Transformer架构是什么(非常详细)
自然语言处理(Natural Language Processing,NLP)技术的发展是一个逐步迭代和优化的过程。在 Transformer 架构出现之前,该领域经历了从依赖人工规则和知识库到使用统计学和深度学习模型的转变。Transformer 的出现标志着自然语言处理进入一个新时代,特别是随着 BERT 和 GPT 等模型的推出,大幅提升了自然语言的理解和生成能力。
现在,基于 Transformer 架构的应用正在经历一个前所未有的爆发期。Transformer 架构是一种基于注意力机制的深度学习模型,由谷歌的研究人员在 2017 年提出,被广泛应用于自然语言处理任务,如机器翻译、文本分类、情感分析等。
我们目前广泛使用的 ChatGPT 聊天模型就是基于 Transformer 架构开发的。因此,想要全面了解生成式大模型,必须了解 Transformer 架构。
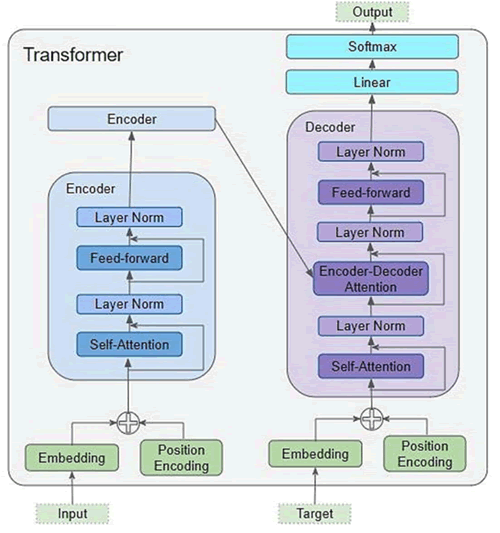
图 1 Transformer架构
对于一条输入的文本数据,在 Transformer 这个复杂的架构中是如何流动和处理的,下面介绍一下这个过程。
在 Transformer 模型中,首先对输入文本进行处理以得到合适的文本表示,为什么要进行这样的转换呢?
考虑这样一个场景,当你输入“AI+编程 同心协力”这句话时,计算机能直接理解吗?或者说,当你与 ChatGPT 互动时,它是否真的“听到”了你说的每一个词或字?
ChatGPT 并不直接处理自然语言。它需要将我们的输入转换为它能理解的数据形式。简而言之,它会把每个词或每个字符编码成一个特定的向量形式。
这个编码过程的具体步骤如下:
1) 词嵌入(Word Embedding)。文本中的每个单词都被转换为一个高维向量,这个转换通常是通过预训练的词嵌入模型(如 Word2Vec、GloVe 等)完成的。
2) 位置嵌入(Positional Embedding)。标准的 Transformer 模型没有内置序列顺序感知能力,因此需要添加位置信息。这是通过位置嵌入完成的,它与词嵌入具有相同的维度,并且与词嵌入相加。
例如,考虑句子“AI+编程 同心协力”。
如果没有位置嵌入,该句子可能会被错误地解析为“编AI+程,同力协心”等,这会破坏句子原有的顺序和语义。位置嵌入的目的就是确保编码后的词向量能准确地反映句子中词语的顺序,从而保留整个句子的原意。
3) 相加(Addition)。词嵌入和位置嵌入相加,得到一个包含文本信息和位置信息的新的嵌入表示。最终得到输入的 Transformer 表示 x,这样模型不仅能知道每个单词是什么,还能知道它在序列中的位置。通过这样的一个处理过程,模型就可以认识“AI+编程 同心协力”这样的一个输入。
对于 Transformer 的输入处理部分,从架构图上编码器和解码器部分都有输入,这个怎么理解?这是因为在 Transformer 模型中,编码器(Encoder)和解码器(Decoder)各自有独立的输入。通常,在有监督学习的场景下,编码器负责处理输入样本,而解码器负责处理与之对应的标签,这些标签在进入解码器之前同样需要经过适当的预处理,这样的设置允许模型在特定任务上进行有针对性的训练。
1) 输入数据(比如一段文字)会被送入注意力(Attention)机制进行处理,这里会给数据中的每个元素打个分数,以决定哪些更重要,在“注意力机制”(Attention)这个步骤之后,会有一些新的数据生成。
2) 执行 Add 操作,在注意力机制中产生的新数据会和最开始输入的原始数据合在一起,这个合并其实就是简单的加法。Add 表示残差连接,这一操作的主要目的是确保数据经过注意力处理后的效果至少不逊于直接输入的原始数据。
3) 数据会经过一个简单的数学处理,叫作层归一化(Norm),这主要是为了让数据更稳定,便于后续处理。
4) 数据将进入一个双层的前馈神经网络。这里的目标是将经过注意力处理的数据映射到其原始的维度,以便于后续处理。因为编码器会被多次堆叠,所以需要确保数据的维度在进入下一个编码器前是一致的,也就是把经过前面所有处理的数据变回原来的形状和大小。
5) 为了准备数据进入下一个编码器(如果有的话),数据会再次经过 Add 和 Norm 操作,输出一个经过精细计算和重构的词向量表示。
这样的设计确保了模型在多个编码器层之间能够有效地传递和处理信息,同时也为更复杂的计算和解码阶段做好了准备。
简单来说,Transformer 编码器就是通过这些步骤来理解和处理输入的数据的,然后输出一种新的、更容易理解的数据形式。
1) 进入一个有遮罩(Masked)的注意力(Attention)机制,这个遮罩的作用是确保解码器只能关注到它之前已经生成的词,而不能看到未来的词。
2) 这一层输出的信息会与来自 Encoder 部分的输出进行融合。具体来说,这两部分的信息会再次经过注意力机制的处理,从而综合考虑编码与解码的内容。
3) 解码器的操作与编码器部分大致相同。数据会经过层归一化、前馈神经网络,再次进行层归一化,最终输出一个词向量表示。
4) 输出的词向量首先会通过一个线性层(Linear),这一步的目的是将向量映射到预先定义的词典大小,从而准备进行词预测。
5) 使用 Softmax 函数计算每个词的生成概率。最终,选取概率最高的词作为该时刻的输出。
这样,Decoder 不仅考虑了之前解码生成的词,还综合了 Encoder 的上下文信息,从而可以更准确地预测下一个词。
现在,基于 Transformer 架构的应用正在经历一个前所未有的爆发期。Transformer 架构是一种基于注意力机制的深度学习模型,由谷歌的研究人员在 2017 年提出,被广泛应用于自然语言处理任务,如机器翻译、文本分类、情感分析等。
我们目前广泛使用的 ChatGPT 聊天模型就是基于 Transformer 架构开发的。因此,想要全面了解生成式大模型,必须了解 Transformer 架构。
Transformer架构的组成
Transformer 架构由编码器(Encoder)和解码器(Decoder)组成,其中编码器用于学习输入序列的表示,解码器用于生成输出序列。GPT 主要采用了 Transformer 的解码器部分,用于构建语言模型,其架构如下图所示。图 1 Transformer架构
对于一条输入的文本数据,在 Transformer 这个复杂的架构中是如何流动和处理的,下面介绍一下这个过程。
在 Transformer 模型中,首先对输入文本进行处理以得到合适的文本表示,为什么要进行这样的转换呢?
考虑这样一个场景,当你输入“AI+编程 同心协力”这句话时,计算机能直接理解吗?或者说,当你与 ChatGPT 互动时,它是否真的“听到”了你说的每一个词或字?
ChatGPT 并不直接处理自然语言。它需要将我们的输入转换为它能理解的数据形式。简而言之,它会把每个词或每个字符编码成一个特定的向量形式。
这个编码过程的具体步骤如下:
1) 词嵌入(Word Embedding)。文本中的每个单词都被转换为一个高维向量,这个转换通常是通过预训练的词嵌入模型(如 Word2Vec、GloVe 等)完成的。
2) 位置嵌入(Positional Embedding)。标准的 Transformer 模型没有内置序列顺序感知能力,因此需要添加位置信息。这是通过位置嵌入完成的,它与词嵌入具有相同的维度,并且与词嵌入相加。
例如,考虑句子“AI+编程 同心协力”。
如果没有位置嵌入,该句子可能会被错误地解析为“编AI+程,同力协心”等,这会破坏句子原有的顺序和语义。位置嵌入的目的就是确保编码后的词向量能准确地反映句子中词语的顺序,从而保留整个句子的原意。
3) 相加(Addition)。词嵌入和位置嵌入相加,得到一个包含文本信息和位置信息的新的嵌入表示。最终得到输入的 Transformer 表示 x,这样模型不仅能知道每个单词是什么,还能知道它在序列中的位置。通过这样的一个处理过程,模型就可以认识“AI+编程 同心协力”这样的一个输入。
对于 Transformer 的输入处理部分,从架构图上编码器和解码器部分都有输入,这个怎么理解?这是因为在 Transformer 模型中,编码器(Encoder)和解码器(Decoder)各自有独立的输入。通常,在有监督学习的场景下,编码器负责处理输入样本,而解码器负责处理与之对应的标签,这些标签在进入解码器之前同样需要经过适当的预处理,这样的设置允许模型在特定任务上进行有针对性的训练。
Encoder(编码器部分)
Transformer 的编码器部分的作用是学习输入序列的表示,其数据处理流程如下:1) 输入数据(比如一段文字)会被送入注意力(Attention)机制进行处理,这里会给数据中的每个元素打个分数,以决定哪些更重要,在“注意力机制”(Attention)这个步骤之后,会有一些新的数据生成。
2) 执行 Add 操作,在注意力机制中产生的新数据会和最开始输入的原始数据合在一起,这个合并其实就是简单的加法。Add 表示残差连接,这一操作的主要目的是确保数据经过注意力处理后的效果至少不逊于直接输入的原始数据。
3) 数据会经过一个简单的数学处理,叫作层归一化(Norm),这主要是为了让数据更稳定,便于后续处理。
4) 数据将进入一个双层的前馈神经网络。这里的目标是将经过注意力处理的数据映射到其原始的维度,以便于后续处理。因为编码器会被多次堆叠,所以需要确保数据的维度在进入下一个编码器前是一致的,也就是把经过前面所有处理的数据变回原来的形状和大小。
5) 为了准备数据进入下一个编码器(如果有的话),数据会再次经过 Add 和 Norm 操作,输出一个经过精细计算和重构的词向量表示。
这样的设计确保了模型在多个编码器层之间能够有效地传递和处理信息,同时也为更复杂的计算和解码阶段做好了准备。
简单来说,Transformer 编码器就是通过这些步骤来理解和处理输入的数据的,然后输出一种新的、更容易理解的数据形式。
Decoder(解码器部分)
Transformer 的解码器部分的作用是生成输出序列,其数据处理流程如下:1) 进入一个有遮罩(Masked)的注意力(Attention)机制,这个遮罩的作用是确保解码器只能关注到它之前已经生成的词,而不能看到未来的词。
2) 这一层输出的信息会与来自 Encoder 部分的输出进行融合。具体来说,这两部分的信息会再次经过注意力机制的处理,从而综合考虑编码与解码的内容。
3) 解码器的操作与编码器部分大致相同。数据会经过层归一化、前馈神经网络,再次进行层归一化,最终输出一个词向量表示。
4) 输出的词向量首先会通过一个线性层(Linear),这一步的目的是将向量映射到预先定义的词典大小,从而准备进行词预测。
5) 使用 Softmax 函数计算每个词的生成概率。最终,选取概率最高的词作为该时刻的输出。
这样,Decoder 不仅考虑了之前解码生成的词,还综合了 Encoder 的上下文信息,从而可以更准确地预测下一个词。