Elasticsearch分片和副本详解(新手必看)
分片是 Elasticsearch 中存储数据、创建支撑数据结构(如倒排索引)、管理查询和分析数据的软件组件。它们是在索引创建期间分配给索引的 Apache Lucene 实例。在索引过程中,文档会被传递给分片,分片会创建不可变的文件段,将文档存储到持久的文件系统中。
Lucene 是一个高性能的引擎,可以高效地索引文档。在索引文档时,后台会进行许多操作,而Lucene能够非常高效地完成这些工作。例如,文档最初会被复制到分片的内存缓冲区中,然后写入可写段,之后被合并,并最终持久化到底层文件系统存储中。
下图展示了 Lucene 引擎在索引过程中的内部工作原理:
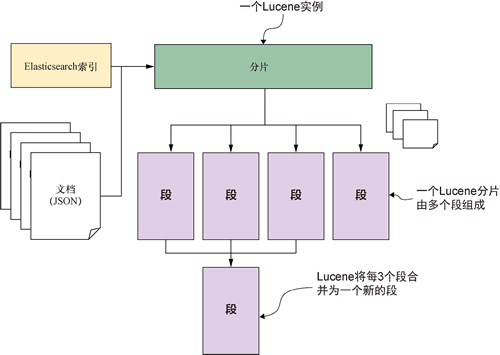
图 1 Lucene索引文档的机制
为了保证高可用性和故障切换,分片会分布在整个集群中。另外,副本为系统提供了冗余。索引一旦启用,分片就无法被重新分配,因为如果重新分配会导致索引中的现有数据失效。
作为分片的拷贝,副本在应用中提供了冗余和高可用性。通过服务读请求,副本可以在高峰时段分摊读负载。副本不会与相应的分片位于同一节点上,因为这会违背冗余的目的。例如,如果节点崩溃,而分片及其副本都在同一节点上,则会丢失它们的所有数据。因此,分片及其相应的副本分布在集群中的不同节点上。
集群(cluster)是一组节点的集合。节点(node)是 Elasticsearch 服务器的一个实例。例如,当我们在机器上启动一个 Elasticsearch 服务器时,实际上是创建了一个节点。默认情况下,这个节点会加入一个集群。因为该集群只有这个节点,所以它被称为单节点集群。如果启动更多的服务器实例,在设置正确的情况下,它们将加入这个集群。
假设我们创建了一个 virus_mutations 索引来保存 COVID-19 病毒的变异数据。根据我们的策略,该索引将被分配 3 个分片。
Elasticsearch 采用了一个简单的交通信号灯系统,让我们能够随时了解集群的健康状况。一个集群有以下 3 种可能的状态:
Elasticsearch 提供了集群 API 来获取与集群相关的信息,包括集群的健康状况。我们可以使用 GET _cluster/health 端点来获取集群的健康指标,下图展示了这个调用的结果。

图 2 通过调用集群的health端点来获取集群的状态
我们还可以使用 _cat API(紧凑且对齐的文本 API)调用来获取集群的健康状况。如果需要,我们可以直接在浏览器中调用此 API,而不是在 Kibana 中调用。例如,通过在服务器上调用 GET localhost:9200/_cat/health(调用时将 localhost 改为在 9200 端口上运行 Elasticsearch URL 的主机地址)来获取集群的健康状况。
当我们启动第一个节点(节点 A)时,索引的分片可能尚未全部创建完成。这通常发生在服务器刚刚启动时。Elasticsearch 将这种集群的状态标记为红色,表示系统不健康(见下图)。

图 3 引擎尚未准备就绪,状态为红色,因为分片还没有完全实例化
一旦节点 A 启动,根据设置,会在该节点上为 virus_mutations 索引创建 3 个分片(见图 4)。节点 A 默认加入一个新创建的单节点集群。由于 3 个分片都已经成功创建,因此索引和搜索操作可以立即开始。然而,副本尚未创建。副本是数据的拷贝,用于备份。在同一节点上创建它们并不是正确的做法(如果该节点崩溃,副本也会丢失)。

图 4 包含3个分片的节点加入一个单节点集群
