大模型是什么(非常全面)
以 ChatGPT 为代表的大型语言模型(Large Language Models,LLM)带来的智能涌现(Emergence),不仅推动了人工智能技术的显著进步,也加速了其发展。大模型技术已经成为 AI(人工智能)领域的前沿热点,引起了全球范围内的广泛关注和讨论,成为科技竞争的关键领域。
大型语言模型简称大模型,是 NLP 的一个重要分支和应用。NLP(Natural Language Processing,自然语言处理),作为计算机科学和 AI(人工智能)领域中的一个核心方向,专注于利用计算机技术来分析、理解和处理自然语言。
NLP 的核心任务是将计算机作为语言研究的强大工具,不仅在计算机的支持下对语言信息进行定量化研究,还致力于提供一种人与计算机之间能够共同使用的语言描述。这种描述不仅有助于机器更好地理解人类的语言,也为人类提供了一种与机器交流的方式。
NLP 主要包含两部分:NLU(Natural Language Understanding,自然语言理解)和 NLG(Natural Language Generation,自然语言生成)。NLU 的目标是使计算机能够理解自然语言文本的含义,而 NLG 则致力于使计算机能够以自然语言的形式表达深层的意图和思想。
尽管 NLU 和 NLG 面临的挑战巨大,但随着技术的进步,已经有一些实用的系统被开发出来,并在某些领域实现了商品化和产业化。这些应用包括多语种数据库和专家系统的自然语言接口、机器翻译系统、全文信息检索系统和自动文摘系统等。然而,开发出通用的、高质量的自然语言处理系统,仍然是一个长期且具有挑战性的目标。
本质上,大模型是一种深度神经网络模型,通常由数十亿个权重或数千亿个参数组成。以 ChatGPT 为例,其当前模型由 1750 亿个浮点数参数构成,是一个高度复杂的对话式 AI 系统。
大模型主要通过自监督学习(Self-Supervised Learning)或半监督学习(Semi-Supervised Learning)进行训练,利用预训练任务从大规模的无监督数据中挖掘自身的监督信息(用于训练模型的数据,不仅包含输入特征,还包含对应的输出标签或结果)。
通过这种方式,模型能够学习到对特定领域有价值的表征(模型将输入数据转换成数学上的向量形式,以方便计算和分析)。在海量信息的参数化全量记忆、任意任务的对话式理解、复杂逻辑的思维链推理、多角色多风格长文本生成、程序代码生成和输入图像的语义层理解等方面,大模型实现了显著的突破,体现了语言智能的“智能涌现”。
智能涌现是指当模型的规模和训练数据量达到一定水平时,模型会展现出一些新的、更高级的技能,这可以被看作一种“量变引起质变”的现象。实验已经证明,针对相对复杂任务的智能涌现对模型的大小(如 100 亿个参数)是有要求的。智能涌现的通用AI系统在广泛的自然语言任务中展现出卓越的性能。
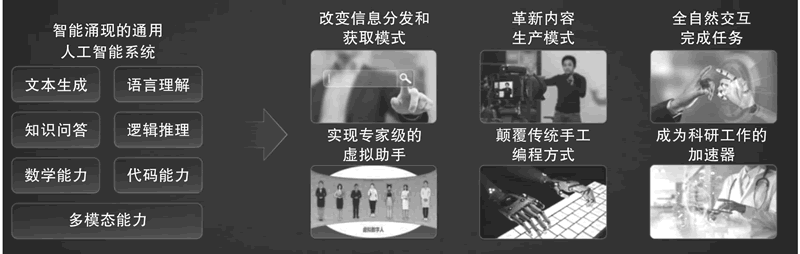
图 1 大模型的“智能涌现”解决人类刚需
上图所示的具有多模态能力的“智能涌现”的通用 AI 系统,不仅改变了信息的分发和获取模式,还革新了内容生产方式,实现了全自然交互完成任务,提供了专家级的虚拟助手,颠覆了传统的手工编程方式,成为科研工作的加速器。这些进步为解决人类的基本需求带来了全新的机遇。
如下图所示,AI的发展经历了一个螺旋式上升的过程:
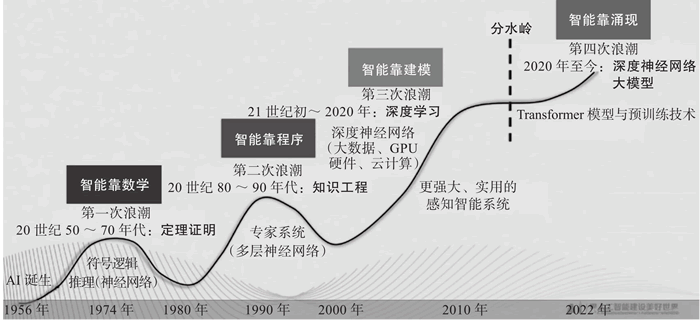
图 2 AI 的四次浪潮
自 1956 年达特茅斯会议上首次提出 AI 概念以来,AI 技术经历了多个重要阶段:
这一演进不仅标志着 AI 技术的进步,也预示着我们可能正在接近通用 AI。
大模型的智能涌现预示着机器将能够真正掌握并运用人类语言和知识,开启一种“类人”的自然语言交互式学习新范式。这种以语言智能为核心的突破,标志着机器智能进入了一个全新的发展阶段。
作为人工智能迈向通用智能的关键技术,大模型在“大数据、大算力和强算法”的支持下,通过在海量数据上进行预训练,以及提示工程(Prompt Engineering)或模型微调(在有标注数据的特定领域任务上进行二次训练),能够完成多种应用场景的任务,展现出完成通用任务的潜力。
大模型的学习和发展过程与人类的成长过程有着惊人的相似之处。人类的成长需要广泛的阅读、丰富的实践和深入的交流,而大模型则需要大规模的数据输入、模型预训练和微调迭代。人类的基础教育和大学教育相当于大模型的预训练阶段,而研究生学习和职业学习则相当于大模型的微调迭代和强化领域技能。此外,大模型的模型对齐过程,实际上也是在模仿人类遵守法律和道德规范的过程。
大型语言模型简称大模型,是 NLP 的一个重要分支和应用。NLP(Natural Language Processing,自然语言处理),作为计算机科学和 AI(人工智能)领域中的一个核心方向,专注于利用计算机技术来分析、理解和处理自然语言。
NLP 的核心任务是将计算机作为语言研究的强大工具,不仅在计算机的支持下对语言信息进行定量化研究,还致力于提供一种人与计算机之间能够共同使用的语言描述。这种描述不仅有助于机器更好地理解人类的语言,也为人类提供了一种与机器交流的方式。
NLP 主要包含两部分:NLU(Natural Language Understanding,自然语言理解)和 NLG(Natural Language Generation,自然语言生成)。NLU 的目标是使计算机能够理解自然语言文本的含义,而 NLG 则致力于使计算机能够以自然语言的形式表达深层的意图和思想。
尽管 NLU 和 NLG 面临的挑战巨大,但随着技术的进步,已经有一些实用的系统被开发出来,并在某些领域实现了商品化和产业化。这些应用包括多语种数据库和专家系统的自然语言接口、机器翻译系统、全文信息检索系统和自动文摘系统等。然而,开发出通用的、高质量的自然语言处理系统,仍然是一个长期且具有挑战性的目标。
本质上,大模型是一种深度神经网络模型,通常由数十亿个权重或数千亿个参数组成。以 ChatGPT 为例,其当前模型由 1750 亿个浮点数参数构成,是一个高度复杂的对话式 AI 系统。
大模型主要通过自监督学习(Self-Supervised Learning)或半监督学习(Semi-Supervised Learning)进行训练,利用预训练任务从大规模的无监督数据中挖掘自身的监督信息(用于训练模型的数据,不仅包含输入特征,还包含对应的输出标签或结果)。
通过这种方式,模型能够学习到对特定领域有价值的表征(模型将输入数据转换成数学上的向量形式,以方便计算和分析)。在海量信息的参数化全量记忆、任意任务的对话式理解、复杂逻辑的思维链推理、多角色多风格长文本生成、程序代码生成和输入图像的语义层理解等方面,大模型实现了显著的突破,体现了语言智能的“智能涌现”。
智能涌现是指当模型的规模和训练数据量达到一定水平时,模型会展现出一些新的、更高级的技能,这可以被看作一种“量变引起质变”的现象。实验已经证明,针对相对复杂任务的智能涌现对模型的大小(如 100 亿个参数)是有要求的。智能涌现的通用AI系统在广泛的自然语言任务中展现出卓越的性能。
图 1 大模型的“智能涌现”解决人类刚需
上图所示的具有多模态能力的“智能涌现”的通用 AI 系统,不仅改变了信息的分发和获取模式,还革新了内容生产方式,实现了全自然交互完成任务,提供了专家级的虚拟助手,颠覆了传统的手工编程方式,成为科研工作的加速器。这些进步为解决人类的基本需求带来了全新的机遇。
如下图所示,AI的发展经历了一个螺旋式上升的过程:
图 2 AI 的四次浪潮
自 1956 年达特茅斯会议上首次提出 AI 概念以来,AI 技术经历了多个重要阶段:
- 20世纪50~20世纪70年代:AI 的早期发展阶段,研究方向集中在符号逻辑推理上。
- 20世纪80年代至90年代:知识工程成为AI领域的主要研究方向,强调知识库的构建和应用,即引入专家系统。
- 21世纪初~2020年:深度学习技术的兴起,极大地推动了 AI 在图像识别、语音识别等领域的应用。
- 2020 年至今:深度神经网络大模型的发展,使得 AI 从简单的预测推断向复杂的内容生成迈进,从专用任务向通用任务扩展,并逐步替代从低端重复性工作到高端脑力劳动的各种任务。
这一演进不仅标志着 AI 技术的进步,也预示着我们可能正在接近通用 AI。
大模型的智能涌现预示着机器将能够真正掌握并运用人类语言和知识,开启一种“类人”的自然语言交互式学习新范式。这种以语言智能为核心的突破,标志着机器智能进入了一个全新的发展阶段。
作为人工智能迈向通用智能的关键技术,大模型在“大数据、大算力和强算法”的支持下,通过在海量数据上进行预训练,以及提示工程(Prompt Engineering)或模型微调(在有标注数据的特定领域任务上进行二次训练),能够完成多种应用场景的任务,展现出完成通用任务的潜力。
大模型的学习和发展过程与人类的成长过程有着惊人的相似之处。人类的成长需要广泛的阅读、丰富的实践和深入的交流,而大模型则需要大规模的数据输入、模型预训练和微调迭代。人类的基础教育和大学教育相当于大模型的预训练阶段,而研究生学习和职业学习则相当于大模型的微调迭代和强化领域技能。此外,大模型的模型对齐过程,实际上也是在模仿人类遵守法律和道德规范的过程。
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: