C++中的for_each()算法(新手必看)
C++ 容器中保存的大量数据通常需要逐个处理。for_each算法,顾名思义就是用来遍历容器并对每个元素执行操作,非常适合完成这类任务。
读者可能会有这样的疑问,为何不直接使用常规的 for 循环来遍历容器?for_each 算法的优势不仅在于遍历容器的每个元素,更在于它能够在遍历的同时,将自定义操作应用于每个元素,直接处理容器中的多个元素。这种灵活性使得 for_each 算法成为一个强大的工具。
在 STL 中,for_each() 算法的原型如下:
STL 中的算法本质上是一系列函数模板,for_each() 算法正是其中之一。for_each() 算法能够接受三个参数:
例如,假设公司今年的业绩非常好,老板决定给所有工资低于 2000 元的员工增加 30% 的工资。使用 for_each 算法,我们可以高效地实现这一操作:
当然,我们也可以根据需要改变这个范围,只对某个特定范围内的数据进行处理。这里我们对数据的处理是通过 AddSalary() 函数来表达的,AddSalary() 函数的函数名作为 for_each() 算法的第三个参数,这意味着在它的处理范围内的数据元素都要经过 AddSalary() 函数的处理。
在执行过程中,for_each() 算法会逐个遍历整个范围内的所有数据元素,并以这些元素为实际参数调用处理函数 AddSalary()。换句话说,处理范围内的数据会逐个被传入 AddSalary() 函数,而该函数具体负责对数据的处理,它会先判断数据是否满足增加工资的条件,如果满足,则增加 30%。
需要注意的是,AddSalary() 函数的参数是引用形式,因此在 AddSalary() 函数中对参数的修改实际上会修改容器中的数据,这些修改都会反映到容器中。如果这里的参数是值的形式,那么 AddSalary() 函数的参数只是容器中数据的一个副本,在函数中对参数的修改将不会反映到容器中。
for_each() 算法对数据的处理如下图所示:
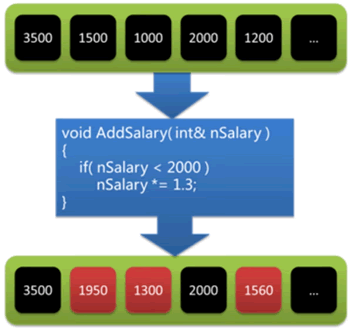
图 1 for_each()算法对数据的处理
更形象地讲,for_each() 算法更像是做化学实验时的漏斗装置,可以通过指定容器的范围来决定往这个漏斗中倒入什么数据。而 for_each() 算法中的处理函数是具体的漏斗,它决定了什么东西可以留下,什么东西可以漏掉,以此来完成对倒入漏斗中的数据的具体处理。进一步讲,还可以随时更换 for_each() 算法中的漏斗,以对数据进行不同的处理,这体现了 STL 中算法的通用性。
读者可能会有这样的疑问,为何不直接使用常规的 for 循环来遍历容器?for_each 算法的优势不仅在于遍历容器的每个元素,更在于它能够在遍历的同时,将自定义操作应用于每个元素,直接处理容器中的多个元素。这种灵活性使得 for_each 算法成为一个强大的工具。
在 STL 中,for_each() 算法的原型如下:
template <class InputIterator, class Function> Function for_each (InputIterator first, InputIterator last, Function f);for_each() 算法声明在
<algorithm>头文件中,使用前必须包含这个头文件,同时指明 std 命名空间。STL 中的算法本质上是一系列函数模板,for_each() 算法正是其中之一。for_each() 算法能够接受三个参数:
- 前两个参数是迭代器,分别定义了待处理数据在容器中的起始和终止位置;
- 第三个参数指定了应用于该范围内数据的处理方法。这个方法可以是普通函数、函数对象,甚至是 Lambda 表达式。无论其具体形式如何,该方法必须能接受一个参数,且该参数的类型应与容器中存储的数据类型相匹配。
例如,假设公司今年的业绩非常好,老板决定给所有工资低于 2000 元的员工增加 30% 的工资。使用 for_each 算法,我们可以高效地实现这一操作:
// 利用函数定义对数据的处理方法,对于低于 2000 元的工资,增加 30%
// 函数只有一个参数,其类型是它将要处理的 vector 容器保存数据的类型
// 因为要对容器中的数据进行修改,所以这里采用引用的参数形式
void AddSalary( int& nSalary )
{
// 判断数据是否满足条件
if( nSalary < 2000 )
nSalary *= 1.3; // 对数据进行处理
}
// 构造容器,保存数据
vector<int> vecSalary = {3500,1500,1000,2000,1200};
// 使用 for_each() 算法,调用 AddSalary() 函数对容器中的数据进行处理
for_each( vecSalary.begin(), // 开始位置
vecSalary.end(), // 结束位置
AddSalary ); // 处理方法
在这段代码中,我们调用 begin() 和 end() 函数获得指向 vecSalary 容器起止位置的迭代器,以作为 for_each() 算法的处理数据范围,这就意味着 for_each() 算法会将其处理方法应用于这个范围内的每一个数据。当然,我们也可以根据需要改变这个范围,只对某个特定范围内的数据进行处理。这里我们对数据的处理是通过 AddSalary() 函数来表达的,AddSalary() 函数的函数名作为 for_each() 算法的第三个参数,这意味着在它的处理范围内的数据元素都要经过 AddSalary() 函数的处理。
在执行过程中,for_each() 算法会逐个遍历整个范围内的所有数据元素,并以这些元素为实际参数调用处理函数 AddSalary()。换句话说,处理范围内的数据会逐个被传入 AddSalary() 函数,而该函数具体负责对数据的处理,它会先判断数据是否满足增加工资的条件,如果满足,则增加 30%。
需要注意的是,AddSalary() 函数的参数是引用形式,因此在 AddSalary() 函数中对参数的修改实际上会修改容器中的数据,这些修改都会反映到容器中。如果这里的参数是值的形式,那么 AddSalary() 函数的参数只是容器中数据的一个副本,在函数中对参数的修改将不会反映到容器中。
for_each() 算法对数据的处理如下图所示:
图 1 for_each()算法对数据的处理
更形象地讲,for_each() 算法更像是做化学实验时的漏斗装置,可以通过指定容器的范围来决定往这个漏斗中倒入什么数据。而 for_each() 算法中的处理函数是具体的漏斗,它决定了什么东西可以留下,什么东西可以漏掉,以此来完成对倒入漏斗中的数据的具体处理。进一步讲,还可以随时更换 for_each() 算法中的漏斗,以对数据进行不同的处理,这体现了 STL 中算法的通用性。
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: