自注意力和循环神经网络的区别(新手必看)
目前,循环神经网络的角色很大一部分可以用自注意力来取代,但循环神经网络 跟自注意力一样,也要处理输入是一个序列的情况。
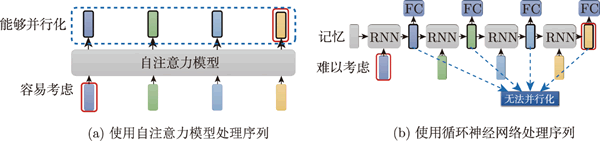
图 1 对比自注意力模型和循环神经网络
如图 1(b) 所示,循环神经网络里有一个输入序列、一个隐向量、一个循环神经网络的块(block)。 循环神经网络的块接收记忆的向量,输出一个东西,这个东西被输入全连接网络以进行预测。
循环神经网络中的隐向量存储了历史信息,可以看作一种记忆(memory)。
接下来,当把第 2 个向量作为输入的时候,前一个时间点输出的结果也会输入循环神经网络,产生新的向量,再输入全连接网络。当把第 3 个向量作为输入的时候,第 3 个向量和前一个时间点的输出一起被输入循环神经网络并产生新的输出。当把第 4 个向量作为输入的时候,将第 4 个向量和前一个时间点产生的输出一并处理,得到新的输出并再次通过全连接网络,这就是循环神经网络。
循环神经网络的输入是一个向量序列。如图 1(a) 所示,自注意力模型的输出也是一个向量序列,其中的每一个向量都考虑了整个输入序列,再输入全连接网络进行处理。循环神经网络也输出一组向量,这组向量被输入全连接网络做进一步的处理。
自注意力和循环神经网络有一个显而易见的不同之处,自注意力的每一个向量都考虑了整个输入序列,而循环神经网络的每一个向量只考虑左边已经输入的向量,而没有考虑右边的向量。但循环神经网络也可以是双向的,如果使用Bi-RNN,则每一个隐状态的输出也可以看作考虑了整个输入序列。
对比自注意力模型的输出和循环神经网络的输出。就算是双向循环神经网络,也还是与自注意力模型有一些差别的。如图 1(b) 所示,对于循环神经网络,如果最右边黄色的向量要考虑最左边的输入,则必须把最左边的输入存到记忆里才能不被遗忘,并且直至带到最右边,才能够在最后一个时间点被考虑,但只要自注意力模型输出的查询和键匹配(match),自注意力模型就可以轻易地从整个序列上非常远的向量中抽取信息。
自注意力和循环神经网络还有另一个更主要的不同之处,循环神经网络在输入和输出均为序列的时候,是没有办法对它们进行并行化的。
比如计算第二个输出的向量,不仅需要第二个输入的向量,还需要前一个时间点的输出向量。当输入是一组向量、输出是另一组向量的时候,循环神经网络无法并行处理所有的输出,但自注意力可以。输入一组向量,自注意力模型输出的时候,每一个向量都是同时并行产生的,自注意力比循环神经网络的运算速度更快。很多应用已经把循环神经网络的架构逐渐改成自注意力的架构了。
图也可以看作一组向量,既然是一组向量,也就可以用自注意力来处理。但在把自注意力用在图上面时,有些地方会不一样。
图中的每一个节点(node)可以表示成一个向量。但图中不仅有节点的信息,还有边(edge)的信息,用于表示某些节点间是有关联的。之前在做自注意力的时候,所谓的关联性是网络自己找出来的。现在既然有了图的信息,关联性就不需要机器自动找出来,图中的边已经暗示了节点和节点之间的关联性。所以当把自注意力用在图上面的时候,我们可以在计算注意力矩阵的时候,只计算有边相连的节点。
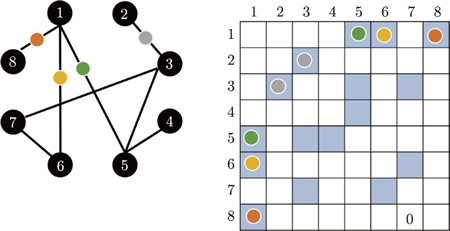
图 2 自注意力在图上的应用
举个例子,如图 2 所示,节点 1 只和节点 5、6、8 相连,因此只需要计算节点 1 和节点 5、节点 6、节点 8 之间的注意力分数;节点 2 只和节点 3 相连,因此只需要计算节点 2 和节点 3 之间的注意力分数,以此类推。
如果两个节点不相连,这两个节点之间就没有关系。既然没有关系,也就不需要再计算注意力分数,直接将其设为 0 即可。因为图往往是根据某些领域知识构建出来的,所以从领域知识可知这两个向量之间没有关联,于是也就没有必要再用机器去学习这件事情。当把自注意力按照这种限制用在图上面的时候,其实使用的就是一种图神经网络。
自注意力有非常多的变体,自注意力最大的问题是运算量非常大,如何减少自注意力的运算量是未来研究的重点方向。自注意力最早被用在 Transformer 上,所以很多人在讲 Transformer 的时候,其实指的是自注意力。有人认为广义的 Transformer 指的就是自注意力,所以后来自注意力的各种变体都以 -former 结尾,比如 Linformer、Performer、Reformer 等。这些新的变体往往比原来的 Transformer 性能差一点,但速度比较快。
图 1 对比自注意力模型和循环神经网络
如图 1(b) 所示,循环神经网络里有一个输入序列、一个隐向量、一个循环神经网络的块(block)。 循环神经网络的块接收记忆的向量,输出一个东西,这个东西被输入全连接网络以进行预测。
循环神经网络中的隐向量存储了历史信息,可以看作一种记忆(memory)。
接下来,当把第 2 个向量作为输入的时候,前一个时间点输出的结果也会输入循环神经网络,产生新的向量,再输入全连接网络。当把第 3 个向量作为输入的时候,第 3 个向量和前一个时间点的输出一起被输入循环神经网络并产生新的输出。当把第 4 个向量作为输入的时候,将第 4 个向量和前一个时间点产生的输出一并处理,得到新的输出并再次通过全连接网络,这就是循环神经网络。
循环神经网络的输入是一个向量序列。如图 1(a) 所示,自注意力模型的输出也是一个向量序列,其中的每一个向量都考虑了整个输入序列,再输入全连接网络进行处理。循环神经网络也输出一组向量,这组向量被输入全连接网络做进一步的处理。
自注意力和循环神经网络有一个显而易见的不同之处,自注意力的每一个向量都考虑了整个输入序列,而循环神经网络的每一个向量只考虑左边已经输入的向量,而没有考虑右边的向量。但循环神经网络也可以是双向的,如果使用Bi-RNN,则每一个隐状态的输出也可以看作考虑了整个输入序列。
对比自注意力模型的输出和循环神经网络的输出。就算是双向循环神经网络,也还是与自注意力模型有一些差别的。如图 1(b) 所示,对于循环神经网络,如果最右边黄色的向量要考虑最左边的输入,则必须把最左边的输入存到记忆里才能不被遗忘,并且直至带到最右边,才能够在最后一个时间点被考虑,但只要自注意力模型输出的查询和键匹配(match),自注意力模型就可以轻易地从整个序列上非常远的向量中抽取信息。
自注意力和循环神经网络还有另一个更主要的不同之处,循环神经网络在输入和输出均为序列的时候,是没有办法对它们进行并行化的。
比如计算第二个输出的向量,不仅需要第二个输入的向量,还需要前一个时间点的输出向量。当输入是一组向量、输出是另一组向量的时候,循环神经网络无法并行处理所有的输出,但自注意力可以。输入一组向量,自注意力模型输出的时候,每一个向量都是同时并行产生的,自注意力比循环神经网络的运算速度更快。很多应用已经把循环神经网络的架构逐渐改成自注意力的架构了。
图也可以看作一组向量,既然是一组向量,也就可以用自注意力来处理。但在把自注意力用在图上面时,有些地方会不一样。
图中的每一个节点(node)可以表示成一个向量。但图中不仅有节点的信息,还有边(edge)的信息,用于表示某些节点间是有关联的。之前在做自注意力的时候,所谓的关联性是网络自己找出来的。现在既然有了图的信息,关联性就不需要机器自动找出来,图中的边已经暗示了节点和节点之间的关联性。所以当把自注意力用在图上面的时候,我们可以在计算注意力矩阵的时候,只计算有边相连的节点。
图 2 自注意力在图上的应用
举个例子,如图 2 所示,节点 1 只和节点 5、6、8 相连,因此只需要计算节点 1 和节点 5、节点 6、节点 8 之间的注意力分数;节点 2 只和节点 3 相连,因此只需要计算节点 2 和节点 3 之间的注意力分数,以此类推。
如果两个节点不相连,这两个节点之间就没有关系。既然没有关系,也就不需要再计算注意力分数,直接将其设为 0 即可。因为图往往是根据某些领域知识构建出来的,所以从领域知识可知这两个向量之间没有关联,于是也就没有必要再用机器去学习这件事情。当把自注意力按照这种限制用在图上面的时候,其实使用的就是一种图神经网络。
自注意力有非常多的变体,自注意力最大的问题是运算量非常大,如何减少自注意力的运算量是未来研究的重点方向。自注意力最早被用在 Transformer 上,所以很多人在讲 Transformer 的时候,其实指的是自注意力。有人认为广义的 Transformer 指的就是自注意力,所以后来自注意力的各种变体都以 -former 结尾,比如 Linformer、Performer、Reformer 等。这些新的变体往往比原来的 Transformer 性能差一点,但速度比较快。