Java序列化机制详解(附带实例)
Java 提供了一种对象序列化的机制,该机制中一个对象可以被表示为一个字节序列,该字节序列包括该对象的数据、对象的类型和存储在对象中的数据的类型。
将序列化对象写入文件之后,可以从文件中读取出来,并且对它进行反序列化。也就是说,对象的类型信息、对象的数据,还有对象中的数据类型可以用来在内存中新建对象。
上述整个过程都是 Java 虚拟机(JVM)独立完成的,这样在一个平台上序列化的对象可以在另一个完全不同的平台上反序列化。
对象的序列化是指将一个 Java 对象写入 I/O 流中。与此对应,对象的反序列化则是指从 I/O 流中恢复该 Java 对象。
如果需要让某个对象支持序列化机制,则必须让它的类是可序列化的。为了让某个类是可序列化的,该类就需要实现 Serializable 或者 Externalizable 这两个接口之一,一般推荐使用 Serializable 接口,因为 Serializable 接口只需实现不需要重写任何方法,使用起来较为简单。
Java 的很多类其实已经实现了 Serializable,该接口是一个标记接口,实现该接口时无须实现任何方法,它只是表明该类的实例是可序列化的。所有可能在网络上传输的对象的类都必须是可序列化的,否则程序可能会出现异常,如 RMI(Remote Method Invoke,即远程方法调用,是 Java EE 的基础)过程中的参数和返回值;所有需要保存到磁盘里的对象的类都必须可序列化,如 Web 应用中需要保存到 HttpSession 或 ServletContext 属性的 Java 对象。
因为序列化是 RMI 过程的参数和返回值都必须实现的机制,而 RMI 又是 Java EE 技术的基础,且所有的分布式应用常常需要跨平台、跨网络,所以要求所有传递的参数、返回值必须实现序列化。因此,序列化机制是 Java EE 平台的基础,通常建议程序创建的每个 JavaBean 类都实现 Serializable 接口。
使用 Serializable 来实现序列化非常简单,主要让目标类实现 Serializable 接口即可,无须实现任何方法。一旦某个类实现了 Serializable 接口,该类的对象就是可序列化的,程序可以通过如下两个步骤来序列化该对象:
1) 创建一个 ObjectOutputStream 输出流,这个输出流是一个处理流,所以必须建立在其他节点流的基础之上,代码如下:
2) 调用 ObjectOutputStream 对象的 writeObject() 方法输出可序列化对象,代码如下:
下面的程序定义了一个 Person 类,这个类就是一个普通的 Java 类,只是实现了 Serializable 接口,该接口代表该类的对象是可序列化的,代码如下:
接下来,通过案例来演示使用 ObjectOutputStream 将一个 Person 对象写入磁盘文件:
如果想从二进制流中恢复 Java 对象,则需要使用反序列化。反序化的的步骤如下:
1) 创建一个 ObjectInputStream 输入流,这个输入流也是个处理流,所以必须建立在其他节点流的基础之上,代码如下:
2) 调用 ObjectInputStream 对象的 readObject() 方法读取流中的对象,该方法返回一个 Object 类型的 Java 对象,如果程序知道该 Java 对象的类型,则可以将该对象强制类型转换成其真实的类型,代码如下:
接下来,通过案例来演示从刚刚生成的 person.txt 文件中读取 Person 对象:
必须指出的是,反序列化读取的仅仅是 Java 对象的数据,而不是 Java 类,因此采用反序列化恢复 Java 对象时,必须提供该 Java 对象所属类的 class 文件,否则将会引发 ClassNotFoundException 异常。
如果使用序列化机制向文件中写入了多个 Java 对象,使用反序列化机制恢复对象时必须按实际写入的顺序读取。
当一个可序列化类有多个父类时(包括直接父类和间接父类),这些父类要么有无参数的构造器, 要么也是可序列化的,否则反序列化时将抛出 InvalidClassException 异常。如果父类是不可序列化的,只是带有无参数的构造器,则该父类中定义的成员变量值不会序列化到二进制流中。
下面的程序中,Teacher 类持有一个 Student 类的引用,只有 Student 类是可序列化的,Teacher 类才是可序列化的。如果 Student 类不可序列化,则无论 Teacher 类是否实现 Serilizable 或 Externalizable 接口,它都是不可序列化的。代码如下:
现在假设有如下特殊情形,程序中有两个 Teacher 对象,它们的 student 实例变量都引用同一个 Student 对象,而且该 Student 对象还有一个引用变量引用,代码如下:
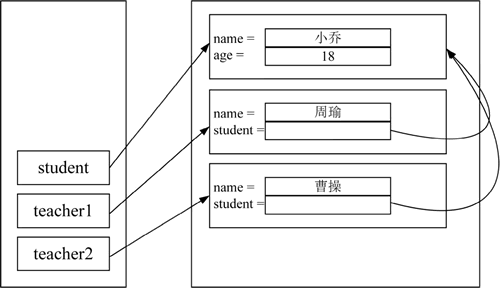
图 1 内存示意图
这里产生了一个问题,如果先序列化 teacher1 对象,则系统将该 teacherl 对象所引用的 Student 对象一起序列化。当程序序列化 teacher2 对象时,系统则一样会再次序列化 teacher2 对象所引用的 Student 对象。如果程序再显式序列化 student 对象,系统将再次序列化该 Student 对象。这个过程似乎会向输出流中输入 3 个 Student 对象。
如果系统向输出流中写入了 3 个 Student 对象,那么后果是当程序从输入流中反序列化这些对象时,将会得到 3 个 Student 对象,从而导致 teacher1 和 teacher2 所引用的 Student 对象不是同一个对象,这显然与图 1 所示的效果不一致,也违背了 Java 序列化机制的初衷。
所以,Java 序列化机制采用了一种特殊的序列化算法,其算法内容如下:
根据上面的序列化算法,可以得到一个结论,当第 2 次、第 3 次序列化 Student 对象时,程序不会再次将 Student 对象转换成字节序列并输出,而是仅仅输出一个序列化编号。
例如,有如下顺序的序列化代码:
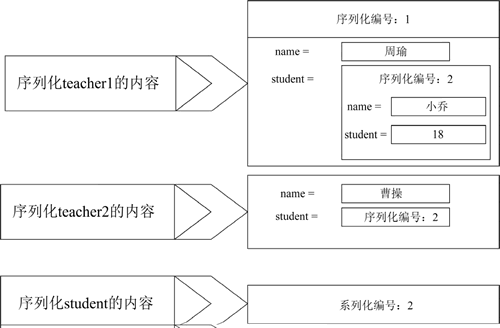
图 2 序列化机制
通过该图可以很好地理解 Java 序列化的底层机制。不难看出,当多次调用 writeObject() 方法输出同一个对象时,只有当第 1 次调用 writeObject() 方法时才会将该对象转换成字节序列并输出。
接下来,通过案例来演示序列化两个 Teacher 对象,两个 Teacher 对象都持有一个引用同一个 Student 对象的引用,而且程序两次调用 writeObject() 方法输出同一个 Teacher 对象。
第 14 行和第 15 行的代码两次调用 readObject() 方法读取了序列化文件中的对象,比较两次读取的对象结果为 true,证明是同一对象。然后,程序再次输出两个对象,两个对象的 name 值依然是“小乔”,表明改变后的 Student 对象并没有被写入,这与 Java 序列化机制相符。
将序列化对象写入文件之后,可以从文件中读取出来,并且对它进行反序列化。也就是说,对象的类型信息、对象的数据,还有对象中的数据类型可以用来在内存中新建对象。
上述整个过程都是 Java 虚拟机(JVM)独立完成的,这样在一个平台上序列化的对象可以在另一个完全不同的平台上反序列化。
什么是对象序列化
序列化机制可以将实现序列化的 Java 对象转换成字节序列,而这些字节序列可以保存在磁盘上,或者通过网络传输,以备以后重新恢复成原来的对象继续使用。序列化机制可以使 Java 对象脱离程序的运行而独立存在。对象的序列化是指将一个 Java 对象写入 I/O 流中。与此对应,对象的反序列化则是指从 I/O 流中恢复该 Java 对象。
如果需要让某个对象支持序列化机制,则必须让它的类是可序列化的。为了让某个类是可序列化的,该类就需要实现 Serializable 或者 Externalizable 这两个接口之一,一般推荐使用 Serializable 接口,因为 Serializable 接口只需实现不需要重写任何方法,使用起来较为简单。
Java 的很多类其实已经实现了 Serializable,该接口是一个标记接口,实现该接口时无须实现任何方法,它只是表明该类的实例是可序列化的。所有可能在网络上传输的对象的类都必须是可序列化的,否则程序可能会出现异常,如 RMI(Remote Method Invoke,即远程方法调用,是 Java EE 的基础)过程中的参数和返回值;所有需要保存到磁盘里的对象的类都必须可序列化,如 Web 应用中需要保存到 HttpSession 或 ServletContext 属性的 Java 对象。
因为序列化是 RMI 过程的参数和返回值都必须实现的机制,而 RMI 又是 Java EE 技术的基础,且所有的分布式应用常常需要跨平台、跨网络,所以要求所有传递的参数、返回值必须实现序列化。因此,序列化机制是 Java EE 平台的基础,通常建议程序创建的每个 JavaBean 类都实现 Serializable 接口。
Java实现对象序列化的持久化
如果需要将某个对象保存到磁盘上或者通过网络传输,那么这个类就需要实现 Serializable 接口或者 Extermalizable 接口之一。使用 Serializable 来实现序列化非常简单,主要让目标类实现 Serializable 接口即可,无须实现任何方法。一旦某个类实现了 Serializable 接口,该类的对象就是可序列化的,程序可以通过如下两个步骤来序列化该对象:
1) 创建一个 ObjectOutputStream 输出流,这个输出流是一个处理流,所以必须建立在其他节点流的基础之上,代码如下:
// 创建个 ObjectOutputStreamn输出流
FileOutputStream fos = new FileOutputStream("person.txt");
ObjectOutputStream oos = new ObjectOutputStream(fos);
2) 调用 ObjectOutputStream 对象的 writeObject() 方法输出可序列化对象,代码如下:
// 将一个Person对象写入输出流中 oos.writeObject(person);
下面的程序定义了一个 Person 类,这个类就是一个普通的 Java 类,只是实现了 Serializable 接口,该接口代表该类的对象是可序列化的,代码如下:
import java.io.Serializable;
public class Person implements Serializable {
private String name;
private Integer age;
public Person(String name, Integer age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public String toString() {
return "Person{" + "name='" + name + '\'' + ", age=" + age + '}';
}
}
接下来,通过案例来演示使用 ObjectOutputStream 将一个 Person 对象写入磁盘文件:
public class Demo {
public static void main(String[] args) {
try (FileOutputStream fos = new FileOutputStream("person.txt");
ObjectOutputStream oos = new ObjectOutputStream(fos)) {
Person person = new Person("小乔", 18);
oos.writeObject(person);
} catch (IOException e) {
e.printStackTrace();
}
}
}
程序中,第 4 行代码创建了一个 ObjectOutputStream 输出流,这个 ObjectOutputStream 输出流建立在一个文件输出流的基础之上。第 6 行代码使用 writeObject() 方法将一个 Person 对象写入输出流。运行这段代码,将会看到生成了一个 Person.txt 文件,该文件的内容就是 Person 对象。如果想从二进制流中恢复 Java 对象,则需要使用反序列化。反序化的的步骤如下:
1) 创建一个 ObjectInputStream 输入流,这个输入流也是个处理流,所以必须建立在其他节点流的基础之上,代码如下:
// 创建一个ObjectInputStream输入流
FileInputStream fis = new FileInputStream("person.txt");
ObjectInputStream ois = new ObjectInputStream(fis);
2) 调用 ObjectInputStream 对象的 readObject() 方法读取流中的对象,该方法返回一个 Object 类型的 Java 对象,如果程序知道该 Java 对象的类型,则可以将该对象强制类型转换成其真实的类型,代码如下:
// 从输入流中读取一个Java对象,并将其强制类型转换为Person类 Person person = (Person) ois.readObject();
接下来,通过案例来演示从刚刚生成的 person.txt 文件中读取 Person 对象:
public class Demo {
public static void main(String[] args) {
try (FileInputStream fis = new FileInputStream("person.txt");
ObjectInputStream ois = new ObjectInputStream(fis)) {
Person person = (Person) ois.readObject();
System.out.println(person);
} catch (Exception e) {
e.printStackTrace();
}
}
}
程序中,第 4 行代码将一个文件输入流包装成 ObjectInputStream 输入流,第 5 行代码使用 readObject() 方法读取了文件中的 Java 对象,这就完成了反序列化过程。必须指出的是,反序列化读取的仅仅是 Java 对象的数据,而不是 Java 类,因此采用反序列化恢复 Java 对象时,必须提供该 Java 对象所属类的 class 文件,否则将会引发 ClassNotFoundException 异常。
如果使用序列化机制向文件中写入了多个 Java 对象,使用反序列化机制恢复对象时必须按实际写入的顺序读取。
当一个可序列化类有多个父类时(包括直接父类和间接父类),这些父类要么有无参数的构造器, 要么也是可序列化的,否则反序列化时将抛出 InvalidClassException 异常。如果父类是不可序列化的,只是带有无参数的构造器,则该父类中定义的成员变量值不会序列化到二进制流中。
Java引用对象的序列化控制
前文中的 Person 类的两个成员变量分别是 String 类型和 Integer 类型。如果某个类的成员变量的类型不是基本类型或 String 类型,而是另一个引用类型,那么这个引用类必须是可序列化的,否则拥有该类型成员变量的类也是不可序列化的。下面的程序中,Teacher 类持有一个 Student 类的引用,只有 Student 类是可序列化的,Teacher 类才是可序列化的。如果 Student 类不可序列化,则无论 Teacher 类是否实现 Serilizable 或 Externalizable 接口,它都是不可序列化的。代码如下:
public class Teacher implements Serializable {
private String name;
private Student student;
public Teacher(String name, Student student) {
this.name = name;
this.student = student;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Student getStudent() {
return student;
}
public void setStudent(Student student) {
this.student = student;
}
@Override
public String toString() {
return "Teacher{" + "name='" + name + '\'' + ", student=" + student + '}';
}
}
class Student implements Serializable {
private String name;
private Integer age;
public Student(String name, Integer age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" + "name='" + name + '\'' + ", age=" + age + '}';
}
}
注意,当程序序列化一个 Teacher 对象时,如果该 Teacher 对象持有一个 Student 对象的引用,为了在反序列化时可以正常恢复该 Teacher 对象,程序会顺带将该 Student 对象也进行序列化,所以 Student 类也必须是可序列化的,否则 Teacher 类将不可序列化。现在假设有如下特殊情形,程序中有两个 Teacher 对象,它们的 student 实例变量都引用同一个 Student 对象,而且该 Student 对象还有一个引用变量引用,代码如下:
Student student = new Student("小乔", 18);
Teacher teacher1 = new Teacher("周瑜", student);
Teacher teacher2 = new Teacher("曹操", student);
上述代码创建了两个 Teacher 对象和一个 Student 对象,这 3 个对象在内存中的存储如下图所示。图 1 内存示意图
这里产生了一个问题,如果先序列化 teacher1 对象,则系统将该 teacherl 对象所引用的 Student 对象一起序列化。当程序序列化 teacher2 对象时,系统则一样会再次序列化 teacher2 对象所引用的 Student 对象。如果程序再显式序列化 student 对象,系统将再次序列化该 Student 对象。这个过程似乎会向输出流中输入 3 个 Student 对象。
如果系统向输出流中写入了 3 个 Student 对象,那么后果是当程序从输入流中反序列化这些对象时,将会得到 3 个 Student 对象,从而导致 teacher1 和 teacher2 所引用的 Student 对象不是同一个对象,这显然与图 1 所示的效果不一致,也违背了 Java 序列化机制的初衷。
所以,Java 序列化机制采用了一种特殊的序列化算法,其算法内容如下:
- 所有保存到磁盘中的对象都有一个序列化编号;
- 当程序试图序列化一个对象时,将先检查该对象是否已经被序列化过,只有该对象从未(在本次虚拟机中)被序列化过时,系统才会将该对象转换成字节序列并输出;
- 如果某个对象已经序列化过,程序将只是直接输出一个序列化编号,而不是再次重新序列化该对象。
根据上面的序列化算法,可以得到一个结论,当第 2 次、第 3 次序列化 Student 对象时,程序不会再次将 Student 对象转换成字节序列并输出,而是仅仅输出一个序列化编号。
例如,有如下顺序的序列化代码:
oos.writeObject(teacher1); oos.writeObject(teacher2); oos.writeObject(student);上面代码一次序列化了 teacher1、teacher2 和 student 对象,序列化后磁盘文件的存储如下图所示:
图 2 序列化机制
通过该图可以很好地理解 Java 序列化的底层机制。不难看出,当多次调用 writeObject() 方法输出同一个对象时,只有当第 1 次调用 writeObject() 方法时才会将该对象转换成字节序列并输出。
接下来,通过案例来演示序列化两个 Teacher 对象,两个 Teacher 对象都持有一个引用同一个 Student 对象的引用,而且程序两次调用 writeObject() 方法输出同一个 Teacher 对象。
public class Demo {
public static void main(String[] args) {
try (FileOutputStream fos = new FileOutputStream("teacher.txt");
ObjectOutputStream oos = new ObjectOutputStream(fos);
FileInputStream fis = new FileInputStream("teacher.txt");
ObjectInputStream ois = new ObjectInputStream(fis)) {
Student student1 = new Student("小乔", 18);
oos.writeObject(student1);
student1.setName("大乔");
System.out.println("修改名字后:" + student1);
oos.writeObject(student1);
Student s2 = (Student) ois.readObject();
Student s3 = (Student) ois.readObject();
System.out.println("s2与s3进行对比:" + (s2 == s3));
System.out.println("s2反序列化后:" + s2);
System.out.println("s3反序列化后:" + s3);
} catch (Exception e) {
e.printStackTrace();
}
}
}
程序的运行结果如下:
修改name后:Student{name='大乔', age=18}
s2与s3进行对比:true
s2反序列化后:Student{name='小乔', age=18}
s3反序列化后:Student{name='小乔', age=18}
程序中,先使用 writeObject() 方法写入了一个 Student 对象,接着改变了 Student 对象的实例变量 name 的值,然后程序再次序列化输出 Student 对象,但这次不会将 Student 对象转换成字节序列输出了,而是仅输出了一个序列化编号。第 14 行和第 15 行的代码两次调用 readObject() 方法读取了序列化文件中的对象,比较两次读取的对象结果为 true,证明是同一对象。然后,程序再次输出两个对象,两个对象的 name 值依然是“小乔”,表明改变后的 Student 对象并没有被写入,这与 Java 序列化机制相符。
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: