一文了解什么是预训练模型(非常详细)
现有的神经网络在进行训练时,一般基于反向传播算法,先对网络中的参数进行随机初始化,再利用随机梯度下降等优化算法不断优化模型参数。
预训练属于迁移学习的范畴。预训练模型的思想是,模型参数不再是随机初始化的,而是通过一些任务进行预先训练,得到一套模型参数,然后用这套参数对模型进行初始化,再进行训练。
预训练将大量低成本收集的训练数据放在一起,经过某种预训练的方法来学习其中的共性,然后将其中的共性“移植”到特定任务的模型中,再使用相关特定领域的少量标注数据进行“微调”。因此,模型只需要从“共性”出发,来“学习”该特定任务的“特殊”部分。
例如,让一个完全不懂英文的人去做英文法律文书的关键词提取工作会完全无法进行,或者说他需要非常多的时间去学习,因为他现在根本看不懂英文。但是,如果让一个英语为母语但没接触过此类工作的人去做这项任务,他可能只需要相对比较短的时间学习如何提取法律文书的关键词就可以上手这项任务。
在这里,英文知识就属于“共性”的知识,这类知识不一定通过英文法律文书的相关语料进行学习,也可以通过大量英文语料学习,不管是小说、书籍,还是自媒体,都可以是学习资料的来源。
该例中,让完全不懂英文的人去完成这样的任务,就对应了传统的直接训练方法,而完全不懂英文的人如果在早期系统地学习了英文,再让他去做同样的任务,就对应了“预训练+微调”的思路,系统地学习英文即为“预训练”的过程。
大语言模型的预训练是指搭建一个大的神经网络模型并“喂”入海量的数据,以某种方法来训练语言模型。大语言模型预训练的主要特点是所用的数据量够多、模型够大。
例如,在自然语言处理领域,需要大量标注数据才能训练模型。通过使用预训练技术,可以利用未标记的数据来训练模型,从而提高模型的性能和泛化能力。
综上所述,预训练技术可以帮助机器学习模型解决数据稀缺性、先验知识和迁移学习等问题,从而提高模型的性能和可解释性,同时降低训练成本。
如下图所示,左边是 Transformer 模型的解码器,右边是大语言模型的预训练架构。
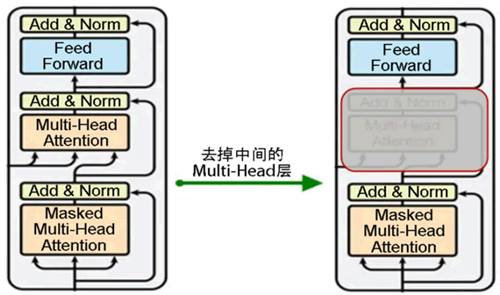
图 1 预训练基本原理
下面对大语言模型预训练过程中的批量训练、学习率、优化器和训练稳定性等方面进行讲解。
然而,随着大语言模型规模的扩大,模型的损失函数值更可能发生突变,导致模型训练的不稳定性。为了解决大语言模型训练稳定性的问题,训练时在发生损失函数的突变后,回溯到上一个保存的模型(Checkpoint),并跳过这一部分的训练数据继续进行模型的训练。
大模型预训练的优势主要有以下几点:
预训练后续阶段主要分为以下 3 个步骤:
预训练属于迁移学习的范畴。预训练模型的思想是,模型参数不再是随机初始化的,而是通过一些任务进行预先训练,得到一套模型参数,然后用这套参数对模型进行初始化,再进行训练。
预训练将大量低成本收集的训练数据放在一起,经过某种预训练的方法来学习其中的共性,然后将其中的共性“移植”到特定任务的模型中,再使用相关特定领域的少量标注数据进行“微调”。因此,模型只需要从“共性”出发,来“学习”该特定任务的“特殊”部分。
例如,让一个完全不懂英文的人去做英文法律文书的关键词提取工作会完全无法进行,或者说他需要非常多的时间去学习,因为他现在根本看不懂英文。但是,如果让一个英语为母语但没接触过此类工作的人去做这项任务,他可能只需要相对比较短的时间学习如何提取法律文书的关键词就可以上手这项任务。
在这里,英文知识就属于“共性”的知识,这类知识不一定通过英文法律文书的相关语料进行学习,也可以通过大量英文语料学习,不管是小说、书籍,还是自媒体,都可以是学习资料的来源。
该例中,让完全不懂英文的人去完成这样的任务,就对应了传统的直接训练方法,而完全不懂英文的人如果在早期系统地学习了英文,再让他去做同样的任务,就对应了“预训练+微调”的思路,系统地学习英文即为“预训练”的过程。
大语言模型的预训练是指搭建一个大的神经网络模型并“喂”入海量的数据,以某种方法来训练语言模型。大语言模型预训练的主要特点是所用的数据量够多、模型够大。
预训练的需求
预训练技术被广泛应用于各种机器学习任务,主要是为了解决以下问题。1) 数据稀缺性
在许多任务中,标记数据是很昂贵的,并且难以获取。例如,在自然语言处理领域,需要大量标注数据才能训练模型。通过使用预训练技术,可以利用未标记的数据来训练模型,从而提高模型的性能和泛化能力。
2) 先验知识问题
许多机器学习任务需要模型具备一定的先验知识和常识,例如自然语言处理中的语言结构和规则。通过使用预训练技术,可以让模型在未标记数据上学习这些知识,从而使其在各种任务上表现更好。3) 迁移学习问题
许多机器学习任务之间存在共性,例如自然语言处理中的语义理解和文本分类等。通过使用预训练技术,可以将模型从一个任务迁移到另一个任务,从而提高模型在新任务上的性能。4) 模型可解释性问题
预训练技术可以帮助模型学习抽象的特征,从而提高模型的可解释性。例如,在自然语言处理中,预训练技术可以使模型学习单词和短语的表示,从而提高模型的可解释性。综上所述,预训练技术可以帮助机器学习模型解决数据稀缺性、先验知识和迁移学习等问题,从而提高模型的性能和可解释性,同时降低训练成本。
预训练的基本原理
大语言模型预训练采用了 Transformer 模型的解码器部分,由于没有编码器部分,大语言模型去掉了中间的与编码器交互的多头注意力层。如下图所示,左边是 Transformer 模型的解码器,右边是大语言模型的预训练架构。
图 1 预训练基本原理
下面对大语言模型预训练过程中的批量训练、学习率、优化器和训练稳定性等方面进行讲解。
1) 批量训练
对于语言模型的预训练,通常将批量训练的大小(batch_size)设置为较大的数值来维持训练的稳定性。在最新的大语言模型训练中,采用了动态调整批量训练大小的方法,最终在训练期间批量训练大小达到百万规模。结果表明,动态调度批量训练的大小可以有效地稳定训练过程。2) 学习率
大语言模型训练的学习率通常采用预热和衰减的策略:- 学习率的预热是指模型在最初训练过程的 0.1%~0.5% 逐渐将学习率提高到最大值;
- 学习率衰减策略在后续训练过程中逐步降低学习率使其达到最大值的 10% 左右或者模型收敛。
3) 优化器
Adam 优化器和 AdamW 优化器是常用的训练大语言模型的优化方法,它们都是基于低阶自适应估计矩的一阶梯度优化。优化器的超参数通常设置为 β1=0.9、β2=0.95 等。4) 训练稳定性
在大语言模型的预训练期间,经常会遇到训练不稳定的问题,可能导致模型无法继续训练下去。目前,解决这个问题通常采用的方法有正则化和梯度裁剪。梯度裁剪的阈值通常设为 1.0,正则化系数为 0.1。然而,随着大语言模型规模的扩大,模型的损失函数值更可能发生突变,导致模型训练的不稳定性。为了解决大语言模型训练稳定性的问题,训练时在发生损失函数的突变后,回溯到上一个保存的模型(Checkpoint),并跳过这一部分的训练数据继续进行模型的训练。
预训练的主要优势
大语言模型预训练是一种先通过海量数据进行预训练,再进行微调的技术,其目的是提高机器学习算法的性能和效率。大模型预训练的优势主要有以下几点:
- 提高模型的泛化能力:通过大规模预训练,模型可以学习到更多的数据和知识,从而提高其对未知数据的泛化能力;
- 减少训练时间和数据量:预训练可以大幅减少训练时间和数据量,因为预训练的结果可以直接应用到其他任务上,避免了重复训练;
- 提高算法的效率:预训练可以使得算法更加高效,因为预训练的结果可以作为其他任务的初始值,避免从头开始训练的时间和计算资源浪费;
- 支持多种自然语言处理任务:预训练可以应用于各种自然语言处理任务,如文本分类、情感分析、机器翻译等,提高了自然语言处理技术的通用性和可拓展性;
- 提高模型的精度:大模型预训练可以提高模型的精度和性能,从而使得机器学习算法在各种任务上得到更好的表现。
预训练后续阶段
大语言模型的预训练是指使用大量的数据来训练大规模的模型,以获得初始化的模型参数。随着ChatGPT的出现,预训练完成后,还会采用监督学习、奖励模型以及强化学习进行进一步的微调,这被称为 RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)。预训练后续阶段主要分为以下 3 个步骤:
- 监督微调(Supervised Fine-Tuning,SFT):在大语言模型的训练过程中,需要标记者的参与以进行监督。这一步骤涉及训练监督策略模型;
- 奖励模型训练:通过标记者的人工标注,训练出一个合适的奖励模型,为监督策略建立评价标准;
- 近端策略优化(Proximal Policy Optimization,PPO)强化学习模型训练:采用近端策略优化进行强化学习。通过监督学习策略生成 PPO 模型,将最优结果用于优化和迭代原有的 PPO 模型参数。