自注意力和卷积神经网络的区别和关联
提到自注意力的时候,自注意力适用于输入是一组向量的情形。一幅图像可以看作一个向量序列。
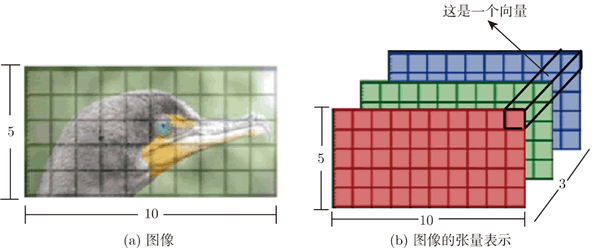
图 1 使用自注意力处理图像
如上图所示,一幅分辨率为 5×10 的图像可以表示成一个大小为 5×10×3 的张量,其中的 3 代表通道数,每一个位置的像素可看作一个三维的向量,整幅图像有 5×10 个向量。换个角度看图像,图像其实也是一个向量序列,因此完全可以用自注意力来处理。
自注意力跟卷积神经网络之间有什么样的差异或关联呢?如下图 (a) 所示,用自注意力来处理一幅图像,假设红框内的“1”是要考虑的像素,它会产生查询,其他像素产生键。在做内积的时候,考虑的不是一个小的范围,而是整幅图像的信息。
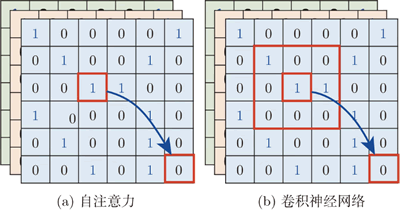
图 2 自注意力和卷积神经网络的区别
如图 2(b) 所示,在做卷积神经网络的时候,卷积神经网络会“画”出一个感受野,只考虑感受野范围内的信息。
通过比较卷积神经网络和自注意力,我们发现,卷积神经网络可以看作一种简化版的自注意力,因为在做卷积神经网络的时候,只考虑感受野范围内的信息;而自注意力会考虑整幅图像的信息。
在卷积神经网络中,我们需要划定感受野。每一个神经元只考虑感受野范围内的信息,而感受野的大小是由人决定的。用自注意力找出相关的像素,就好像感受野是自动学出来的,网络自行决定感受野的大小。网络决定了以哪些像素为中心,哪些像素是真正需要考虑的,而哪些像素是相关的。
只要设定合适的参数,自注意力就可以做到跟卷积神经网络一样的效果。卷积神经网络的函数集(function set)与自注意力的函数集的关系如下图所示:
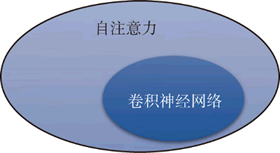
图 3 卷积神经网络的函数集与自注意力的函数集的关系
自注意力是更灵活的卷积神经网络,而卷积神经网络是受限制的自注意力。
更灵活的模型需要更多的数据,如果数据不够,就有可能过拟合。受限制的模型则适合在数据少的时候使用,并且可能不会过拟合。如果限制设计得好,也许会有不错的结果。
谷歌的论文“An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale”把自注意力应用在了图像上,一幅图像被分割为 16×16 个图像块(patch),每一个图像块可以想象成一个字(word)。因为自注意力通常用在自然语言处理上,所以我们可以想象每一个图像块就是一个字。
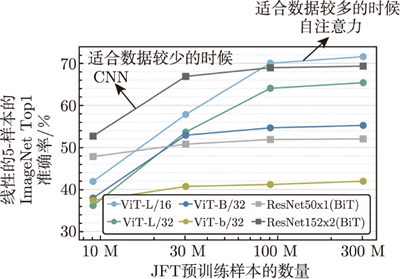
图 4 自注意力与卷积神经网络对比
如上图所示,横轴是训练样本的数量,数据量比较小的设置有 1000 万幅图像,数据量比较大的设置有 3 亿幅图像。
在这个实验中,自注意力是浅蓝色线,卷积神经网络是深灰色线。随着数据量越来越大,自注意力的结果越来越好。最终在数据量最大的时候,自注意力可以超过卷积神经网络,但在数据量小的时候,卷积神经网络可以比自注意力得到更好的结果。
自注意力的弹性比较大,所以需要比较多的训练数据,训练数据少的时候就会过拟合。而卷积神经网络的弹性比较小,在训练数据少的时候反而结果比较好。当训练数据多的时候,卷积神经网络没有办法从更大量的训练数据中得到好处。这就是自注意力和卷积神经网络的区别。
图 1 使用自注意力处理图像
如上图所示,一幅分辨率为 5×10 的图像可以表示成一个大小为 5×10×3 的张量,其中的 3 代表通道数,每一个位置的像素可看作一个三维的向量,整幅图像有 5×10 个向量。换个角度看图像,图像其实也是一个向量序列,因此完全可以用自注意力来处理。
自注意力跟卷积神经网络之间有什么样的差异或关联呢?如下图 (a) 所示,用自注意力来处理一幅图像,假设红框内的“1”是要考虑的像素,它会产生查询,其他像素产生键。在做内积的时候,考虑的不是一个小的范围,而是整幅图像的信息。
图 2 自注意力和卷积神经网络的区别
如图 2(b) 所示,在做卷积神经网络的时候,卷积神经网络会“画”出一个感受野,只考虑感受野范围内的信息。
通过比较卷积神经网络和自注意力,我们发现,卷积神经网络可以看作一种简化版的自注意力,因为在做卷积神经网络的时候,只考虑感受野范围内的信息;而自注意力会考虑整幅图像的信息。
在卷积神经网络中,我们需要划定感受野。每一个神经元只考虑感受野范围内的信息,而感受野的大小是由人决定的。用自注意力找出相关的像素,就好像感受野是自动学出来的,网络自行决定感受野的大小。网络决定了以哪些像素为中心,哪些像素是真正需要考虑的,而哪些像素是相关的。
只要设定合适的参数,自注意力就可以做到跟卷积神经网络一样的效果。卷积神经网络的函数集(function set)与自注意力的函数集的关系如下图所示:
图 3 卷积神经网络的函数集与自注意力的函数集的关系
自注意力是更灵活的卷积神经网络,而卷积神经网络是受限制的自注意力。
更灵活的模型需要更多的数据,如果数据不够,就有可能过拟合。受限制的模型则适合在数据少的时候使用,并且可能不会过拟合。如果限制设计得好,也许会有不错的结果。
谷歌的论文“An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale”把自注意力应用在了图像上,一幅图像被分割为 16×16 个图像块(patch),每一个图像块可以想象成一个字(word)。因为自注意力通常用在自然语言处理上,所以我们可以想象每一个图像块就是一个字。
图 4 自注意力与卷积神经网络对比
如上图所示,横轴是训练样本的数量,数据量比较小的设置有 1000 万幅图像,数据量比较大的设置有 3 亿幅图像。
在这个实验中,自注意力是浅蓝色线,卷积神经网络是深灰色线。随着数据量越来越大,自注意力的结果越来越好。最终在数据量最大的时候,自注意力可以超过卷积神经网络,但在数据量小的时候,卷积神经网络可以比自注意力得到更好的结果。
自注意力的弹性比较大,所以需要比较多的训练数据,训练数据少的时候就会过拟合。而卷积神经网络的弹性比较小,在训练数据少的时候反而结果比较好。当训练数据多的时候,卷积神经网络没有办法从更大量的训练数据中得到好处。这就是自注意力和卷积神经网络的区别。
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: