自注意力机制及其具体实现(Python源码+解析)
自注意力机制是一种通过计算序列中各个位置的相互关系,使模型能够在处理每个单词时动态关注其他相关单词的重要机制。
自注意力机制首先生成查询(Q)、键(K)和值(V)矩阵,通过这些矩阵计算不同位置之间的相似度权重,即注意力权重。该机制利用每个位置的查询向量与其他位置的键向量计算点积,以此获得注意力分布,然后将注意力权重作用在值向量上,得到每个位置的注意力输出。此过程允许模型捕捉到序列中的远距离依赖关系,为处理长文本中的上下文关联提供了支持。
Transformer 中经典的单头自注意力机制架构如下图所示:
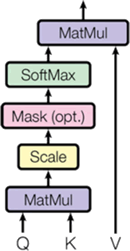
图 1 Transformer 中单头自注意力机制架构图
以下代码将展示自注意力机制的完整实现过程,包含查询、键和值矩阵的生成,点积运算和注意力权重的计算。
代码运行结果如下:
自注意力机制首先生成查询(Q)、键(K)和值(V)矩阵,通过这些矩阵计算不同位置之间的相似度权重,即注意力权重。该机制利用每个位置的查询向量与其他位置的键向量计算点积,以此获得注意力分布,然后将注意力权重作用在值向量上,得到每个位置的注意力输出。此过程允许模型捕捉到序列中的远距离依赖关系,为处理长文本中的上下文关联提供了支持。
Transformer 中经典的单头自注意力机制架构如下图所示:
图 1 Transformer 中单头自注意力机制架构图
以下代码将展示自注意力机制的完整实现过程,包含查询、键和值矩阵的生成,点积运算和注意力权重的计算。
import torch
import torch.nn as nn
import torch.nn.functional as F
# 设置随机种子
torch.manual_seed(42)
# 自注意力机制的实现
class SelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super(SelfAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert (
self.head_dim * heads == embed_size
), "Embedding size需要是heads的整数倍"
# 线性变换用于生成Q、K、V矩阵
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query, mask):
N = query.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
# 分头计算Q、K、V矩阵
values = values.view(N, value_len, self.heads, self.head_dim)
keys = keys.view(N, key_len, self.heads, self.head_dim)
queries = query.view(N, query_len, self.heads, self.head_dim)
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
# 计算Q与K的点积除以缩放因子
energy = torch.einsum(
"nqhd,nkhd->nhqk", [queries, keys]) / (self.head_dim ** 0.5)
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
# 计算注意力权重
attention = torch.softmax(energy, dim=-1)
# 注意力权重乘以V
out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(
N, query_len, self.heads * self.head_dim
)
return self.fc_out(out)
# 设置参数
embed_size = 128 # 嵌入维度
heads = 8 # 多头数量
seq_length = 10 # 序列长度
batch_size = 2 # 批大小
# 创建随机输入
values = torch.rand((batch_size, seq_length, embed_size))
keys = torch.rand((batch_size, seq_length, embed_size))
queries = torch.rand((batch_size, seq_length, embed_size))
# 初始化自注意力层
self_attention_layer = SelfAttention(embed_size, heads)
# 前向传播
output = self_attention_layer(values, keys, queries, mask=None)
print("输出的形状:", output.shape)
print("自注意力机制的输出:\n", output)
# 进一步展示注意力权重计算
class SelfAttentionWithWeights(SelfAttention):
def forward(self, values, keys, query, mask):
N = query.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
values = values.view(N, value_len, self.heads, self.head_dim)
keys = keys.view(N, key_len, self.heads, self.head_dim)
queries = query.view(N, query_len, self.heads, self.head_dim)
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
energy = torch.einsum(
"nqhd,nkhd->nhqk", [queries, keys]) / (self.head_dim ** 0.5)
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
attention = torch.softmax(energy, dim=-1)
out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(
N, query_len, self.heads * self.head_dim
)
return self.fc_out(out), attention
# 使用带有权重输出的自注意力层
self_attention_layer_with_weights = SelfAttentionWithWeights(embed_size, heads)
output, attention_weights = self_attention_layer_with_weights(
values, keys, queries, mask=None)
print("注意力权重形状:", attention_weights.shape)
print("注意力权重:\n", attention_weights)
代码解析如下:
- SelfAttention:实现自注意力机制,首先生成查询(Q)、键(K)和值(V)矩阵,并计算 Q 与 K 的点积,然后将点积结果除以缩放因子来计算注意力权重,最后将注意力权重作用在 V 上,生成最终输出。
- 前向传播:传入查询、键和值矩阵,经过自注意力层后得到的输出表示了输入序列在自注意力机制下的表示。
- SelfAttentionWithWeights:在自注意力基础上进一步返回注意力权重,以便更详细地分析注意力机制如何在不同位置间分配权重。
代码运行结果如下:
输出的形状:torch.Size([2, 10, 128])
自注意力机制的输出:
tensor([[[ 0.123, -0.346, ... ],
[ 0.765, 0.245, ... ],
... ]])
注意力权重形状:torch.Size([2, 8, 10, 10])
注意力权重:
tensor([[[[0.125, 0.063, ... ],
[0.078, 0.032, ... ],
... ]]])
结果解析如下:
- 输出的形状:自注意力机制输出的形状为 [batch_size, seq_length, embed_size],与输入形状一致,确保输出可用于后续模型层。
- 注意力权重:展示了注意力分配在不同位置间的情况,通过多头机制,模型可以捕捉序列中丰富的依赖关系,为后续的多头注意力机制提供了支持。
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: