Elasticsearch倒排索引详解(附带实例)
如果你查看任何一本书的末尾,通常会找到一个索引,将关键词映射到它们所在的页面。这其实就是倒排索引的一种物理表现形式。就像在书中根据关键词对应的页码来快速定位内容一样,Elasticsearch 也会通过查询倒排索引来寻找搜索词和文档之间的关联。
当引擎找到这些搜索词对应的文档 ID 时,它会通过查询服务器返回整个文档。Elasticsearch 在索引阶段对每个全文字段使用倒排索引,其数据结构如下图所示:

图 1 倒排索引的数据结构
在高层级上,倒排索引是一种类似字典的数据结构,其中包含单词及其出现的文档列表。这种倒排索引是在全文搜索阶段快速检索文档的关键。对于每个包含全文字段的文档,服务器都会创建一个相应的倒排索引。
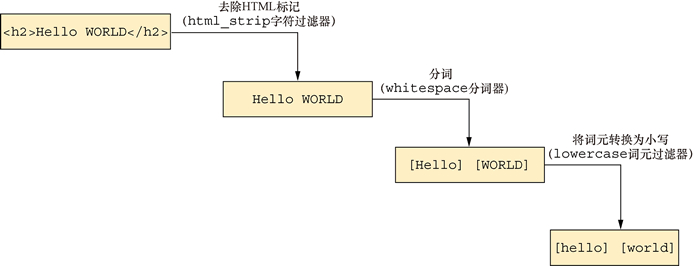
图 2 Elasticsearch处理文本的文本分析过程
来看一下整个过程(图 2)。输入行 <h2>Hello WORLD</h2> 被去除了不需要的字符,如 HTML 标记。清理后的数据根据空格被拆分成词元(很可能是单个单词),从而生成 Hello WORLD。最后,应用词元过滤器,使句子能够转换为词元:[hello] [world]。默认情况下,Elasticsearch 使用标准分析器将词元转换为小写。注意,标点符号(逗号)在这个过程中也被删除了。
在经过这些步骤后,就为该字段创建了一个倒排索引。它主要用于全文搜索功能。本质上,它是一个哈希映射,单词作为键,指向这些单词出现的文档。它由一组唯一的单词和这些单词在索引中所有文档中出现的频率组成。
回顾一下我们的例子。由于文档 1(“Hello, WORLD”)已被索引和分析,因此创建了一个倒排索引,其中包含了词元(单个单词)及它们所在的文档,如下表所示。
单词“hello”和“world”连同这些词所在的文档 ID(当然就是文档 ID 1)一起添加到倒排索引中。在倒排索引中还记录了这些单词在所有文档中出现的频率。
当文档 2(“Hello, Mate”)被索引时,数据结构会被更新(如下表所示):
在更新单词“hello”的倒排索引时,会追加文档 2 的文档 ID,同时增加该单词的出现频率。所有来自新文档的词元在被追加到数据结构之前,都会与倒排索引中的键进行匹配(如本例中的“mate”),如果该词元是首次出现,则会作为新记录添加。
现在这些文档已经创建了倒排索引,当搜索“hello”时,Elasticsearch 会先查询这个倒排索引。倒排索引指出单词“hello”出现在文档 ID 为 1 和文档 ID 为 2 的文档中,因此相关的文档将被获取并返回给客户端。
我们在这里过度简化了倒排索引,但这没关系,因为我们的目的是对这种数据结构有一个基本的了解。例如,如果我们现在搜索“hello mate”,文档 1 和文档 2 都会被返回,但文档 2 可能比文档 1 有更高的相关性分数,因为文档 2 的内容与查询更匹配。
虽然倒排索引针对更快的信息检索做了优化,但它也增加了分析的复杂性并且需要更多的空间。随着索引活动的增加,倒排索引也在不断增长,从而消耗计算资源和堆内存。我们不会直接操作这种底层数据结构,但理解其基本原理还是很有帮助的。
倒排索引还有助于推断相关性分数,它提供了词项的频率,这是计算相关性分数的一个重要因素。
当引擎找到这些搜索词对应的文档 ID 时,它会通过查询服务器返回整个文档。Elasticsearch 在索引阶段对每个全文字段使用倒排索引,其数据结构如下图所示:
图 1 倒排索引的数据结构
在高层级上,倒排索引是一种类似字典的数据结构,其中包含单词及其出现的文档列表。这种倒排索引是在全文搜索阶段快速检索文档的关键。对于每个包含全文字段的文档,服务器都会创建一个相应的倒排索引。
我们已经学习了一些关于倒排索引的理论知识,现在通过一个简单的例子来了解其工作原理。假设有两个文档,它们都有一个 greeting 文本字段:注意 BKD(block k-dimensional)树是用于存储非文本字段(如数值和地理形状)的特殊数据结构。
//文档1
{
"greeting":"Hello, WORLD"
}
//文档2
{
"greeting":"Hello, Mate"
}
在 Elasticsearch 中,分析过程是一个由分析器模块完成的复杂功能。分析器模块进一步由字符过滤器(character filter)、分词器(tokenizer)和词元过滤器(token filter)组成。当第一个文档被索引时,例如在 greeting 字段(文本字段)中,就会创建一个倒排索引。每个全文字段都由一个倒排索引支持。greeting 的值“Hello, World”经过分析、分词和归一化,最终转换为两个单词 “hello”和“world”。但是在此过程中还有一些步骤。图 2 Elasticsearch处理文本的文本分析过程
来看一下整个过程(图 2)。输入行 <h2>Hello WORLD</h2> 被去除了不需要的字符,如 HTML 标记。清理后的数据根据空格被拆分成词元(很可能是单个单词),从而生成 Hello WORLD。最后,应用词元过滤器,使句子能够转换为词元:[hello] [world]。默认情况下,Elasticsearch 使用标准分析器将词元转换为小写。注意,标点符号(逗号)在这个过程中也被删除了。
在经过这些步骤后,就为该字段创建了一个倒排索引。它主要用于全文搜索功能。本质上,它是一个哈希映射,单词作为键,指向这些单词出现的文档。它由一组唯一的单词和这些单词在索引中所有文档中出现的频率组成。
回顾一下我们的例子。由于文档 1(“Hello, WORLD”)已被索引和分析,因此创建了一个倒排索引,其中包含了词元(单个单词)及它们所在的文档,如下表所示。
| 单词 | 频率 | 文档ID |
|---|---|---|
| hello | 1 | 1 |
| world | 1 | 1 |
单词“hello”和“world”连同这些词所在的文档 ID(当然就是文档 ID 1)一起添加到倒排索引中。在倒排索引中还记录了这些单词在所有文档中出现的频率。
当文档 2(“Hello, Mate”)被索引时,数据结构会被更新(如下表所示):
| 单词 | 频率 | 文档ID |
|---|---|---|
| hello | 2 | 1,2 |
| world | 1 | 1 |
| mate | 1 | 2 |
在更新单词“hello”的倒排索引时,会追加文档 2 的文档 ID,同时增加该单词的出现频率。所有来自新文档的词元在被追加到数据结构之前,都会与倒排索引中的键进行匹配(如本例中的“mate”),如果该词元是首次出现,则会作为新记录添加。
现在这些文档已经创建了倒排索引,当搜索“hello”时,Elasticsearch 会先查询这个倒排索引。倒排索引指出单词“hello”出现在文档 ID 为 1 和文档 ID 为 2 的文档中,因此相关的文档将被获取并返回给客户端。
我们在这里过度简化了倒排索引,但这没关系,因为我们的目的是对这种数据结构有一个基本的了解。例如,如果我们现在搜索“hello mate”,文档 1 和文档 2 都会被返回,但文档 2 可能比文档 1 有更高的相关性分数,因为文档 2 的内容与查询更匹配。
虽然倒排索引针对更快的信息检索做了优化,但它也增加了分析的复杂性并且需要更多的空间。随着索引活动的增加,倒排索引也在不断增长,从而消耗计算资源和堆内存。我们不会直接操作这种底层数据结构,但理解其基本原理还是很有帮助的。
倒排索引还有助于推断相关性分数,它提供了词项的频率,这是计算相关性分数的一个重要因素。