由于副本尚未实例化,因此如果节点 A 出现任何问题,很可能会丢失数据。考虑到这一风险,集群的状态被设置为黄色。
当前所有分片都集中在一个节点上,如果该节点出于任何原因崩溃,我们将失去一切。为了避免数据丢失,我们决定启动第二个节点加入现有的集群。一旦新节点(节点 B)被创建并添加到集群中,Elasticsearch 可能会按照以下方式重新分配原有的 3 个分片:
这一操作通过调整分片将数据分布到了整个集群,如下图所示:
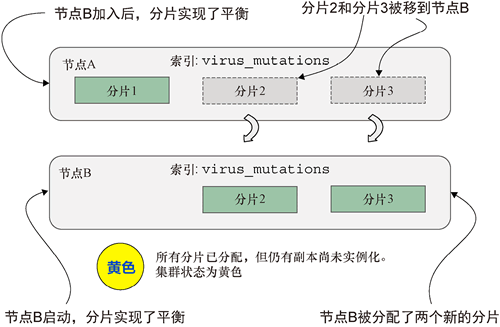
图 5 分片被平衡到新节点上,但副本尚未分配(黄色状态)
添加节点 B 后,分片被重新分配,实现了平衡。
注意 Elasticsearch 通过一个端点来公开集群的健康状况:GET _cluster/health。该端点可以获取集群的详细信息,包括集群名称、集群状态、分片和副本的数量等。
当新节点启动时,除了分配分片,还会实例化副本。每个分片都会创建一份拷贝,并且数据会从相应的分片复制到这些拷贝中。如前所述,副本不会与主分片位于同一节点上。副本 1 是分片 1 的拷贝,但它是在节点 B 上创建并可用的。类似地,副本 2 和副本 3 分别是位于节点 B 上的分片 2 和分片 3 的拷贝,但这些副本在节点 A 上可用(下图)。
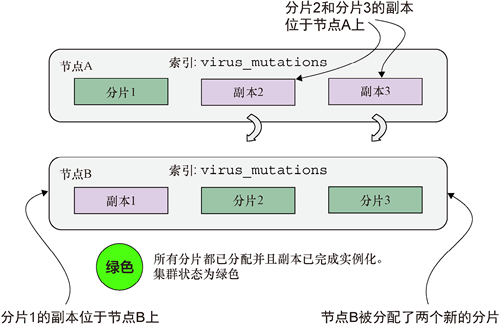
图 6 完美!所有分片和副本都已分配
分片和副本都已分配并准备就绪。集群的状态现在为绿色。
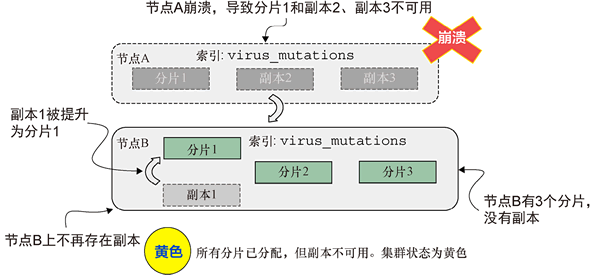
图 7 当节点崩溃时,副本会丢失(或被提升为分片)
现在节点 B 是集群中唯一的节点,它有 3 个分片。由于副本不再存在,集群的状态被设置为黄色。一旦 DevOps 团队恢复了节点 A,分片将被重新平衡和分配,副本也将被实例化,系统会尝试重新达到健康的绿色状态。
注意,Elasticsearch 可以处理此类灾难,并且在需要时能够以最小的资源运行,以避免停机,这一切都是在后台完成的,我们无须担心任何操作上的难题。
业界的最佳实践是将单个分片的大小控制在 50 GB 以内,但我也见过大小高达 400 GB 的分片。GitHub 的索引分布在 128 个分片上,每个分片 120 GB。我建议将分片大小控制在 25 GB~40 GB,同时考虑节点的堆内存。假如 movies 索引可能包含多达 500 GB 的数据,那么最好将这些数据分布在多个节点上的 10~20 个分片中。
在确定分片大小时,还有一个参数需要考虑,即堆内存。我们知道,节点的计算资源(如内存和磁盘空间)是有限的。每个 Elasticsearch 实例可以根据可用内存的大小来调整堆内存的使用量。我的建议是 1 GB 堆内存最多托管 20 个分片。默认情况下,Elasticsearch 实例化时使用 1 GB 内存,但可以通过编辑安装路径下 config 目录中的 jvm.options 文件来更改此设置。根据你的可用资源和需求,调整 JVM 的 Xms 和 Xmx 属性以设置堆内存。
重要的是,分片存储着数据,因此我们必须做一些准备工作来确定合适的大小。分片大小取决于索引存储的数据量(包括未来的需求)和可以为节点分配多少堆内存。在接入数据之前,每个组织都必须制定一个分片策略。平衡数据需求和最佳分片数量是至关重要的。
Lucene 是一个高性能的引擎,可以高效地索引文档。在索引文档时,后台会进行许多操作,而Lucene能够非常高效地完成这些工作。例如,文档最初会被复制到分片的内存缓冲区中,然后写入可写段,之后被合并,并最终持久化到底层文件系统存储中。
下图展示了 Lucene 引擎在索引过程中的内部工作原理:
图 1 Lucene索引文档的机制
为了保证高可用性和故障切换,分片会分布在整个集群中。另外,副本为系统提供了冗余。索引一旦启用,分片就无法被重新分配,因为如果重新分配会导致索引中的现有数据失效。
作为分片的拷贝,副本在应用中提供了冗余和高可用性。通过服务读请求,副本可以在高峰时段分摊读负载。副本不会与相应的分片位于同一节点上,因为这会违背冗余的目的。例如,如果节点崩溃,而分片及其副本都在同一节点上,则会丢失它们的所有数据。因此,分片及其相应的副本分布在集群中的不同节点上。
集群(cluster)是一组节点的集合。节点(node)是 Elasticsearch 服务器的一个实例。例如,当我们在机器上启动一个 Elasticsearch 服务器时,实际上是创建了一个节点。默认情况下,这个节点会加入一个集群。因为该集群只有这个节点,所以它被称为单节点集群。如果启动更多的服务器实例,在设置正确的情况下,它们将加入这个集群。
分片与副本的分布
每个分片都会存储一定量的数据。数据分布在多个节点上的多个分片中。让我们看看在启动新节点或失去节点时,分片是如何分布或减少的。假设我们创建了一个 virus_mutations 索引来保存 COVID-19 病毒的变异数据。根据我们的策略,该索引将被分配 3 个分片。
Elasticsearch 采用了一个简单的交通信号灯系统,让我们能够随时了解集群的健康状况。一个集群有以下 3 种可能的状态:
- 红色:有分片尚未分配,因此并非所有数据都可用于查询。这通常发生在集群启动期间,此时分片处于临时状态。
- 黄色:有副本尚未分配,但所有分片已分配并正常运行。这可能发生在托管副本的节点崩溃或刚刚启动时。
- 绿色:这是理想状态,所有分片和副本都已分配,并按预期提供服务。
Elasticsearch 提供了集群 API 来获取与集群相关的信息,包括集群的健康状况。我们可以使用 GET _cluster/health 端点来获取集群的健康指标,下图展示了这个调用的结果。
图 2 通过调用集群的health端点来获取集群的状态
我们还可以使用 _cat API(紧凑且对齐的文本 API)调用来获取集群的健康状况。如果需要,我们可以直接在浏览器中调用此 API,而不是在 Kibana 中调用。例如,通过在服务器上调用 GET localhost:9200/_cat/health(调用时将 localhost 改为在 9200 端口上运行 Elasticsearch URL 的主机地址)来获取集群的健康状况。
当我们启动第一个节点(节点 A)时,索引的分片可能尚未全部创建完成。这通常发生在服务器刚刚启动时。Elasticsearch 将这种集群的状态标记为红色,表示系统不健康(见下图)。
图 3 引擎尚未准备就绪,状态为红色,因为分片还没有完全实例化
一旦节点 A 启动,根据设置,会在该节点上为 virus_mutations 索引创建 3 个分片(见图 4)。节点 A 默认加入一个新创建的单节点集群。由于 3 个分片都已经成功创建,因此索引和搜索操作可以立即开始。然而,副本尚未创建。副本是数据的拷贝,用于备份。在同一节点上创建它们并不是正确的做法(如果该节点崩溃,副本也会丢失)。
图 4 包含3个分片的节点加入一个单节点集群
由于副本尚未实例化,因此如果节点 A 出现任何问题,很可能会丢失数据。考虑到这一风险,集群的状态被设置为黄色。
