Elasticsearch是什么(非常详细)
Elasticsearch 是一个基于 Lucene 构建的开源、分布式、RESTful 接口的全文搜索引擎。
Elasticsearch 使用倒排索引技术,将文档中的词语进行分词,并将分出的单个词语统一放入一个分词库,在搜索时,根据关键字去分词库中搜索,从而快速找到相关信息, Elasticsearch 能够进行横向扩展,可以在极短的时间内存储、搜索和分析大量的数据。
下图展示了是数据库网站 DB-Engines 在 2023 年 8 月发布的数据库流行度排行榜。
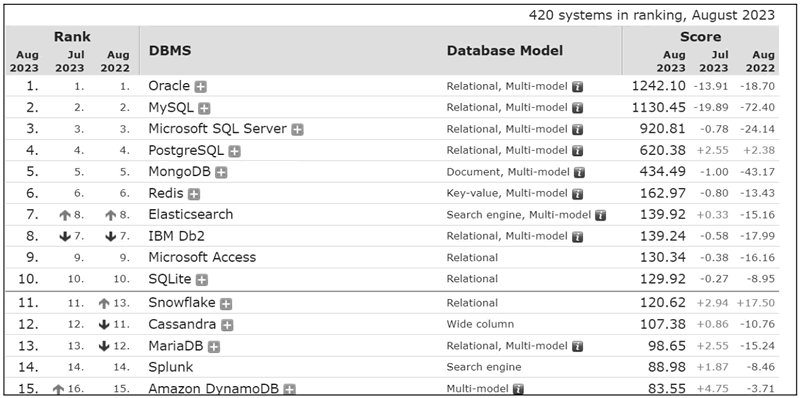
图 1 DB-Engines 发布的数据库流行度排行榜
从中可以看出,Elasticsearch 位于前 10 名,其受欢迎的程度可见一斑。
之后,Shay Banon 沙伊·巴农找到了一份工作,工作内容涉及大量的高并发分布式应用场景。于是,他决定重写 Compress,引入了分布式架构,并将 Compress 更名为 Elasticsearch。Elasticsearch 的第一个版本发布于 2010 年 5 月,发布后引发强烈反响。
Elasticsearch 在 GitHub 上发布后,使用量骤增,并很快有了自己的社区。没过多久,社区中的 Steven Schuurman、Uri Boness、Simon Willnauer 与 Shay Banon一起成立了搜索公司 Elasticsearch Inc.。
在 Elasticsearch Inc.成立前后,另外两个开源项目也正在快速发展:
由于作者间对彼此产品比较熟悉,因此他们决定合作发展,最终形成了 Elastic Stack 的经典技术栈 ELK:Elasticsearch, Logstash, Kibana。
从此以后,Elasticsearch 迅速发展,增加了许多新功能和特性。Elasticsearch 主要版本的发布时间如下图所示。
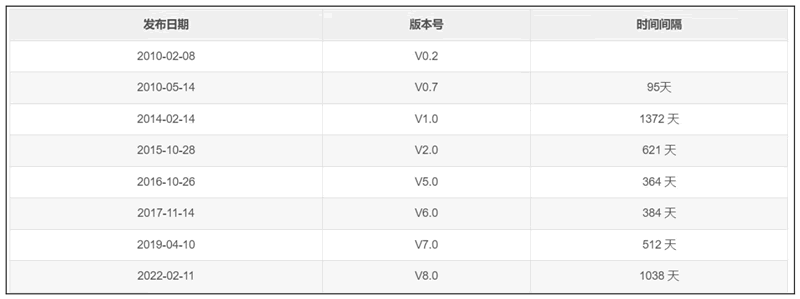
图 2 Elasticsearch 主要版本的发布时间
对于使用者来说,Elasticsearch 隐藏了复杂的分布式机制,使分布式机制对读者具有透明性:
同时,Elasticsearch 还支持复杂的数据分析和统计功能,可以帮助用户从海量数据中发现有价值的信息。
集群名称非常重要,具有相同集群名称的节点才会组成一个集群。集群名称可以在配置文件中来指定。
节点通过集群名称在网络中发现同伴,并组成集群。一个节点也可以是一个集群。
节点可以分为以下 3 类:
每个索引有唯一的名称,用户通过这个名称来操作对应索引。每个索引的名称必须是小写字母。一个索引是一个文档的集合。一个集群中可以有多个索引。
分片的优点是支持容量的水平切分/扩展,支持在多个分片上进行分布式的、并行的操作,从而提高系统的性能。
当查询的索引分布在多个分片上时,Elasticsearch 会把查询请求发送给每个相关的分片,并将这些分片的查询结果组合在一起。而应用程序并不知道分片的存在,即这个过程对用户来说是透明的。
安装完成后,使用命令行进入 Elasticsearch 安装目录的 bin 文件夹,执行以下命令来启动 Elasticsearch 服务。
以下是使用 curl 命令创建名为 “my_index”的索引的示例:
以下是一个示例,演示“my_index”索引中数据的聚合计算:
Elasticsearch 使用倒排索引技术,将文档中的词语进行分词,并将分出的单个词语统一放入一个分词库,在搜索时,根据关键字去分词库中搜索,从而快速找到相关信息, Elasticsearch 能够进行横向扩展,可以在极短的时间内存储、搜索和分析大量的数据。
下图展示了是数据库网站 DB-Engines 在 2023 年 8 月发布的数据库流行度排行榜。
图 1 DB-Engines 发布的数据库流行度排行榜
从中可以看出,Elasticsearch 位于前 10 名,其受欢迎的程度可见一斑。
Elasticsearch发展历程
许多年前,一个叫沙伊·巴农(Shay Banon)的年轻人想为正在学习厨艺的新婚妻子编写一款菜谱搜索软件。在开发过程中,他发现搜索引擎库 Lucene 不仅使用门槛高,还有许多重复性工作,因此决定在 Lucene 的基础上封装一个简单易用的搜索应用库,并将其命名为 Compress。Elasticsearch 的前身就在这样浪漫的机缘下诞生了。之后,Shay Banon 沙伊·巴农找到了一份工作,工作内容涉及大量的高并发分布式应用场景。于是,他决定重写 Compress,引入了分布式架构,并将 Compress 更名为 Elasticsearch。Elasticsearch 的第一个版本发布于 2010 年 5 月,发布后引发强烈反响。
Elasticsearch 在 GitHub 上发布后,使用量骤增,并很快有了自己的社区。没过多久,社区中的 Steven Schuurman、Uri Boness、Simon Willnauer 与 Shay Banon一起成立了搜索公司 Elasticsearch Inc.。
在 Elasticsearch Inc.成立前后,另外两个开源项目也正在快速发展:
- 一个是 Jordan Sissel 的开源可插拔数据采集工具 Logstash;
- 另一个是 Rashid Khan 的开源数据可视化 UI Kibana。
由于作者间对彼此产品比较熟悉,因此他们决定合作发展,最终形成了 Elastic Stack 的经典技术栈 ELK:Elasticsearch, Logstash, Kibana。
从此以后,Elasticsearch 迅速发展,增加了许多新功能和特性。Elasticsearch 主要版本的发布时间如下图所示。
图 2 Elasticsearch 主要版本的发布时间
Elasticsearch的核心特点
1) Elasticsearch对复杂分布式机制的透明隐藏特性
Elasticsearch 不仅是一个开源的搜索引擎,同时也是一套分布式的系统。分布式是为了应对大数据量。对于使用者来说,Elasticsearch 隐藏了复杂的分布式机制,使分布式机制对读者具有透明性:
- 分片机制:我们创建的文档能直接保存到 Elasticsearch 集群中,不需要知道这个文档会被保存在哪个分片中。
- 集群发现机制:先启动一个 Elasticsearch 进程,然后启动第二个 Elasticsearch 进程。这时,第二个进程将自动发现存在的集群,并自动加入这个集群。
- 分片负载均衡:假设集群中有 3 个节点,有 25 个片需要分配到这 3 个节点中,这时 Elasticsearch 会自动地进行均匀分配,以保证每一个节点均衡的读写负载请求。
2) Elasticsearch的搜索与分析功能
Elasticsearch 提供了强大的搜索与分析功能,用户可以使用不同的查询语言进行(高级)搜索,并对搜索结果进行聚合、排序、过滤等处理。同时,Elasticsearch 还支持复杂的数据分析和统计功能,可以帮助用户从海量数据中发现有价值的信息。
3) Elasticsearch的可伸缩与可用性
分布式架构使 Elasticsearch 具有良好的可伸缩性和高可用性。用户可以根据需求来水平扩展集群,并通过复制和故障转移机制来提高系统的稳定性和容错性。Elasticsearch基础概念
1) 集群
一个集群(Cluster)由一个唯一的名称进行标识,其名默认为“elasticsearch”。集群名称非常重要,具有相同集群名称的节点才会组成一个集群。集群名称可以在配置文件中来指定。
2) 节点
节点(Node),即一个 Elasticsearch 实例。节点也有自己的名称,在启动时默认以一个随机的 UUID 的前 7 个字符作为自己的名称。用户也可以为节点指定名称。节点通过集群名称在网络中发现同伴,并组成集群。一个节点也可以是一个集群。
节点可以分为以下 3 类:
- 主节点:集群中的一个节点会被选为主(Master)节点,该节点负责管理集群范畴的变更,例如创建或删除索引、添加节点到集群或从集群删除节点。Master 节点无须参与文档层面的变更和搜索,这意味着仅有一个 Master 节点并不会因流量增长而成为瓶颈。任意一个节点都可以成为 Master 节点。
- 数据节点:包含已建立索引的文档的分片。数据节点处理与数据相关的操作,例如 CRUD、搜索和聚合。每个节点都可以通过设定配置文件 elasticsearch.yml 中的 node.data 属性为 true(默认)成为数据节点。
- 客户端节点:如果 node.master 属性和 node.data 属性都被设置为 false,那么该节点将是一个客户端节点,扮演负载均衡的角色,将接收的请求路由到集群中的其他节点上。
3) 索引
Elasticsearch 数据管理的顶层单位叫作索引(Index),它的概念相当于关系数据库中数据库的概念。每个索引有唯一的名称,用户通过这个名称来操作对应索引。每个索引的名称必须是小写字母。一个索引是一个文档的集合。一个集群中可以有多个索引。
4) 类型
文档可以分组,比如 employee 文档可以按部门分组,也可以按职位分组。这种分组叫作类型,它是虚拟的逻辑分组,用于过滤类型,这类似于关系数据库中的数据表。5) 文档
索引中单条记录称为文档(Document)。许多条文档构成一个索引。文档使用 JSON 格式来表示。同一个索引中文档的结构不要求保持相同,但我们建议保持相同,因为这样有利于提高搜索效率。6) 分片
创建一个索引时可以指定索引分成多少个分片进行存储。每个分片本身也是一个功能完善且独立的“索引”,可以被放置在集群的任意节点上。分片的优点是支持容量的水平切分/扩展,支持在多个分片上进行分布式的、并行的操作,从而提高系统的性能。
当查询的索引分布在多个分片上时,Elasticsearch 会把查询请求发送给每个相关的分片,并将这些分片的查询结果组合在一起。而应用程序并不知道分片的存在,即这个过程对用户来说是透明的。
Elasticsearch基本操作
首先从 Elasticsearch 官方网站下载 Elasticsearch 安装包,然后按照官方文档提供的步骤进行安装和配置。安装完成后,使用命令行进入 Elasticsearch 安装目录的 bin 文件夹,执行以下命令来启动 Elasticsearch 服务。
./elasticsearch
1) 创建索引
在 Elasticsearch 中,数据存储在索引中,可以使用 RestFUL API 或者 Elasticsearch 的客户端库来创建索引。以下是使用 curl 命令创建名为 “my_index”的索引的示例:
curl -X PUT "localhost:9200/my_index"
2) 添加文档
在索引中添加文档,文档采用 JSON 格式来表示。以下是向“my_index” 索引中添加一个文档的示例:
curl -X POST "localhost:9200/my_index/_doc" -H "Content-Type:application/json" -d '
{
"title": "Elasticsearch Example",
"content": "This is an example document for Elasticsearch.}'
3) 搜索文档
以下是搜索“my_index”索引中标题包含“Elasticsearch”的文档的示例:
curl -X GET "localhost:9200/my_index/_search" -H "Content-Type:application/json"
-d '
{
"query": {
"match": {
"title": "Elasticsearch"
}
}
}'
4) 聚合数据
Elasticsearch 提供了强大的聚合功能,可以对数据进行分组、计数、计算平均值等处理。以下是一个示例,演示“my_index”索引中数据的聚合计算:
curl -X GET "localhost:9200/my_index/_search" -H "Content-Type:application/json"
-d '
{
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}'
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: