一文彻底了解Elasticsearch(新手必看)
Elasticsearch 是一个分布式的基于 RESTful 接口的搜索和分析引擎,它建立在一个全文搜索引擎库 Apache Lucene 的基础之上。
Elasticsearch 可以说是目前最先进、高性能、全功能的搜索引擎,是目前全文搜索引擎的首选。
Elasticsearch 使用 Java 编写,它的目的是使全文检索变得简单,通过使用 Lucene 进行索引与搜索,同时,又隐藏了 Lucene 的复杂性,为开发者提供了一套简单易用的 RESTful API。
Elasticsearch 不仅仅是全文搜索引擎,它更是一个分布式的实时文档存储服务,能够轻松实现上百个服务节点的扩展,支持 PB 级别的结构化或者非结构化数据。
Elasticsearch 作为分布式实时分析搜索引擎,非常契合目前云计算的发展趋势,能够达到实时搜索,并且稳定、可靠、快速,安装使用方便。Elasticsearch 已经被各大互联网公司验证了其强大的数据检索能力。
Elasticsearch 适合非常多的使用场景,常见的使用场景如下:
以员工数据为例,一个文档代表一个员工数据,存储数据到 Elasticsearch 的行为叫作索引,但在索引一个文档之前,需要确定将文档存储在哪里,如下图所示:
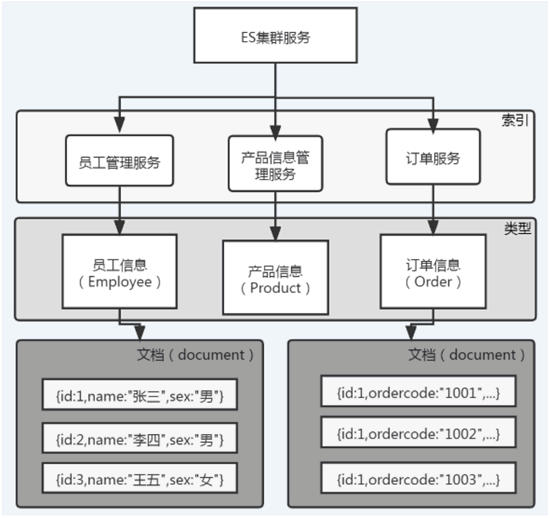
图 1 Elasticsearch 数据存储结构
如图 1 所示,一个 Elasticsearch 集群可以包含多个索引,每个索引又可以包含多个类型。这些不同的类型中存储着多个文档,每个文档又有多个属性字段。
听起来很绕,其实与数据库的关系比较类似,结合数据库的结构理解起来就会比较清楚:
Elasticsearch 集群可以包含多个索引,每个索引可以包含多个类型,每个类型可以包含多个文档,然后每个文档又可以包含多个字段。这与数据库的结构类似,在 DB 中可以有多个数据库,每个库中可以有多张表,每个表中又包含多行,每行包含多列。
索引也可以定义一个或多个类型,文档必须属于一个类型。在 Elasticsearch 中,一个索引对象可以存储多个不同用途的对象,通过索引类型可以区分单个索引中的不同对象,可以理解为关系型数据库中的表。每个索引类型可以有不同的结构,但是不同的索引类型不能为相同的属性设置不同的类型。
不同的类型应该有相似的数据结构(schema),例如,id 字段不能在这个组是字符串,在另一个组是数值,这是与关系型数据库的表的一个区别。结构完全不同的数据(比如 products 和 orders)应该存成两个索引,而不是一个索引的两个类型。
根据规划,Elastic 6.x 版只允许每个索引包含一个类型,7.x 版将会彻底移除类型。
每个文档由多个字段构成,Elasticsearch 是一个非结构化的数据库,每个文档可以有不同的字段,并且有一个唯一的标识符。
文档使用 JSON 作为数据的序列化格式,JSON 序列化为大多数编程语言所支持,并且已经成为 NoSQL 领域的标准格式。它简单、简洁、易于阅读。下面这个 JSON 文档代表了一个 user 对象:
Elasticsearch 的映射(Mapping)类似于静态语言中的数据类型:声明一个变量为 int 类型的变量,以后该变量只能存储 int 类型的数据。同样,一个 number 类型的 mapping 字段只能存储 number 类型的数据。与静态语言的数据类型相比,mapping 还有一些其他的含义:mapping 不仅告诉 Elasticsearch 一个 Field 中是什么类型的值,它还告诉 Elasticsearch 如何索引数据以及数据是否能被搜索到。
Elasticsearch 默认是动态创建索引和索引类型的 mapping 的。Elasticsearch 无须指定各个字段的索引规则就可以索引文件,使用起来很方便。
Spring Boot 对以上两种协议都做了很好的支持,使我们能够轻松将 Elasticsearch 集成到 Spring Boot 项目中。总结起来,常用的方式有以下 3 种:
推荐使用 Spring 提供的 Spring Data Elasticsearch 组件的方式,这种方式使用简单,容易上手。与使用 JPA 操作数据库类似。
Elasticsearch 可以说是目前最先进、高性能、全功能的搜索引擎,是目前全文搜索引擎的首选。
Elasticsearch 使用 Java 编写,它的目的是使全文检索变得简单,通过使用 Lucene 进行索引与搜索,同时,又隐藏了 Lucene 的复杂性,为开发者提供了一套简单易用的 RESTful API。
Elasticsearch 不仅仅是全文搜索引擎,它更是一个分布式的实时文档存储服务,能够轻松实现上百个服务节点的扩展,支持 PB 级别的结构化或者非结构化数据。
Elasticsearch 作为分布式实时分析搜索引擎,非常契合目前云计算的发展趋势,能够达到实时搜索,并且稳定、可靠、快速,安装使用方便。Elasticsearch 已经被各大互联网公司验证了其强大的数据检索能力。
Elasticsearch 适合非常多的使用场景,常见的使用场景如下:
- 搜索领域:如百度、谷歌等搜索企业;
- 门户网站:访问统计、文章点赞、留言评论等;
- 广告推广:记录用户行为数据、消费趋势、特定群体进行定制推广等;
- 信息采集:记录应用的埋点数据、访问日志数据等,方便大数据进行分析。
Elasticsearch数据结构
数据存储与检索是 Elasticsearch 的核心,下面通过一个例子介绍 Elasticsearch 是如何存储数据的。以员工数据为例,一个文档代表一个员工数据,存储数据到 Elasticsearch 的行为叫作索引,但在索引一个文档之前,需要确定将文档存储在哪里,如下图所示:
图 1 Elasticsearch 数据存储结构
如图 1 所示,一个 Elasticsearch 集群可以包含多个索引,每个索引又可以包含多个类型。这些不同的类型中存储着多个文档,每个文档又有多个属性字段。
听起来很绕,其实与数据库的关系比较类似,结合数据库的结构理解起来就会比较清楚:
- 索引(Index)=>数据库(Database);
- 类型(Type)=>表(Table);
- 文档(Document)=>表中的一行记录(Row);
- 属性(Field)=>字段列(Column)。
Elasticsearch 集群可以包含多个索引,每个索引可以包含多个类型,每个类型可以包含多个文档,然后每个文档又可以包含多个字段。这与数据库的结构类似,在 DB 中可以有多个数据库,每个库中可以有多张表,每个表中又包含多行,每行包含多列。
1) 索引
索引是含义相同的属性文档的集合,是 Elasticsearch 的一个逻辑存储,可以理解为关系型数据库中的数据库。Elasticsearch 可以把索引数据存放到一台服务器上,也可以分片后存到多台服务器上,每个索引有一个或多个分片,每个分片可以有多个副本。索引也可以定义一个或多个类型,文档必须属于一个类型。在 Elasticsearch 中,一个索引对象可以存储多个不同用途的对象,通过索引类型可以区分单个索引中的不同对象,可以理解为关系型数据库中的表。每个索引类型可以有不同的结构,但是不同的索引类型不能为相同的属性设置不同的类型。
2) 类型
文档可以分组,比如员工信息。这种分组就叫类型,它是虚拟的逻辑分组,用来过滤文档数据。不同的类型应该有相似的数据结构(schema),例如,id 字段不能在这个组是字符串,在另一个组是数值,这是与关系型数据库的表的一个区别。结构完全不同的数据(比如 products 和 orders)应该存成两个索引,而不是一个索引的两个类型。
根据规划,Elastic 6.x 版只允许每个索引包含一个类型,7.x 版将会彻底移除类型。
3) 文档
文档是可以被索引的基本数据单位,存储在 Elasticsearch 中的主要实体叫文档,可以理解为关系型数据库中表的一行记录。每个文档由多个字段构成,Elasticsearch 是一个非结构化的数据库,每个文档可以有不同的字段,并且有一个唯一的标识符。
文档使用 JSON 作为数据的序列化格式,JSON 序列化为大多数编程语言所支持,并且已经成为 NoSQL 领域的标准格式。它简单、简洁、易于阅读。下面这个 JSON 文档代表了一个 user 对象:
{
"id": 1,
"name": "张三",
"age": 20
}
同一个索引中的文档不要求有相同的结构(scheme),但是最好保持相同,这样有利于提高搜索效率。Elasticsearch 的映射(Mapping)类似于静态语言中的数据类型:声明一个变量为 int 类型的变量,以后该变量只能存储 int 类型的数据。同样,一个 number 类型的 mapping 字段只能存储 number 类型的数据。与静态语言的数据类型相比,mapping 还有一些其他的含义:mapping 不仅告诉 Elasticsearch 一个 Field 中是什么类型的值,它还告诉 Elasticsearch 如何索引数据以及数据是否能被搜索到。
Elasticsearch 默认是动态创建索引和索引类型的 mapping 的。Elasticsearch 无须指定各个字段的索引规则就可以索引文件,使用起来很方便。
Elasticsearch客户端
Elasticsearch 支持 HTTP 和 Native Elasticsearch Binary 两种协议:- HTTP 协议主要提供完善的 RESTful 接口,通过发送 HTTP 请求的形式查询数据;
- Native Elasticsearch Binary 协议其实就是 Elasticsearch 官方提供的 Transport 客户端。
Spring Boot 对以上两种协议都做了很好的支持,使我们能够轻松将 Elasticsearch 集成到 Spring Boot 项目中。总结起来,常用的方式有以下 3 种:
- Java API:这种方式基于 TCP 与 ES 通信,官方已经明确表示在 ES 7.0 版本中将弃用 TransportClient 客户端,而且在 8.0 版本中完全移除它,所以不提倡使用;
- REST Client:官方给出了基于 HTTP 的客户端 REST Client(推荐使用),包括 Java Low Level REST Client 与 Java Hight Level REST Client 两个,前者兼容所有版本的 ES,后者是基于前者开发出来的,只披露了部分 API,还有待完善;
- Spring Data Elasticsearch:Spring 提供了基于 Spring Data 实现的一套方案,它是 Spring Data 项目下的一个子模块。如果了解过 JPA 技术的话,会发现其操作语法与 JPA 非常类似,可以像操作数据库一样操作 Elasticsearch 中的缓存数据。
推荐使用 Spring 提供的 Spring Data Elasticsearch 组件的方式,这种方式使用简单,容易上手。与使用 JPA 操作数据库类似。