当前所有分片都集中在一个节点上,如果该节点出于任何原因崩溃,我们将失去一切。为了避免数据丢失,我们决定启动第二个节点加入现有的集群。一旦新节点(节点 B)被创建并添加到集群中,Elasticsearch 可能会按照以下方式重新分配原有的 3 个分片:
- 将分片 2 和分片 3 从节点 A 中移除。
- 将分片 2 和分片 3 添加到节点 B。
这一操作通过调整分片将数据分布到了整个集群,如下图所示:
图 5 分片被平衡到新节点上,但副本尚未分配(黄色状态)
添加节点 B 后,分片被重新分配,实现了平衡。
注意 Elasticsearch 通过一个端点来公开集群的健康状况:GET _cluster/health。该端点可以获取集群的详细信息,包括集群名称、集群状态、分片和副本的数量等。
当新节点启动时,除了分配分片,还会实例化副本。每个分片都会创建一份拷贝,并且数据会从相应的分片复制到这些拷贝中。如前所述,副本不会与主分片位于同一节点上。副本 1 是分片 1 的拷贝,但它是在节点 B 上创建并可用的。类似地,副本 2 和副本 3 分别是位于节点 B 上的分片 2 和分片 3 的拷贝,但这些副本在节点 A 上可用(下图)。
图 6 完美!所有分片和副本都已分配
分片和副本都已分配并准备就绪。集群的状态现在为绿色。
重新平衡分片
硬件故障的风险始终存在。在我们的例子中,如果节点 A 崩溃会发生什么?如果节点 A 消失,Elasticsearch 通过将副本 1 提升为分片 1 来重新调整分片,因为副本 1 是分片 1 的拷贝(见下图)。图 7 当节点崩溃时,副本会丢失(或被提升为分片)
现在节点 B 是集群中唯一的节点,它有 3 个分片。由于副本不再存在,集群的状态被设置为黄色。一旦 DevOps 团队恢复了节点 A,分片将被重新平衡和分配,副本也将被实例化,系统会尝试重新达到健康的绿色状态。
注意,Elasticsearch 可以处理此类灾难,并且在需要时能够以最小的资源运行,以避免停机,这一切都是在后台完成的,我们无须担心任何操作上的难题。
确定分片大小
一个常见的问题是如何确定分片的大小。这没有一个通用的答案。为了得到一个确切的结果,我们必须根据组织当前的数据需求和未来的需要进行测试。业界的最佳实践是将单个分片的大小控制在 50 GB 以内,但我也见过大小高达 400 GB 的分片。GitHub 的索引分布在 128 个分片上,每个分片 120 GB。我建议将分片大小控制在 25 GB~40 GB,同时考虑节点的堆内存。假如 movies 索引可能包含多达 500 GB 的数据,那么最好将这些数据分布在多个节点上的 10~20 个分片中。
在确定分片大小时,还有一个参数需要考虑,即堆内存。我们知道,节点的计算资源(如内存和磁盘空间)是有限的。每个 Elasticsearch 实例可以根据可用内存的大小来调整堆内存的使用量。我的建议是 1 GB 堆内存最多托管 20 个分片。默认情况下,Elasticsearch 实例化时使用 1 GB 内存,但可以通过编辑安装路径下 config 目录中的 jvm.options 文件来更改此设置。根据你的可用资源和需求,调整 JVM 的 Xms 和 Xmx 属性以设置堆内存。
重要的是,分片存储着数据,因此我们必须做一些准备工作来确定合适的大小。分片大小取决于索引存储的数据量(包括未来的需求)和可以为节点分配多少堆内存。在接入数据之前,每个组织都必须制定一个分片策略。平衡数据需求和最佳分片数量是至关重要的。
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: