAggregation)
.subAggregation(maxAggregation)
.subAggregation(avgAggregation);
NativeSearchQuery nativeSearchQuery=new NativeSearchQueryBuilder().withQuery(queryBuilder)
.addAggregation(aggregationBuilder).build();
SearchHits<Book> searchHits = elasticsearchRestTemplate.search(nativeSearchQuery, Book.class);
Map<String, Aggregation> aggregationMap = searchHits.getAggregations().getAsMap();
Aggregation categorys = aggregationMap.get("category");
for (Terms.Bucket bucket: ((Terms) categorys).getBuckets()){
Aggregations aggregations=bucket.getAggregations();
System.out.print("bucket:"+bucket.getKeyAsString()+" ");
Min min= aggregations.get("min_price");
Max max= aggregations.get("max_price");
Avg avg= aggregations.get("avg_price");
System.out.println("min:"+min.getValue()+" "+"max:"+max.getValue()+" "+"avg:"+avg.getValue());
}
};
在上面的示例中,通过 AggregationBuilders 的 mix、max、avg 等方法构建聚合查询的数据统计信息。单击 Run Test 或在方法上右击,选择 Run 'testAggregationQuery3',运行单元测试方法,验证聚合统计的功能,运行结果如下图所示:
图 3 Aggregation聚合统计查询的运行结果
通过输出发现,查询结果按照 category 字段分组聚合,然后统计每个分组价格的最大值、最小值和平均值。
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: