seq2seq模型结构及其实现(非常详细)
Seq2Seq 模型是一种将输入序列映射为输出序列的深度学习架构,广泛应用于机器翻译、文本摘要等序列生成任务。
Seq2Seq 模型包含两个主要部分:编码器(Encoder)和解码器(Decoder)。编码器负责将输入序列转换成一个固定长度的上下文向量,而解码器则根据这个上下文向量逐步生成输出序列。
在实际应用中,Transformer 模型因其强大的长距离依赖捕捉能力和高效的并行计算能力,成为 Seq2Seq 架构的首选实现方式之一。
本节首先探讨编码器-解码器的工作原理,随后介绍 Seq2Seq 结构的实际实现,包括如何构建编码器和解码器模块,并在深度学习框架中完成其端到端的训练。
Transformer 编码器-解码器架构原理图如下图所示:
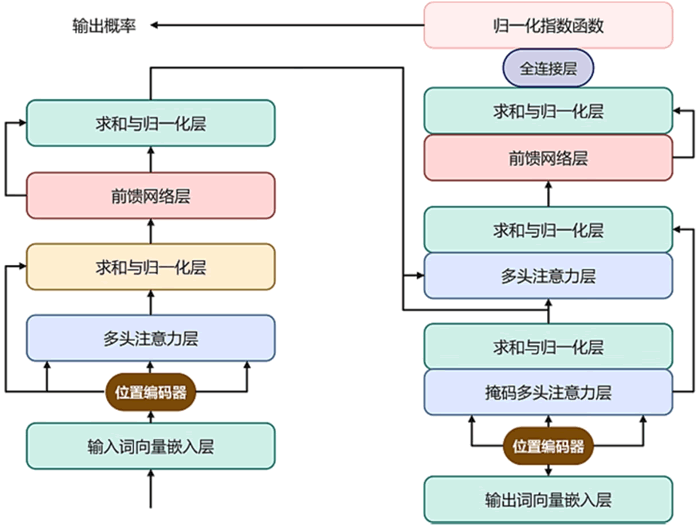
图 1 Transformer编码器-解码器架构图
这种结构常用于序列到序列任务,如机器翻译和文本摘要等。
Seq2Seq 经典架构如下图所示,模型读取一个输入句子“ABC”,并生成“WXYZ”作为输出句子。
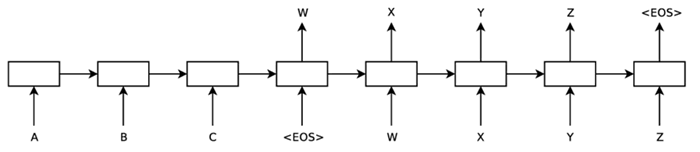
图 2 Seq2Seq 基本架构图
下面将实现一个完整的 Seq2Seq 结构,使用 LSTM 作为编码器和解码器单元,构建一个端到端的训练和评估过程,并确保代码具有可运行性和复杂性。
代码运行结果如下:
Seq2Seq 模型结构如下:
Seq2Seq 模型包含两个主要部分:编码器(Encoder)和解码器(Decoder)。编码器负责将输入序列转换成一个固定长度的上下文向量,而解码器则根据这个上下文向量逐步生成输出序列。
在实际应用中,Transformer 模型因其强大的长距离依赖捕捉能力和高效的并行计算能力,成为 Seq2Seq 架构的首选实现方式之一。
本节首先探讨编码器-解码器的工作原理,随后介绍 Seq2Seq 结构的实际实现,包括如何构建编码器和解码器模块,并在深度学习框架中完成其端到端的训练。
编码器-解码器工作原理
在编码器-解码器结构中:- 编码器通常由循环神经网络(RNN)、长短期记忆网络(LSTM)或门控循环单元(GRU)组成,它将输入逐步编码,并将最后一个隐藏状态作为整个输入序列的表示传递给解码器;
- 解码器也使用 RNN、LSTM 或 GRU 结构,从初始的上下文向量开始,结合上一时间步的输出,逐步生成目标序列。
Transformer 编码器-解码器架构原理图如下图所示:
图 1 Transformer编码器-解码器架构图
这种结构常用于序列到序列任务,如机器翻译和文本摘要等。
Seq2Seq结构实现
在 Seq2Seq 模型结构中,编码器将输入序列逐步编码为固定长度的上下文向量,再由解码器逐步生成目标序列,这种结构在机器翻译等任务中表现出色。Seq2Seq 经典架构如下图所示,模型读取一个输入句子“ABC”,并生成“WXYZ”作为输出句子。
图 2 Seq2Seq 基本架构图
下面将实现一个完整的 Seq2Seq 结构,使用 LSTM 作为编码器和解码器单元,构建一个端到端的训练和评估过程,并确保代码具有可运行性和复杂性。
import torch
import torch.nn as nn
import torch.optim as optim
import random
# 设置随机种子
random.seed(42)
torch.manual_seed(42)
# 定义编码器
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hidden_dim, n_layers, dropout):
super(Encoder, self).__init__()
self.embedding=nn.Embedding(input_dim, emb_dim)
self.rnn=nn.LSTM(emb_dim, hidden_dim, n_layers,
dropout=dropout, batch_first=True)
self.dropout=nn.Dropout(dropout)
def forward(self, src):
embedded=self.dropout(self.embedding(src))
outputs, (hidden, cell)=self.rnn(embedded)
return hidden, cell
# 定义解码器
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hidden_dim, n_layers, dropout):
super(Decoder, self).__init__()
self.embedding=nn.Embedding(output_dim, emb_dim)
self.rnn=nn.LSTM(emb_dim, hidden_dim, n_layers, dropout=dropout, batch_first=True)
self.fc_out=nn.Linear(hidden_dim, output_dim)
self.dropout=nn.Dropout(dropout)
def forward(self, trg, hidden, cell):
trg=trg.unsqueeze(1) # 增加时间步维度 (batch_size, 1)
embedded=self.dropout(
self.embedding(trg)) # (batch_size, 1, emb_dim)
output, (hidden, cell)=self.rnn(
embedded, (hidden, cell)) # output: (batch_size, 1, hidden_dim)
prediction=self.fc_out(
output.squeeze(1)) # (batch_size, output_dim)
return prediction, hidden, cell
# 定义Seq2Seq模型
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super(Seq2Seq, self).__init__()
self.encoder=encoder
self.decoder=decoder
self.device=device
def forward(self, src, trg, teacher_forcing_ratio=0.5):
batch_size=trg.shape[0]
trg_len=trg.shape[1]
trg_vocab_size=self.decoder.fc_out.out_features
outputs=torch.zeros(batch_size, trg_len,
trg_vocab_size).to(self.device)
# 编码器的输出作为解码器的初始隐藏状态
hidden, cell=self.encoder(src)
input=trg[:, 0] # 解码器的第一个输入是<sos>标记
# 逐步解码目标序列
for t in range(1, trg_len):
output, hidden, cell=self.decoder(input, hidden, cell)
outputs[:, t]=output
teacher_force=random.random() < teacher_forcing_ratio
top1=output.argmax(1) # 获取预测的最高分值
input=trg[:, t] if teacher_force else top1
return outputs
# 超参数设置
INPUT_DIM=10 # 输入词典大小
OUTPUT_DIM=10 # 输出词典大小
ENC_EMB_DIM=16 # 编码器嵌入维度
DEC_EMB_DIM=16 # 解码器嵌入维度
HIDDEN_DIM=32 # 隐藏层维度
N_LAYERS=2 # 编码器和解码器层数
ENC_DROPOUT=0.5 # 编码器dropout
DEC_DROPOUT=0.5 # 解码器dropout
DEVICE=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 实例化模型
encoder=Encoder(INPUT_DIM, ENC_EMB_DIM, HIDDEN_DIM, N_LAYERS, ENC_DROPOUT)
decoder=Decoder(OUTPUT_DIM, DEC_EMB_DIM, HIDDEN_DIM, N_LAYERS, DEC_DROPOUT)
model=Seq2Seq(encoder, decoder, DEVICE).to(DEVICE)
# 损失函数和优化器
optimizer=optim.Adam(model.parameters(), lr=0.001)
criterion=nn.CrossEntropyLoss()
# 训练模型
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss=0
for src, trg in iterator:
src=src.to(DEVICE)
trg=trg.to(DEVICE)
optimizer.zero_grad()
output=model(src, trg)
output_dim=output.shape[-1]
output=output[:, 1:].reshape(-1, output_dim)
trg=trg[:, 1:].reshape(-1)
loss=criterion(output, trg)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss/len(iterator)
# 模拟数据生成器
def generate_dummy_data(batch_size, seq_len, vocab_size):
src=torch.randint(1, vocab_size, (batch_size, seq_len))
trg=torch.randint(1, vocab_size, (batch_size, seq_len))
return src, trg
# 模拟训练
BATCH_SIZE=32
SEQ_LEN=5
VOCAB_SIZE=10
N_EPOCHS=5
CLIP=1
for epoch in range(N_EPOCHS):
src, trg=generate_dummy_data(BATCH_SIZE, SEQ_LEN, VOCAB_SIZE)
iterator=[(src, trg)]
train_loss=train(model, iterator, optimizer, criterion, CLIP)
print(f'Epoch: {epoch+1}, Train Loss: {train_loss:.4f}')
上述代码实现了完整的 Seq2Seq 结构,其中编码器将输入序列编码为隐藏状态和细胞状态,解码器在初始时接收编码器的输出并逐步生成目标序列。代码运行结果如下:
Epoch: 1, Train Loss: 2.3021 Epoch: 2, Train Loss: 2.2968 Epoch: 3, Train Loss: 2.2905 Epoch: 4, Train Loss: 2.2843 Epoch: 5, Train Loss: 2.2781结合前面讲解的内容,不难发现 Seq2Seq 模型实际上是处理序列到序列任务的深度学习结构,通过编码器-解码器框架,模型可以学习输入序列和输出序列之间的映射关系。这种架构在机器翻译、文本生成和问答系统等任务中应用广泛。
Seq2Seq 模型结构如下:
- 编码器:负责将输入序列编码为固定长度的上下文向量,常用 LSTM 或 GRU 层逐步处理输入序列,最后的隐藏状态包含了输入序列的关键信息并传递给解码器;
- 解码器:将编码器提供的上下文向量作为初始状态,从而生成输出序列。解码器同样由 LSTM 或 GRU 组成,通过逐步解码产生目标序列的各个标记。解码器的输入为上一个时间步的输出和编码器提供的隐藏状态,生成的结果依次填入目标序列;
- 教师强制(Teacher Forcing):为提高训练效率,解码器可在训练时选择使用真实的目标序列而非上一时间步的预测结果作为下一时间步的输入。
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: