Seq2Seq模型是什么(非常详细)
Seq2Seq 是一种重要的 RNN 模型,也称为 Encoder-Decoder 模型,模型包含两部分:
Seq2Seq 模型结构有很多种,结构差异主要存在于 Decoder 部分。图 1 ~ 图 3 是几种比较常见的结构。
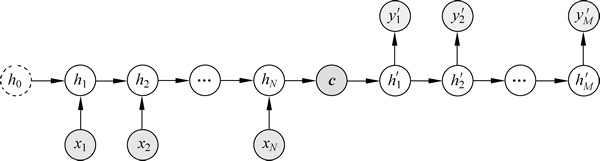
图 1 第一种结构
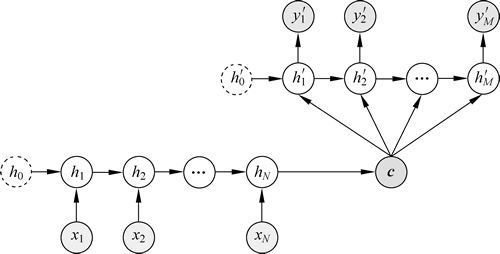
图 2 第二种结构
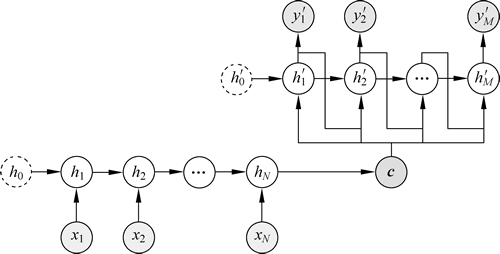
图 3 第三种结构
Softmax 在机器学习和深度学习中有着非常广泛的应用。尤其在处理多分类(分类数 C>2)问题时,分类器最后的输出单元需要 Softmax 函数进行数值处理。Softmax 函数的定义为:
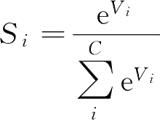
其中,Vi 是分类器前级输出单元的输出;i 表示类别索引;总的类别个数为 C,表示当前元素的指数与所有元素指数和的比值。Softmax 函数将多分类的输出数值转换为相对概率,更容易理解和比较。
例如,一个多分类问题,C=4,线性分类器模型最后输出层包含了 4 个输出值,分别是:
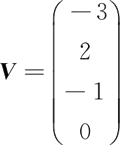
经过 Softmax 处理后,数值转换为相对概率(和为 1,即被称为归一化的过程):
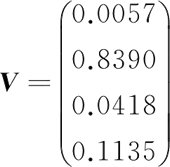
很明显,Softmax 的输出表征了不同类别之间的相对概率。可以清晰地看出,S1=0.8390,对应的概率最大,则可以更清晰地判断预测为第 1 类的可能性更大。
利用 RNN 对于某个序列的时刻t,它的词向量输出概率为 p(xt|x1, x2, …, xt-1),则 Softmax 层每个神经元的计算如下:
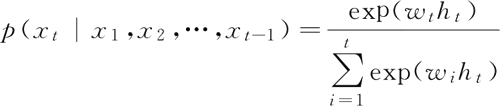
即整个序列的生成概率为:
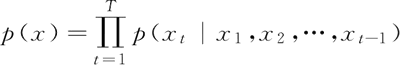
表示从第一个词到第 T 个词一次生成,产生这个词序列的概率。
Encoder-Decoder 模型如下图所示:
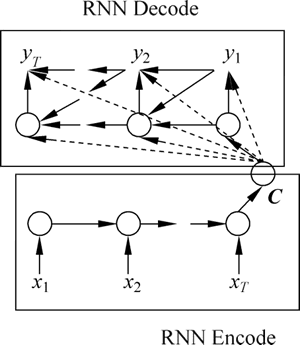
图 9 Encoder-Decoder模型
设有输入序列 x1,x2,…,xT,输出序列 y1,y2,…,yT,输入序列和输出序列的长度可能不同。那么就需要根据输入序列去得到输出序列可能输出的词概率,于是有下面的条件概率:x1,x2,…,xT 发生的情况下,y1,y2,…,yT 发生的概率等于 p(yt|v,y1,y2,…,yt-1) 连乘,如下式所示:
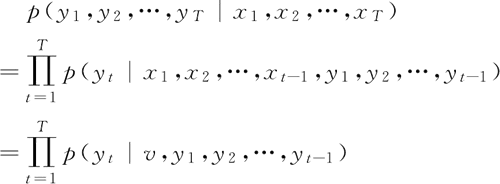
其中,v 表示 x1,x2,…,xT 对应的隐藏状态向量(输入中每个词的词向量),可以等同表示输入序列(模型依次生成 y1,y2,…,yT 的概率)。
此时,ht=f(ht-1,yt-1,v),Decode 中隐藏状态与上一时刻状态、上一时刻输出和状态 v 有关。于是 Decoder 的某一时刻的概率分布可用下式表示:
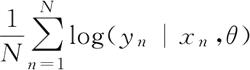
使之最大化,θ 则是待确定的模型参数。
【实例】利用 Seq2Seq 进行时间序列预测。具体实现步骤为:

图 12 数据效果
为了模拟真实世界的数据,添加一些随机噪声,效果如下图所示:
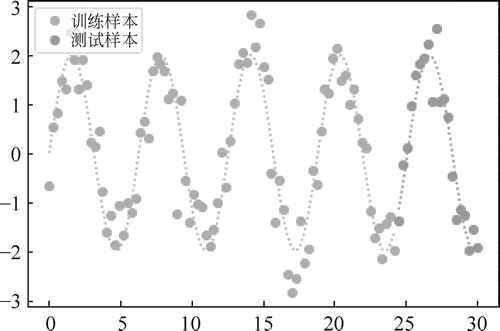
图 13 添加随机噪声效果
然后,设置输入输出的序列长度,并生成训练样本和测试样本:
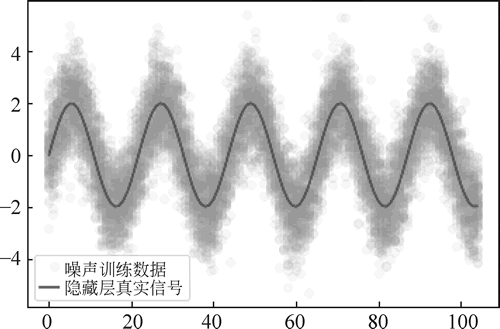
图 14 含有噪声的数据可视化
② 模型架构。此处的 Seq2Seq 模型基本与 Tensorflow 在 Github 中提供的模型一致。
③ 模型训练。设置了 batch-size 为 16,迭代次数为 100:
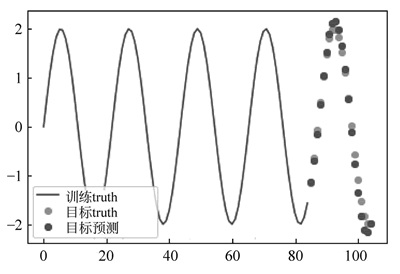
图 15 预测效果
- Encoder 用于编码序列的信息,将任意长度的序列信息编码到一个向量 c 中;
- Decoder 是解码器,解码器得到上下文信息向量 c 之后可以将信息解码,并输出为序列。
Seq2Seq 模型结构有很多种,结构差异主要存在于 Decoder 部分。图 1 ~ 图 3 是几种比较常见的结构。
图 1 第一种结构
图 2 第二种结构
图 3 第三种结构
如何训练Seq2Seq模型
RNN 可以对字符或时间序列进行预测,例如输入 t 时刻的数据后,预测 t+1 时刻的数据。为了得到概率分布,一般会在 RNN 的输出层使用 Softmax 激活函数,就可以得到每个分类的概率。Softmax 在机器学习和深度学习中有着非常广泛的应用。尤其在处理多分类(分类数 C>2)问题时,分类器最后的输出单元需要 Softmax 函数进行数值处理。Softmax 函数的定义为:
其中,Vi 是分类器前级输出单元的输出;i 表示类别索引;总的类别个数为 C,表示当前元素的指数与所有元素指数和的比值。Softmax 函数将多分类的输出数值转换为相对概率,更容易理解和比较。
例如,一个多分类问题,C=4,线性分类器模型最后输出层包含了 4 个输出值,分别是:
经过 Softmax 处理后,数值转换为相对概率(和为 1,即被称为归一化的过程):
很明显,Softmax 的输出表征了不同类别之间的相对概率。可以清晰地看出,S1=0.8390,对应的概率最大,则可以更清晰地判断预测为第 1 类的可能性更大。
利用 RNN 对于某个序列的时刻t,它的词向量输出概率为 p(xt|x1, x2, …, xt-1),则 Softmax 层每个神经元的计算如下:
- ht 是当前第 t 个位置的隐藏状态,它与上一时刻的状态及当前输入有关,即 ht=f(ht-1,xt);
- t 表示文本词典中的第 t 个词对应的下标;
- xt 表示词典中第 t 个词;
- wt 为词权重参数。
即整个序列的生成概率为:
表示从第一个词到第 T 个词一次生成,产生这个词序列的概率。
Encoder-Decoder 模型如下图所示:
图 9 Encoder-Decoder模型
设有输入序列 x1,x2,…,xT,输出序列 y1,y2,…,yT,输入序列和输出序列的长度可能不同。那么就需要根据输入序列去得到输出序列可能输出的词概率,于是有下面的条件概率:x1,x2,…,xT 发生的情况下,y1,y2,…,yT 发生的概率等于 p(yt|v,y1,y2,…,yt-1) 连乘,如下式所示:
其中,v 表示 x1,x2,…,xT 对应的隐藏状态向量(输入中每个词的词向量),可以等同表示输入序列(模型依次生成 y1,y2,…,yT 的概率)。
此时,ht=f(ht-1,yt-1,v),Decode 中隐藏状态与上一时刻状态、上一时刻输出和状态 v 有关。于是 Decoder 的某一时刻的概率分布可用下式表示:
p(yt|v,y1,y2,…,yt-1)=g(ht,yt-1,v)对于训练样本,要做的就是在整个训练样本下,所有样本的 p(y1,y2,…,yT|x1,x2,…,xT) 和最大。对应的对数似然条件概率函数为:
使之最大化,θ 则是待确定的模型参数。
利用Seq2Seq进行时间序列预测
时间序列预测可以根据短期预测、长期预测,以及具体场景选用不同的方法。接下来通过一个实例来演示利用 Seq2Seq 进行时间序列预测。【实例】利用 Seq2Seq 进行时间序列预测。具体实现步骤为:
1) 导入所需要的包
import tensorflow as tf import numpy as np import random import math from matplotlib import pyplot as plt import os import copy
2) 数据准备
生成一系列没有噪声的样本,效果如下图所示:图 12 数据效果
plt.rcParams['font.family'] = ['sans-serif'] # 中文 plt.rcParams['axes.unicode_minus'] = False # 负号 x = np.linspace(0, 30, 105) y = 2 * np.sin(x) l1, = plt.plot(x[:85], y[:85], 'y', label='训练样本') l2, = plt.plot(x[85:], y[85:105], 'c--', label='测试样本') plt.legend(handles=[l1, l2], loc='upper left') plt.show()
为了模拟真实世界的数据,添加一些随机噪声,效果如下图所示:
图 13 添加随机噪声效果
train_y = y.copy() noise_factor = 0.5 train_y += np.random.randn(105) * noise_factor # 添加随机噪声 l1, = plt.plot(x[:85], train_y[:85], 'yo', label='训练样本') plt.plot(x[:85], y[:85], 'y:') l2, = plt.plot(x[85:], train_y[85:], 'co', label='测试样本') plt.plot(x[85:], y[85:], 'c:') plt.legend(handles=[l1, l2], loc='upper left') plt.show()
然后,设置输入输出的序列长度,并生成训练样本和测试样本:
import numpy as np
input_seq_len = 15
output_seq_len = 20
x = np.linspace(0, 30, 105)
train_data_x = x[:85]
def true_signal(x):
y = 2 * np.sin(x)
return y
def noise_func(x, noise_factor=1):
return np.random.randn(len(x)) * noise_factor
def generate_y_values(x):
return true_signal(x) + noise_func(x)
def generate_train_samples(x=train_data_x,
batch_size=10,
input_seq_len=input_seq_len,
output_seq_len=output_seq_len):
total_start_points = len(x) - input_seq_len - output_seq_len
start_x_idx = np.random.choice(range(total_start_points), batch_size)
input_seq_x = [x[i:(i + input_seq_len)] for i in start_x_idx]
output_seq_x = [x[(i + input_seq_len):(i + input_seq_len + output_seq_len)] for i in start_x_idx]
input_seq_y = [generate_y_values(x) for x in input_seq_x]
output_seq_y = [generate_y_values(x) for x in output_seq_x]
return np.array(input_seq_y), np.array(output_seq_y)
input_seq, output_seq = generate_train_samples(batch_size=10)
通过代码实现对含有噪声的数据进行可视化,效果如下图所示:图 14 含有噪声的数据可视化
results = []
for i in range(100):
temp = generate_y_values(x)
results.append(temp)
results = np.array(results)
for i in range(100):
l1, = plt.plot(results[i].reshape(105, -1), 'co', lw=0.1, alpha=0.05, label='噪声训练数据')
l2, = plt.plot(true_signal(x), 'm', label='隐藏层真实信号')
plt.legend(handles=[l1, l2], loc='lower left')
plt.show()
3) 建立基本的RNN模型
① 参数设置:#参数 learning_rate = 0.01 lambda_l2_reg = 0.003 #网络参数 input_seq_len = 15 #输入信号长度 output_seq_len = 20 #输出信号长度 hidden_dim = 64 #LSTM单元大小 input_dim = 1 #输入信号数 output_dim = 1 #输出信号数 num_stacked_layers = 2 #堆叠的LSTM层数 GRADIENT_CLIPPING = 2.5 #梯度裁剪,避免梯度爆炸
② 模型架构。此处的 Seq2Seq 模型基本与 Tensorflow 在 Github 中提供的模型一致。
import tensorflow as tf
from tensorflow.python.ops import variable_scope
from tensorflow.python.ops import rnn
import copy
def build_graph(feed_previous=False):
tf.reset_default_graph()
global_step = tf.Variable(
initial_value=0,
name="global_step",
trainable=False,
collections=[tf.GraphKeys.GLOBAL_STEP,
tf.GraphKeys.GLOBAL_VARIABLES]
)
weights = {
'out': tf.get_variable('Weights_out',
shape=[hidden_dim, output_dim],
dtype=tf.float32,
initializer=tf.truncated_normal_initializer()),
}
biases = {
'out': tf.get_variable('Biases_out',
shape=[output_dim],
dtype=tf.float32,
initializer=tf.constant_initializer(0.)),
}
with tf.variable_scope('Seq2seq'):
# 编码器输入
enc_inp = [
tf.placeholder(tf.float32, shape=(None, input_dim), name="inp_{}".format(t))
for t in range(input_seq_len)
]
# 解码器目标输出
target_seq = [
tf.placeholder(tf.float32, shape=(None, output_dim), name="y_{}".format(t))
for t in range(output_seq_len)
]
# GO token
dec_inp = [tf.zeros_like(target_seq[0], dtype=tf.float32, name="GO")] + target_seq[:-1]
with tf.variable_scope('LSTMCell'):
cells = []
for i in range(num_stacked_layers):
with tf.variable_scope('RNN_{}'.format(i)):
cells.append(tf.contrib.rnn.LSTMCell(hidden_dim))
cell = tf.contrib.rnn.MultiRNNCell(cells)
def _rnn_decoder(decoder_inputs,
initial_state,
cell,
loop_function=None,
scope=None):
"""用于 sequence-to-sequence 的 RNN 解码器"""
with variable_scope.variable_scope(scope or "rnn_decoder"):
state = initial_state
outputs = []
prev = None
for i, inp in enumerate(decoder_inputs):
if loop_function is not None and prev is not None:
with variable_scope.variable_scope("loop_function", reuse=True):
inp = loop_function(prev, i)
if i > 0:
variable_scope.get_variable_scope().reuse_variables()
output, state = cell(inp, state)
outputs.append(output)
if loop_function is not None:
prev = output
return outputs, state
def _basic_rnn_seq2seq(encoder_inputs,
decoder_inputs,
cell,
feed_previous,
dtype=tf.float32,
scope=None):
"""基本的 RNN sequence-to-sequence 模型"""
with variable_scope.variable_scope(scope or "basic_rnn_seq2seq"):
enc_cell = copy.deepcopy(cell)
_, enc_state = rnn.static_rnn(enc_cell, encoder_inputs, dtype=dtype)
if feed_previous:
return _rnn_decoder(decoder_inputs, enc_state, cell, _loop_function)
else:
return _rnn_decoder(decoder_inputs, enc_state, cell)
def _loop_function(prev, _):
"""将上一步输出映射为下一步输入"""
return tf.matmul(prev, weights['out']) + biases['out']
dec_outputs, dec_memory = _basic_rnn_seq2seq(
enc_inp,
dec_inp,
cell,
feed_previous=feed_previous
)
reshaped_outputs = [tf.matmul(i, weights['out']) + biases['out'] for i in dec_outputs]
# 训练损失
with tf.variable_scope('Loss'):
# L2 损失
output_loss = 0
for _y, _Y in zip(reshaped_outputs, target_seq):
output_loss += tf.reduce_mean(tf.pow(_y - _Y, 2))
# L2 正则化
reg_loss = 0
for tf_var in tf.trainable_variables():
if 'Biases_' in tf_var.name or 'Weights_' in tf_var.name:
reg_loss += tf.reduce_mean(tf.nn.l2_loss(tf_var))
loss = output_loss + lambda_l2_reg * reg_loss
# 优化器
with tf.variable_scope('Optimizer'):
optimizer = tf.contrib.layers.optimize_loss(
loss=loss,
learning_rate=learning_rate,
global_step=global_step,
optimizer='Adam',
clip_gradients=GRADIENT_CLIPPING)
saver = tf.train.Saver()
return dict(
enc_inp=enc_inp,
target_seq=target_seq,
train_op=optimizer,
loss=loss,
saver=saver,
reshaped_outputs=reshaped_outputs,
)
③ 模型训练。设置了 batch-size 为 16,迭代次数为 100:
import os
import tensorflow as tf
total_iterations = 100 # 原为 total_iteractions
batch_size = 16
KEEP_RATE = 0.5
train_losses = []
val_losses = []
x = np.linspace(0, 30, 105)
train_data_x = x[:85]
rnn_model = build_graph(feed_previous=False)
saver = tf.train.Saver()
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for i in range(total_iterations):
batch_input, batch_output = generate_train_samples(batch_size=batch_size)
feed_dict = {
rnn_model['enc_inp'][t]: batch_input[:, t].reshape(-1, input_dim)
for t in range(input_seq_len)
}
feed_dict.update({
rnn_model['target_seq'][t]: batch_output[:, t].reshape(-1, output_dim)
for t in range(output_seq_len)
})
_, loss_t = sess.run([rnn_model['train_op'], rnn_model['loss']], feed_dict)
print(loss_t)
temp_saver = rnn_model['saver']()
save_path = temp_saver.save(sess, os.path.join('./', 'univariate_ts_model0'))
print(" 检查点保存于:", save_path)
运行结果为:
57.3053
32.0934
52.935
37.3215
37.121
36.0812
24.0727
…
22.38
20.1875
检查点保存于:./univariate_ts_model0
4) 预测
将模型用在测试集中进行预测:
test_seq_input = true_signal(train_data_x[-15:])
rnn_model = build_graph(feed_previous=True)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
saver = rnn_model['saver']().restore(sess, os.path.join('./', 'univariate_ts_model0'))
feed_dict = {
rnn_model['enc_inp'][t]: test_seq_input[t].reshape(1, 1)
for t in range(input_seq_len)
}
feed_dict.update({
rnn_model['target_seq'][t]: np.zeros([1, output_dim])
for t in range(output_seq_len)
})
final_preds = sess.run(rnn_model['reshaped_outputs'], feed_dict)
final_preds = np.concatenate(final_preds, axis=1)
l1, = plt.plot(range(85), true_signal(train_data_x[:85]), label='训练truth')
l2, = plt.plot(range(85, 105), y[85:], 'yo', label='目标truth')
l3, = plt.plot(range(85, 105), final_preds.reshape(-1), 'ro', label='目标预测')
plt.legend(handles=[l1, l2, l3], loc='lower left')
plt.show()
运行程序,得到的预测效果如下图所示:图 15 预测效果