多模态数据到底是什么(新手必看)
多模态数据是指来自不同感知渠道或数据来源的信息集合,这些信息通过不同的模态进行描述,如视觉、语言、音频等,每种模态从特定的角度反映事物的特征。
多模态数据的本质在于模态间的互补性,各模态通过结合能够提供更全面的上下文信息,从而提升对复杂问题的理解和处理能力。
例如,照片能够描述静态的场景特征,而视频能够记录动态变化,视觉模态数据通常具有高维度特性和丰富的细节信息。
例如,海浪的声音、交通噪声等。音频模态能够提供特定场景的背景信息,进一步丰富其他模态的数据表现形式。
例如,用于医疗检测的传感器信号数据,或用于自动驾驶的激光雷达点云信息。
例如,视觉模态是像素空间的数据,而文本模态是离散的单词或句子,两种模态的数据表达形式和维度完全不同,导致多模态数据的融合需要特别的建模技术。
基于多模态数据的医学影像分析如图1-1所示,图中将多模态影像数据序列化为统一格式以便于联合建模。
多模态在医学影像分析中的具体应用如下:
1) 首先,针对不同模态的医学影像数据(如 CT、MRI 等),我们需要进行预处理和标准化处理,提取其空间特征,并将其进行分块序列化。这些分块作为输入序列被送入深度学习模型。
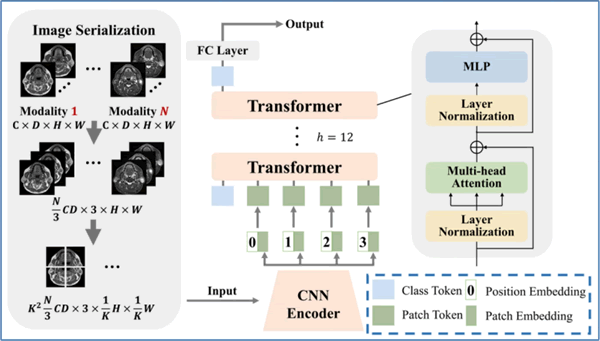
图 1 多模态医学影像分析
上图中展示了 CNN 编码器有效提取了影像数据的局部特征,通过层级结构生成丰富的空间表示,这些特征随后被转换为序列输入形式。
接着,Transformer 模块采用多头注意力机制,对序列化的影像块特征进行建模,从而捕捉不同模态之间的长距离依赖关系和全局语义信息。在此过程中,特定的分类标签和位置编码被整合到输入序列中,以增强模型对序列结构和全局任务目标的理解能力。
最后,通过全连接层和多层感知机(MLP),模型将融合的多模态特征应用于分类、分割或疾病预测等任务。该架构充分发挥了不同模态医学影像的互补优势,提高了对复杂病理特征的识别能力,成为多模态数据在医疗影像分析领域的关键技术手段。

图 2 自动驾驶场景中多模态数据的综合处理与预测
如图 2 所示,该图展示了自动驾驶场景中多模态数据的综合处理与预测。通过融合视觉模态的目标检测、轨迹预测和场景分割,模型能够精准识别交通信号、行人以及车辆位置,并基于多模态信息生成符合交通指令的行驶路径。多头注意力机制和序列建模方法用于捕捉时序动态特性与环境上下文,从而实现路径规划与实时响应。
多模态数据的种类与特点为多模态学习奠定了基础,理解其本质有助于更高效地利用这些数据提升人工智能系统的性能,多模态数据的种类与特点对比如下表所示。
多模态数据的本质在于模态间的互补性,各模态通过结合能够提供更全面的上下文信息,从而提升对复杂问题的理解和处理能力。
常见的多模态数据种类
1)视觉模态
主要包括图像、视频等形式,用于捕捉场景、物体、动作等信息。例如,照片能够描述静态的场景特征,而视频能够记录动态变化,视觉模态数据通常具有高维度特性和丰富的细节信息。
2) 语言模态
主要以文本或语音的形式呈现,描述事物的逻辑关系与语义信息:- 文本模态如文章、对话,具有逻辑性和结构性;
- 语音模态则通过声调和节奏传递情感与语义,能够补充文本模态中缺失的情绪维度。
3) 音频模态
通常包括环境声音、音乐或其他非语言类的声波信息。例如,海浪的声音、交通噪声等。音频模态能够提供特定场景的背景信息,进一步丰富其他模态的数据表现形式。
4) 感官模态
由传感器设备收集的触觉、温度、位置信息等非传统模态。例如,用于医疗检测的传感器信号数据,或用于自动驾驶的激光雷达点云信息。
多模态数据的特点
1) 高维度与异质性
多模态数据来自不同模态,具有天然的异质性。例如,视觉模态是像素空间的数据,而文本模态是离散的单词或句子,两种模态的数据表达形式和维度完全不同,导致多模态数据的融合需要特别的建模技术。
2) 冗余与互补性
多模态数据中可能存在信息冗余,例如同一事件可能被文字和图像同时描述,而冗余信息可以提高任务的鲁棒性;同时,不同模态间也具有互补性,例如语音中的情感信息可以补充文本模态无法直接表达的情绪。3) 动态性与时序特性
某些多模态数据具有时间维度的动态性,例如视频和语音数据都随着时间变化而更新,时序特性使得分析这些数据需要考虑模态内及模态间的时间同步。4) 跨模态相关性
多模态数据间通常存在相关性,例如视频中的某一场景和描述该场景的文本字幕是互相关联的,如何在模态间发现并利用这些相关性是多模态学习的核心难题。多模态数据的应用场景
多模态数据在许多领域中展现了独特的价值:- 医学影像分析:结合CT扫描的图像数据与医生的文字诊断记录,能够提高疾病诊断的准确性;
- 自动驾驶:通过融合摄像头的视觉数据与激光雷达的点云数据,自动驾驶系统能够更准确地感知环境并做出决策;
- 人机交互:在智能语音助手中,结合语音、文本与表情识别等模态,能够实现更自然的交互体验。
基于多模态数据的医学影像分析如图1-1所示,图中将多模态影像数据序列化为统一格式以便于联合建模。
多模态在医学影像分析中的具体应用如下:
1) 首先,针对不同模态的医学影像数据(如 CT、MRI 等),我们需要进行预处理和标准化处理,提取其空间特征,并将其进行分块序列化。这些分块作为输入序列被送入深度学习模型。
图 1 多模态医学影像分析
上图中展示了 CNN 编码器有效提取了影像数据的局部特征,通过层级结构生成丰富的空间表示,这些特征随后被转换为序列输入形式。
接着,Transformer 模块采用多头注意力机制,对序列化的影像块特征进行建模,从而捕捉不同模态之间的长距离依赖关系和全局语义信息。在此过程中,特定的分类标签和位置编码被整合到输入序列中,以增强模型对序列结构和全局任务目标的理解能力。
最后,通过全连接层和多层感知机(MLP),模型将融合的多模态特征应用于分类、分割或疾病预测等任务。该架构充分发挥了不同模态医学影像的互补优势,提高了对复杂病理特征的识别能力,成为多模态数据在医疗影像分析领域的关键技术手段。
多模态数据的技术挑战
尽管多模态数据具有极大的潜力,但在处理和建模方面仍然面临许多技术挑战:- 模态对齐:不同模态的数据通常具有不同的时间或空间分辨率,例如视频的帧速率可能与文本的时间标签不一致,对齐这些数据需要精确的同步机制;
- 融合策略:如何选择合适的方式将多模态数据融合为统一的表示,是当前研究的重点方向;
- 数据缺失问题:某些模态可能由于采集条件的限制而存在数据缺失,这需要通过补全算法或基于其他模态的推断技术解决。
图 2 自动驾驶场景中多模态数据的综合处理与预测
如图 2 所示,该图展示了自动驾驶场景中多模态数据的综合处理与预测。通过融合视觉模态的目标检测、轨迹预测和场景分割,模型能够精准识别交通信号、行人以及车辆位置,并基于多模态信息生成符合交通指令的行驶路径。多头注意力机制和序列建模方法用于捕捉时序动态特性与环境上下文,从而实现路径规划与实时响应。
多模态数据的种类与特点为多模态学习奠定了基础,理解其本质有助于更高效地利用这些数据提升人工智能系统的性能,多模态数据的种类与特点对比如下表所示。
| 种类 | 特点 | 示例 |
|---|---|---|
| 视觉模态 | 高维度、细节丰富 | 图像、视频 |
| 语言模态 | 逻辑性强、包含语义与结构 | 文本、语音 |
| 音频模态 | 表现背景信息、节奏与音调 | 环境音、音乐 |
| 感官模态 | 离散或连续信号、多样化 | 温度、触觉、位置数据 |
| 多模态冗余性 | 信息重复,提高鲁棒性 | 图像与描述性文字的冗余信息 |
| 模态互补性 | 多模态信息互补 | 视频补充语音无法传递的场景 |
| 动态性 | 随时间变化,时序数据 | 视频帧、语音流 |
| 跨模态相关性 | 模态间具有内在联系 | 图像与文字描述的语义一致 |
| 数据异质性 | 表达形式差异大,融合难度高 | 像素数组和文本单词嵌入 |
| 数据缺失问题 | 某模态缺失需推断补全 | 未记录的语音或缺损的图像片段 |
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: