BRNN双向循环神经网络简介(PyTorch实现)
RNN 和 LSTM 都只能依据之前时刻的时序信息来预测下一时刻的输出,但有些问题中当前时刻的输出不仅可能和之前的状态有关,还可能和未来的状态有关系。
例如,预测一句话中缺失的单词不仅需要根据前文来判断,还需要考虑它后面的内容,真正做到基于上下文判断。
双向循环神经网络(BRNN)由两个 RNN 上下叠加在一起组成,输出由这两个 RNN 的状态共同决定。下图为一个含单隐藏层的 BRNN 的架构。
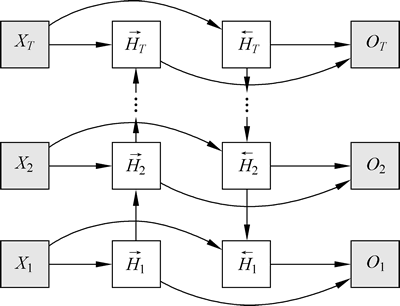
图 1 BRNN 架构
下面介绍 BRNN 的具体定义。给定时间步 t 的小批量输入 Xt∈Rn×d(样本数为 n,输入个数为 d)和隐藏层激活函数 ϕ,在双向循环神经网络的架构中,设该时间步正向隐藏状态为:
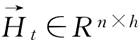
正向隐藏单元个数为 h),反向隐藏状态为:
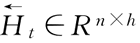
(反向隐藏单元个数为h)。可以分别计算正向隐藏状态和反向隐藏状态:
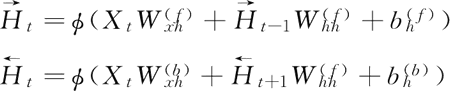
其中,权重:
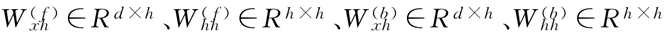
和偏差:
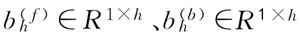
均为模型参数。
使用连续两个方向的隐藏状态和得到隐藏状态 Ht∈Rn×2h,并将其输入到输出层。输出层计算输出 Ot∈Rn×q(输出个数为 q):
【实例】BRNN 的 PyTorch 实现。
例如,预测一句话中缺失的单词不仅需要根据前文来判断,还需要考虑它后面的内容,真正做到基于上下文判断。
双向循环神经网络(BRNN)由两个 RNN 上下叠加在一起组成,输出由这两个 RNN 的状态共同决定。下图为一个含单隐藏层的 BRNN 的架构。
图 1 BRNN 架构
下面介绍 BRNN 的具体定义。给定时间步 t 的小批量输入 Xt∈Rn×d(样本数为 n,输入个数为 d)和隐藏层激活函数 ϕ,在双向循环神经网络的架构中,设该时间步正向隐藏状态为:
正向隐藏单元个数为 h),反向隐藏状态为:
(反向隐藏单元个数为h)。可以分别计算正向隐藏状态和反向隐藏状态:
其中,权重:
和偏差:
均为模型参数。
使用连续两个方向的隐藏状态和得到隐藏状态 Ht∈Rn×2h,并将其输入到输出层。输出层计算输出 Ot∈Rn×q(输出个数为 q):
Ot=HtWhq+bq
【实例】BRNN 的 PyTorch 实现。
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
# 设备配置
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 超参数
sequence_length = 28
input_size = 28
hidden_size = 128
num_layers = 2
num_classes = 10
batch_size = 100
num_epochs = 2
learning_rate = 0.003
# MNIST 数据集
train_dataset = torchvision.datasets.MNIST(
root='../../data/',
train=True,
transform=transforms.ToTensor(),
download=True
)
test_dataset = torchvision.datasets.MNIST(
root='../../data/',
train=False,
transform=transforms.ToTensor()
)
# 数据加载器
train_loader = torch.utils.data.DataLoader(
dataset=train_dataset,
batch_size=batch_size,
shuffle=True
)
test_loader = torch.utils.data.DataLoader(
dataset=test_dataset,
batch_size=batch_size,
shuffle=False
)
# 双向循环神经网络(多对一)
class BiRNN(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, num_classes):
super(BiRNN, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(
input_size,
hidden_size,
num_layers,
batch_first=True,
bidirectional=True
)
self.fc = nn.Linear(hidden_size * 2, num_classes) # 双向拼接
def forward(self, x):
# 设置初始状态
h0 = torch.zeros(self.num_layers * 2, x.size(0), self.hidden_size).to(device)
c0 = torch.zeros(self.num_layers * 2, x.size(0), self.hidden_size).to(device)
# 前向传播 LSTM
out, _ = self.lstm(x, (h0, c0))
# 解码最后一个时间步的隐藏状态
out = self.fc(out[:, -1, :])
return out
model = BiRNN(input_size, hidden_size, num_layers, num_classes).to(device)
# 损失和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 训练模型
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.reshape(-1, sequence_length, input_size).to(device)
labels = labels.to(device)
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# 反向优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(
'Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(
epoch + 1, num_epochs, i + 1, total_step, loss.item()
)
)
# 测试模型
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.reshape(-1, sequence_length, input_size).to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(
'Test Accuracy of the model on the 10000 test images: {}%'.format(
100 * correct / total
)
)
# 模型保存
torch.save(model.state_dict(), 'model.ckpt')
运行程序,输出如下:
Epoch[1/2],Step[100/600],Loss:0.6954
Epoch[1/2],Step[200/600],Loss:0.3623
Epoch[1/2],Step[300/600],Loss:0.1572
Epoch[1/2],Step[400/600],Loss:0.1423
Epoch[1/2],Step[500/600],Loss:0.1048
Epoch[1/2],Step[600/600],Loss:0.0815
Epoch[2/2],Step[100/600],Loss:0.1204
Epoch[2/2],Step[200/600],Loss:0.1067
Epoch[2/2],Step[300/600],Loss:0.1271
Epoch[2/2],Step[400/600],Loss:0.0144
Epoch[2/2],Step[500/600],Loss:0.0324
Epoch[2/2],Step[600/600],Loss:0.0608
Test Accuracy of the model on the 10000 test images:97.38%
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: