什么是模态对齐,实现模态对齐的方法有哪些?
模态对齐是指在多模态学习中,通过统一的表示或转换机制,将不同模态的数据进行语义上的匹配,使其能够在同一语义空间中进行对比和操作。对齐的核心目标是使模型能够理解和关联不同模态的内容,从而实现模态间的信息融合和转换。
在多模态知识图谱中,可以通过模态对齐技术区分相关特征与无关特征,如下图所示。
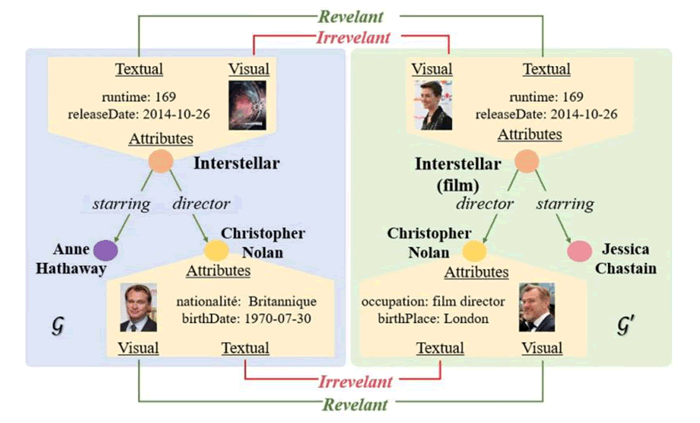
图 1 多模态知识图谱中的相关特征与无关特征对比
多模态知识图谱通过将文本和视觉等模态的信息结合,用于描述实体及其属性,例如电影的名称、导演、演员以及其相关的文本描述和图片特征。
在进行模态对齐过程中,模型需要通过联合建模和语义分析,识别与目标任务相关的模态信息,例如导演和演员的职业与身份,而忽略无关信息,如图片中背景或多余文本内容。
模态对齐的核心在于通过注意力机制或特征对比,优化模态间的语义一致性。例如,在处理视觉与文本数据时,模态对齐模块能够过滤噪声信息,仅提取对于任务有效的模态特征。这种对齐过程不仅提升了知识图谱的准确性,还为多模态任务提供了更高质量的输入数据,广泛应用于推荐系统、问答系统和语义搜索任务中。
通过模态对齐技术,多模态知识图谱能够更精准地整合不同模态的信息,增强上下文推理能力。
在文本与图像的对齐中,文本通常被转换为词嵌入,图像则通过卷积神经网络(CNN)提取特征,两个模态在统一的向量空间中进行匹配。CLIP 模型是典型的实现,其通过对比学习方法,将文本描述和对应图像映射到同一嵌入空间,从而实现高效的模态对齐。
在视觉问答任务中,注意力机制使模型能够聚焦于与问题相关的图像区域,同时理解问题文本的语义。
基于逐步特征融合的交叉模态对齐框架如下图所示:
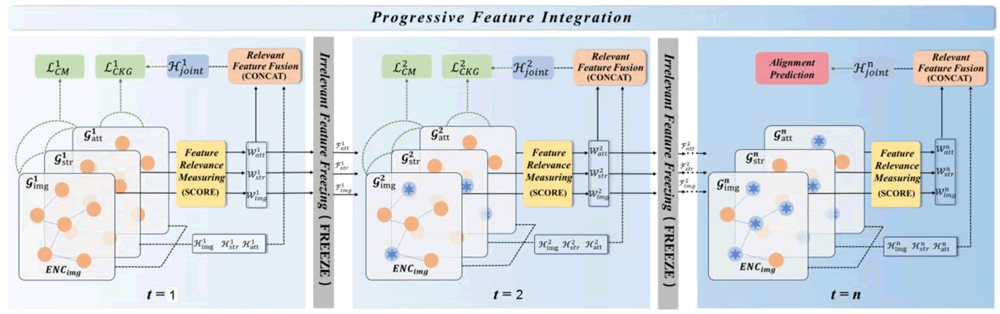
图 2 基于逐步特征融合的交叉模态对齐框架概览
该图展示了逐步特征融合的交叉模态对齐框架(PMF 模型),包括多模态实体编码器、逐步多模态特征融合模块和跨模态对比学习。框架首先通过多模态编码器将来自不同模态的输入数据转换为嵌入表示,确保模态间的特征在同一空间中具备可比较性。在训练过程中,逐步特征融合模块通过筛选相关特征并抑制无关特征,逐步优化模态间的联合表示能力。
该框架的关键技术包括无关特征冻结和相关特征融合,通过相关特征度量模块动态评估特征对任务的贡献,从而实现对模态信息的精准对齐。此外,模型引入跨模态对比学习,进一步强化模态间的语义关联性,确保跨模态特征的一致性和任务相关性。
PMF 模型通过结合逐步优化策略与对比损失函数,实现了不同模态间信息的高效融合,广泛适用于多模态知识图谱、跨模态推荐和复杂语义推理等场景,为复杂任务提供了强大的语义整合能力。
这种方法在视频理解任务中尤为重要,通过对齐视频帧和语音描述,模型可以捕捉时序关系和语义一致性。
模态对齐是多模态学习的基础技术,通过对齐技术,模型能够更好地理解和利用不同模态的信息,为多模态生成、跨模态检索和语义理解等任务提供支持。例如,在智能交互中,模态对齐使得语音助手能够通过语音和视觉信息协同工作,从而提供更精准的响应和反馈。
在多模态知识图谱中,可以通过模态对齐技术区分相关特征与无关特征,如下图所示。
图 1 多模态知识图谱中的相关特征与无关特征对比
多模态知识图谱通过将文本和视觉等模态的信息结合,用于描述实体及其属性,例如电影的名称、导演、演员以及其相关的文本描述和图片特征。
在进行模态对齐过程中,模型需要通过联合建模和语义分析,识别与目标任务相关的模态信息,例如导演和演员的职业与身份,而忽略无关信息,如图片中背景或多余文本内容。
模态对齐的核心在于通过注意力机制或特征对比,优化模态间的语义一致性。例如,在处理视觉与文本数据时,模态对齐模块能够过滤噪声信息,仅提取对于任务有效的模态特征。这种对齐过程不仅提升了知识图谱的准确性,还为多模态任务提供了更高质量的输入数据,广泛应用于推荐系统、问答系统和语义搜索任务中。
通过模态对齐技术,多模态知识图谱能够更精准地整合不同模态的信息,增强上下文推理能力。
模态对齐的实现方法
1) 嵌入表示对齐
嵌入表示对齐是模态对齐的基础方法,通过将不同模态的数据映射到同一语义嵌入空间,使其可以直接进行比较或运算。在文本与图像的对齐中,文本通常被转换为词嵌入,图像则通过卷积神经网络(CNN)提取特征,两个模态在统一的向量空间中进行匹配。CLIP 模型是典型的实现,其通过对比学习方法,将文本描述和对应图像映射到同一嵌入空间,从而实现高效的模态对齐。
2) 注意力机制对齐
注意力机制通过分配权重,突出不同模态中关键部分的信息,从而实现对齐。多头注意力机制在跨模态任务中广泛应用,可以同时关注文本的语义特征和图像的局部区域,建立细粒度的模态关联。在视觉问答任务中,注意力机制使模型能够聚焦于与问题相关的图像区域,同时理解问题文本的语义。
3) 交叉模态对齐
交叉模态对齐通过设计共享的上下文信息,使模态间能够相互作用,提升对齐质量。Transformer 结构的自注意力和交叉注意力模块,能够同时处理来自不同模态的数据,并在联合训练中实现模态间的对齐。基于逐步特征融合的交叉模态对齐框架如下图所示:
图 2 基于逐步特征融合的交叉模态对齐框架概览
该图展示了逐步特征融合的交叉模态对齐框架(PMF 模型),包括多模态实体编码器、逐步多模态特征融合模块和跨模态对比学习。框架首先通过多模态编码器将来自不同模态的输入数据转换为嵌入表示,确保模态间的特征在同一空间中具备可比较性。在训练过程中,逐步特征融合模块通过筛选相关特征并抑制无关特征,逐步优化模态间的联合表示能力。
该框架的关键技术包括无关特征冻结和相关特征融合,通过相关特征度量模块动态评估特征对任务的贡献,从而实现对模态信息的精准对齐。此外,模型引入跨模态对比学习,进一步强化模态间的语义关联性,确保跨模态特征的一致性和任务相关性。
PMF 模型通过结合逐步优化策略与对比损失函数,实现了不同模态间信息的高效融合,广泛适用于多模态知识图谱、跨模态推荐和复杂语义推理等场景,为复杂任务提供了强大的语义整合能力。
这种方法在视频理解任务中尤为重要,通过对齐视频帧和语音描述,模型可以捕捉时序关系和语义一致性。
模态对齐是多模态学习的基础技术,通过对齐技术,模型能够更好地理解和利用不同模态的信息,为多模态生成、跨模态检索和语义理解等任务提供支持。例如,在智能交互中,模态对齐使得语音助手能够通过语音和视觉信息协同工作,从而提供更精准的响应和反馈。
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: