C++中的右值引用(非常详细,附带实例)
在性能方面,C++ 被认为是继汇编语言和 C语言之后,性能表现最出色的高级程序设计语言之一。然而,C++ 标准委员会的专家们并不满足于此,他们在 C++ 的最新标准中引入了右值引用这一创新特性,旨在进一步提升 C++ 的性能表现。
确实,在 C++ 语言中,根据是否可以出现在赋值操作符“=”的左侧或右侧,数值或变量被分为左值和右值。
通常,我们称那些可以出现在等号左侧的数值为左值,例如变量,不仅可以在左侧接收赋值,也可以在右侧为其他左值提供值。而那些仅能出现在等号右侧的数值则被称为右值。
例如,数字常量就只能在右侧为其他左值提供值,而不能在左侧接收赋值。在 C++ 中,右值主要包括字面量(如1、3.14等)和匿名对象(如函数的返回值、构造函数生成的对象等)。
右值引用,顾名思义,是与右值相关联的引用类型。在 C++ 中,通过在数据类型后添加“&&”符号来定义一个相应类型的右值引用。
例如,如果我们定义了一个 int&& 类型的变量,它就是一个右值引用。对应地,使用单个“&”符号定义的引用被称为左值引用,简称引用。例如:
具体来说,左值引用必须绑定到左值上,而右值引用则专门用于绑定到右值上。如果违反这一规则,例如尝试将左值引用绑定到右值,或者将右值引用绑定到左值,将会导致编译错误。例如:
关联完成之后,左值引用和右值引用都可以像普通数据变量一样进行左右值的操作了。例如:
当一个函数执行完毕后,这些没有被赋予变量名的返回值通常会被赋值给等号左边的左值变量。在没有引入右值引用的 C++ 时代,这个过程实际上相当消耗性能且浪费资源。
首先,需要释放左值变量原有的内存资源,接着根据返回值的大小重新申请内存资源,然后,将返回值的数据复制到左值变量新申请的内存中,最后还要释放掉返回值的内存资源。这个过程需要经过四个步骤,才能完成一个函数返回值的赋值操作。
这种烦琐的过程不仅会消耗性能,并且对于仅作为中间过渡的返回值来说,还会浪费宝贵的内存资源。
下面来看一个实际的例子,用 CreateBlock() 函数创建一个用于管理内存的 MemoryBlock 对象,并将其保存到另一个 MemoryBlock 类型变量中:
从程序的输出中,我们可以清晰地观察到这四个步骤:
C++ 的最新标准引入右值引用,正是为了解决这一性能瓶颈。
函数的返回值本质上是一个右值。通过在 MemoryBlock 类中提供可以接受右值引用作为参数的移动构造函数和移动赋值操作符,我们可以直接利用这个右值来初始化或赋值给 block 变量:
既然这个右值对象即将被销毁,我们同时又要创建或者复制一个与之完全相同的对象,那么自然会想到“废物再利用”,直接用这个即将被销毁的右值对象作为我们想要创建或复制的目标对象。内存资源依旧是那块内存资源,只不过其管理者由原来的作为参数的右值对象转换为我们想要创建或复制的目标对象。
整个过程如下图所示:
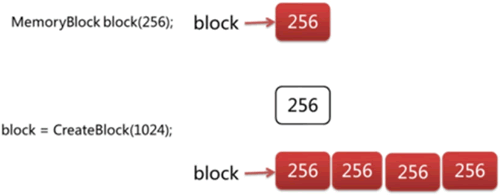
图 1 从函数返回值赋值
在这个过程中,没有内存资源的重新申请和释放,也没有数据的复制,整个过程就像一场和平友好的内存资源管理权移交仪式。目标对象的内存指针简单地指向右值对象的内存资源,从而将内存资源的管理权从右值对象移交(move)到目标对象,以这种“低碳环保”的方式轻松地完成了目标对象的创建或者赋值。
因此,为了与传统的接收左值引用(&)为参数的构造函数和赋值操作符区分开来,接收右值引用(&&)为参数的构造函数被称为移动构造函数,而相应的赋值操作符也被称为移动赋值操作符。
从程序的输出中,我们可以看到这个“移交”的过程非常简单:
在 C++ 标准库中,例如 vector 容器,已经利用右值引用进行了优化,我们可以直接利用这些特性,享受其带来的性能提升。
对于我们自己创建的类,如果它们可能会作为函数的返回值并被赋值给其他左值对象,提供移动构造函数和移动赋值操作符将允许我们重新利用原本可能被丢弃的右值,从而在一定程度上提高程序的性能。
C++右值引用的基本用法
在之前的程序中,我们通常处理的是常量,如具体的数字或字符串,或者是特定类型的变量。但可能有人对右值这一概念感到陌生。数值真的可以区分为左值和右值吗?这里的右值和右值引用又是指什么呢?确实,在 C++ 语言中,根据是否可以出现在赋值操作符“=”的左侧或右侧,数值或变量被分为左值和右值。
通常,我们称那些可以出现在等号左侧的数值为左值,例如变量,不仅可以在左侧接收赋值,也可以在右侧为其他左值提供值。而那些仅能出现在等号右侧的数值则被称为右值。
例如,数字常量就只能在右侧为其他左值提供值,而不能在左侧接收赋值。在 C++ 中,右值主要包括字面量(如1、3.14等)和匿名对象(如函数的返回值、构造函数生成的对象等)。
右值引用,顾名思义,是与右值相关联的引用类型。在 C++ 中,通过在数据类型后添加“&&”符号来定义一个相应类型的右值引用。
例如,如果我们定义了一个 int&& 类型的变量,它就是一个右值引用。对应地,使用单个“&”符号定义的引用被称为左值引用,简称引用。例如:
// 定义一个 int 类型的变量,这个变量可以放在等号左边被赋值 // 所以是一个左值 int nInt = 1; // 定义一个左值引用,将它指向一个左值 int& lrefInt = nInt; // 定义一个右值引用,将它指向一个直接使用构造函数创建的右值 int(0) int&& rrefInt = int(0); // 显然,我们无法将它放在等号左边对它赋值 int(0) = 1; // 错误我们知道,引用本质上是某个已存在变量的别名。引用本身并不独立存在,总是与一个特定的变量绑定。这里需要明确区分左值引用和右值引用,它们与变量的关联是一对一且具有特定性的。
具体来说,左值引用必须绑定到左值上,而右值引用则专门用于绑定到右值上。如果违反这一规则,例如尝试将左值引用绑定到右值,或者将右值引用绑定到左值,将会导致编译错误。例如:
// 正确:左值引用 lrefInt1 关联到左值变量 nInt int& lrefInt1 = nInt; // 错误:左值引用 lrefInt2 不可以关联到右值 int(0) int& lrefInt2 = int(0); // 正确:右值引用 rrefInt1 关联到右值 int(0) int&& rrefInt1 = int(0); // 错误:右值引用 rrefInt2 不可以关联到左值 nInt int&& rrefInt2 = nInt;
关联完成之后,左值引用和右值引用都可以像普通数据变量一样进行左右值的操作了。例如:
// 对右值引用 rrefInt1 赋值 rrefInt1 = 1; // 利用右值引用对左值引用赋值 lrefInt1 = rrefInt1;
C++右值引用是如何提高性能的
在 C++ 中,最常见的右值之一是函数(包括普通函数和构造函数)的返回值。当一个函数执行完毕后,这些没有被赋予变量名的返回值通常会被赋值给等号左边的左值变量。在没有引入右值引用的 C++ 时代,这个过程实际上相当消耗性能且浪费资源。
首先,需要释放左值变量原有的内存资源,接着根据返回值的大小重新申请内存资源,然后,将返回值的数据复制到左值变量新申请的内存中,最后还要释放掉返回值的内存资源。这个过程需要经过四个步骤,才能完成一个函数返回值的赋值操作。
这种烦琐的过程不仅会消耗性能,并且对于仅作为中间过渡的返回值来说,还会浪费宝贵的内存资源。
下面来看一个实际的例子,用 CreateBlock() 函数创建一个用于管理内存的 MemoryBlock 对象,并将其保存到另一个 MemoryBlock 类型变量中:
#include <iostream>
#include <cstring> // 为了使用内存复制函数 memcpy()
using namespace std;
// 用于管理内存的类
class MemoryBlock
{
public:
// 构造函数,根据参数申请相应大小的内存资源
MemoryBlock(const unsigned int nSize)
{
cout << "创建对象,申请内存资源" << nSize << "字节" << endl;
m_nSize = nSize;
m_pData = new char[nSize];
}
// 析构函数,释放管理的内存资源
~MemoryBlock()
{
cout << "销毁对象";
if (0 != m_nSize) // 如果拥有内存资源
{
cout << ",释放内存资源" << m_nSize << "字节";
delete[] m_pData; // 释放内存资源
m_nSize = 0;
}
cout << endl;
}
// 赋值操作符,完成对象的复制
// 这里的参数是一个左值引用
MemoryBlock& operator = (const MemoryBlock& other)
{
// 判断是否自己给自己赋值
if (this == &other)
return *this;
// 第一步,释放已有内存资源
cout << "释放已有内存资源" << m_nSize << "字节" << endl;
delete[] m_pData;
// 第二步,根据赋值对象的大小重新申请内存资源
m_nSize = other.GetSize();
cout << "重新申请内存资源" << m_nSize << "字节" << endl;
m_pData = new char[m_nSize];
// 第三步,复制数据
cout << "复制数据" << m_nSize << "字节" << endl;
memcpy(m_pData, other.GetData(), m_nSize);
return *this;
}
public:
// 获取相关数据的成员函数
unsigned int GetSize() const
{
return m_nSize;
}
char* GetData() const
{
return m_pData;
}
private:
unsigned int m_nSize = 0; // 内存块的大小
char* m_pData = nullptr; // 指向内存块的指针
};
// 根据大小创建相应的 MemoryBlock 对象
MemoryBlock CreateBlock(const unsigned int nSize)
{
// 创建相应大小的对象
MemoryBlock mem(nSize);
// 给内存中填满字符'A'
memset(mem.GetData(), 'A', mem.GetSize());
// 返回创建的对象
return mem;
}
int main()
{
// 用于保存函数返回值的 block 变量
MemoryBlock block(256);
// 用函数创建特定大小的 MemoryBlock 对象
block = CreateBlock(1024);
cout << "创建的对象大小是"
<< block.GetSize() << "字节" << endl;
return 0;
}
在这段代码中,我们通过调用 CreateBlock() 函数创建了一个具有特定大小的 MemoryBlock 对象,并将其存储在局部变量 block 中。从表面上看,这是一个非常简单的操作,但实际上,程序在背后经历了一系列复杂的步骤才完成了这一操作。从程序的输出中,我们可以清晰地观察到这四个步骤:
创建对象,申请内存资源 256 字节 创建对象,申请内存资源 1024 字节 释放已有内存资源 256 字节 <- 第一步 重新申请内存资源 1024 字节 <- 第二步 复制数据 1024 字节 <- 第三步 销毁对象,释放内存资源 1024 字节 <- 第四步 创建的对象大小是 1024 字节 销毁对象,释放内存资源 1024 字节保存函数返回值这一看似简单的操作,在 C++ 程序中实际上是一个相对复杂的过程,尤其是考虑到这类操作的普遍性。更关键的是,这些步骤大多涉及耗时的内存操作,如内存申请、数据复制和内存释放。因此,这一动作的性能往往不尽如人意。
C++ 的最新标准引入右值引用,正是为了解决这一性能瓶颈。
函数的返回值本质上是一个右值。通过在 MemoryBlock 类中提供可以接受右值引用作为参数的移动构造函数和移动赋值操作符,我们可以直接利用这个右值来初始化或赋值给 block 变量:
// 用于管理内存的类
class MemoryBlock
{
// ...
public:
// 可以接收右值引用为参数的移动构造函数
MemoryBlock(MemoryBlock&& other)
{
cout << "移动资源" << other.m_nSize << "字节" << endl;
// 将目标对象的内存资源指针直接指向源对象的内存资源
// 表示将源对象内存资源的管理权移交给目标对象
m_pData = other.m_pData;
m_nSize = other.m_nSize; // 复制相应的内存块大小
// 将源对象的内存资源指针设置为 nullptr
// 表示这块内存资源已经归目标对象所有
// 源对象不再拥有其管理权
other.m_pData = nullptr;
other.m_nSize = 0; // 内存块大小设置为 0
}
// 可以接收右值引用为参数的赋值操作符
MemoryBlock& operator = (MemoryBlock&& other)
{
// 第一步,释放已有内存资源
cout << "释放已有资源" << m_nSize << "字节" << endl;
delete[] m_pData;
// 第二步,移动资源,也就是移交内存资源的管理权
cout << "移动资源" << other.m_nSize << "字节" << endl;
m_pData = other.m_pData;
m_nSize = other.m_nSize;
// 源对象不再拥有资源的管理权
other.m_pData = nullptr;
other.m_nSize = 0;
return *this;
}
// ...
};
从上述代码中可以看到,这里的移动构造函数和赋值操作符都以一个右值引用为参数。这意味着这个参数所关联的右值对象在函数调用完成后将被销毁,其管理的内存资源也会被释放。既然这个右值对象即将被销毁,我们同时又要创建或者复制一个与之完全相同的对象,那么自然会想到“废物再利用”,直接用这个即将被销毁的右值对象作为我们想要创建或复制的目标对象。内存资源依旧是那块内存资源,只不过其管理者由原来的作为参数的右值对象转换为我们想要创建或复制的目标对象。
整个过程如下图所示:
图 1 从函数返回值赋值
在这个过程中,没有内存资源的重新申请和释放,也没有数据的复制,整个过程就像一场和平友好的内存资源管理权移交仪式。目标对象的内存指针简单地指向右值对象的内存资源,从而将内存资源的管理权从右值对象移交(move)到目标对象,以这种“低碳环保”的方式轻松地完成了目标对象的创建或者赋值。
因此,为了与传统的接收左值引用(&)为参数的构造函数和赋值操作符区分开来,接收右值引用(&&)为参数的构造函数被称为移动构造函数,而相应的赋值操作符也被称为移动赋值操作符。
从程序的输出中,我们可以看到这个“移交”的过程非常简单:
创建对象,申请内存资源 256 字节 创建对象,申请内存资源 1024 字节 释放已有资源 256 字节 <- 第一步,释放已有内存资源 移动资源 1024 字节 <- 第二步,移交内存资源的管理权 销毁对象 创建的对象大小是 1024 字节 销毁对象,释放内存资源 1024 字节由此可见,为类提供能够接收右值引用作为参数的移动构造函数和移动赋值操作符,是提升处理函数返回值这一常见操作性能的有效策略。
在 C++ 标准库中,例如 vector 容器,已经利用右值引用进行了优化,我们可以直接利用这些特性,享受其带来的性能提升。
对于我们自己创建的类,如果它们可能会作为函数的返回值并被赋值给其他左值对象,提供移动构造函数和移动赋值操作符将允许我们重新利用原本可能被丢弃的右值,从而在一定程度上提高程序的性能。
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: