Python绘制热图的多种方法(非常详细,附带实例)
热图(Heatmap)是一种用于可视化矩阵数据的图表类型。它通过使用颜色编码来表示数据的大小或值,以便在二维空间中显示数据的模式、趋势或关联性。
热图的优点是能够直观地显示数据的模式和趋势,并帮助观察数据的关联性和相似性。它常用于分析多变量数据、基因表达数据、市场趋势分析等。
在绘制和解读热图时,需确保颜色编码的准确并合理,以避免造成误解。当矩阵数据较大时,可以使用矩阵聚类和排序方法,以便更好地展示数据的模式和关联性;当矩阵数据具有缺失值时,可以使用适当的填充或插值方法进行处理,以确保图表的完整性和可靠性。
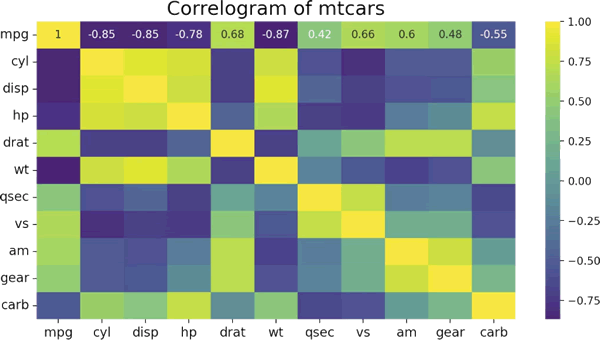
【实例 1】利用 Pandas、Seaborn 和 Matplotlib 库对汽车数据集进行处理和可视化分析。输入如下代码:
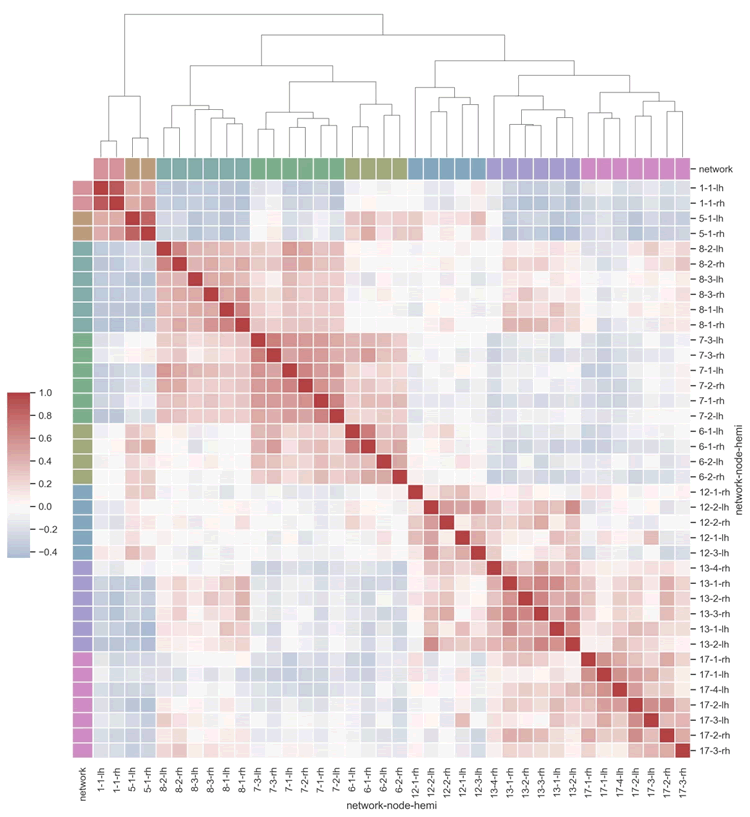
【实例 2】使用 Seaborn 库绘制聚类热图,展示脑网络之间的相关性,并使用分类调色板来标识不同的网络。输入如下代码:
输出的结果如下图所示:
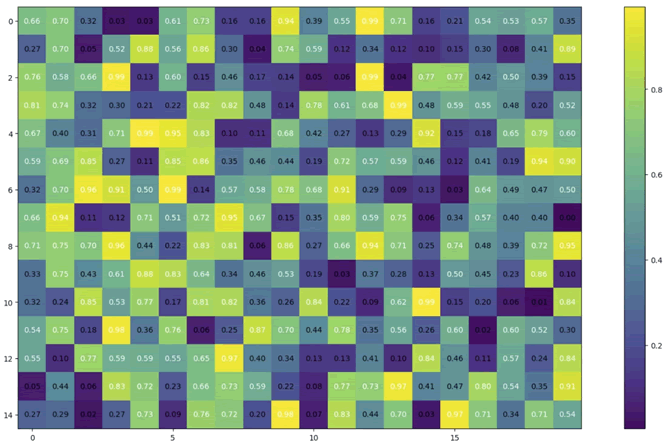
【实例 3】利用 mlxtend 绘制热图。输入如下代码:
输出的结果如下图所示:
【实例 4】利用 Proplot 库绘制热图。输入如下代码:
输出的结果如下图所示:
【实例 5】利用 mlxtend.plotting 库中的 heatmap() 函数和 Matplotlib 库来绘制热图,展示房价数据集中选定特征之间的相关性。输入如下代码:
输出的结果如下图所示:
【实例 6】使用 Matp lotlib 库绘制热图,展示不同农场主种植的蔬菜收成量。输入如下代码:
输出的结果如下图所示:
热图的优点是能够直观地显示数据的模式和趋势,并帮助观察数据的关联性和相似性。它常用于分析多变量数据、基因表达数据、市场趋势分析等。
在绘制和解读热图时,需确保颜色编码的准确并合理,以避免造成误解。当矩阵数据较大时,可以使用矩阵聚类和排序方法,以便更好地展示数据的模式和关联性;当矩阵数据具有缺失值时,可以使用适当的填充或插值方法进行处理,以确保图表的完整性和可靠性。
【实例 1】利用 Pandas、Seaborn 和 Matplotlib 库对汽车数据集进行处理和可视化分析。输入如下代码:
import pandas as pd # 导入 Pandas 库,用于数据处理和分析
import seaborn as sns # 导入 Seaborn 库,用于数据可视化
import matplotlib.pyplot as plt # 导入 Matplotlib 库,用于绘图
# 导入数据集
df = pd.read_csv("D:/DingJB/PyData/mtcars.csv") # 读取 mtcars.csv 的数据文件,并将数据存储在 df 中
# 删除非数值型的列
df_numeric = df.select_dtypes(include=['float64', 'int64']) # 选择数据集中的数值型列(包括 float64 和 int64 类型),并存储在 df_numeric 中
# 绘制热力图,显示数值型列之间的相关性,使用“viridis”颜色映射,将相关性系数标注在图上
plt.figure(figsize=(10, 5), dpi=200) # 创建图形对象
sns.heatmap(df_numeric.corr(),
xticklabels=df_numeric.corr().columns,
yticklabels=df_numeric.corr().columns,
cmap='viridis', center=0, annot=True) # 使用 Seaborn 绘制热力图
# 添加修饰
plt.title('correlogram of mtcars', fontsize=18) # 设置图形标题
plt.xticks(fontsize=12) # 设置 X 轴标签的字体大小为 12
plt.yticks(fontsize=12, rotation=0) # 设置 Y 轴标签的字体大小为 12
plt.show()
上述代码首先导入数据集并删除了非数值型列,然后利用 Seaborn 的 heatmap() 函数绘制了数值型列之间的相关性热力图,使用了 'viridis' 颜色映射,并标注了相关性系数。最后,通过 Matplotlib 添加了一些修饰,包括设置图形标题和调整标签字体大小。输出的结果如下图所示:【实例 2】使用 Seaborn 库绘制聚类热图,展示脑网络之间的相关性,并使用分类调色板来标识不同的网络。输入如下代码:
import pandas as pd
import seaborn as sns
sns.set_theme()
# 加载示例数据集
df = sns.load_dataset("brain_networks", header=[0, 1, 2], index_col=0)
# 选择网络的子集
used_networks = [1, 5, 6, 7, 8, 12, 13, 17]
used_columns = (df.columns.get_level_values("network")
.astype(int)
.isin(used_networks))
df = df.loc[:, used_columns]
# 创建一个分类调色板以识别网络
network_pal = sns.husl_palette(8, s=.45)
network_lut = dict(zip(map(str, used_networks), network_pal))
# 将调色板转换为向量,将在矩阵的侧面绘制
networks = df.columns.get_level_values("network")
network_colors = pd.Series(networks, index=df.columns).map(network_lut)
# 绘制完整的图形
g = sns.clustermap(df.corr(), center=0, cmap="vlag",
row_colors=network_colors, col_colors=network_colors,
dendrogram_ratio=(.1, .2),
cbar_pos=(.02, .32, .03, .2),
linewidths=.75, figsize=(12, 13))
g.ax_row_dendrogram.remove()
上述代码从示例数据集中加载了脑网络相关性数据后,选择了特定的网络子集,并根据这些网络创建了一个分类调色板。接下来,绘制了聚类热图,其中每个细胞的颜色表示对应网络之间的相关性,同时在行和列的侧面绘制了颜色条以标识不同的网络。输出的结果如下图所示:
【实例 3】利用 mlxtend 绘制热图。输入如下代码:
from mlxtend.plotting import heatmap import matplotlib.pyplot as plt import numpy as np import pandas as pd np.random.seed(19781101) # 固定随机数种子,以便结果可复现 some_array = np.random.random((15, 20)) heatmap(some_array, figsize=(20, 10)) plt.show()上述代码使用了 MLxtend 库的 heatmap() 函数来绘制热力图。首先,使用 NumPy 生成了一个随机的 15×20 的二维数组 some_array,然后调用 heatmap() 函数将其可视化为热力图,并设置图形的大小为 (20,10) 。
输出的结果如下图所示:
heatmap(some_array, figsize=(15,8),cell_values=False) plt.show()上述代码通过将 cell_values 参数设置为 False,不显示单元格的数值。输出的结果如下图所示:
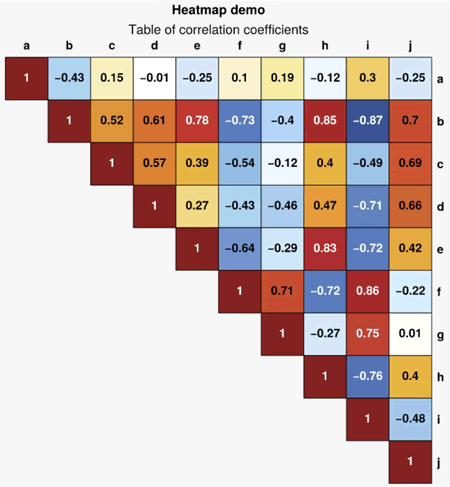
【实例 4】利用 Proplot 库绘制热图。输入如下代码:
import proplot as pplt
import numpy as np
import pandas as pd
# 生成协方差数据
state = np.random.RandomState(51423)
# 生成 10×10 的随机数据并进行累积和运算
data = state.normal(size=(10, 10)).cumsum(axis=0)
data = (data - data.mean(axis=0)) / data.std(axis=0) # 对数据进行标准化处理
data = (data.T @ data) / data.shape[0] # 计算协方差矩阵
# 将矩阵下三角部分的元素置为 NaN,使其不显示
data[np.tril_indices(data.shape[0], -1)] = np.nan
# 将数据转换为 DataFrame 格式,并设置行列索引
data = pd.DataFrame(data,
columns=list('abcdefghij'),
index=list('abcdefghij'))
# 绘制协方差矩阵热图
fig, ax = pplt.subplots(refwidth=4.5)
m = ax.heatmap(
data, cmap='ColdHot', vmin=-1, vmax=1, N=100,
lw=0.5, ec='k', labels=True, precision=2,
labels_kw={'weight': 'bold'}, clip_on=False)
ax.format(
suptitle='Heatmap demo',
title='Table of correlation coefficients',
xloc='top', yloc='right', yreverse=True,
ticklabelweight='bold',
alpha=0, linewidth=0, tickpad=4)
上述代码使用 ProPlot 库来绘制热力图。首先,生成了一个 10×10 的随机数据矩阵,并对其进行了累积和运算和标准化处理,然后计算了协方差矩阵。接下来,将矩阵下三角部分的元素置为 NaN,以便不显示。然后,将数据转换为 DataFrame 格式,并设置行列索引。最后,使用 ProPlot 库的 heatmap() 函数绘制了协方差矩阵的热力图,并设置了图形的标题、标签、颜色映射等属性。输出的结果如下图所示:
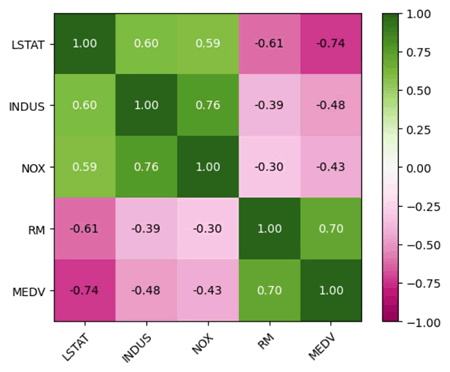
【实例 5】利用 mlxtend.plotting 库中的 heatmap() 函数和 Matplotlib 库来绘制热图,展示房价数据集中选定特征之间的相关性。输入如下代码:
from mlxtend.plotting import heatmap
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# 加载房价数据集,并设置列名
df = pd.read_csv('D:/DingJB/PyData/housing.data.txt',
header=None, sep=r'\s+')
df.columns = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD',
'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV']
# 选择感兴趣的列
cols = ['LSTAT', 'INDUS', 'NOX', 'RM', 'MEDV']
# 计算所选列的相关系数矩阵
corrmat = np.corrcoef(df[cols].values.T)
# 绘制热图并指定行名和列名
fig, ax = heatmap(corrmat,
column_names=cols,
row_names=cols,
cmap='PiYG')
# 将颜色条范围设置为 -1 ~ 1
for im in ax.get_images():
im.set_clim(-1, 1)
plt.show()
上述代码使用 Mlxtend 库中的 heatmap() 函数绘制了房价数据集中选定列的相关系数矩阵的热力图。首先,加载房价数据集,并设置列名。然后,选择感兴趣的列,并计算这些列的相关系数矩阵。接下来,调用 heatmap() 函数绘制热力图,并指定行名、列名和颜色映射。最后,将颜色条范围设置为 -1~1。输出的结果如下图所示:
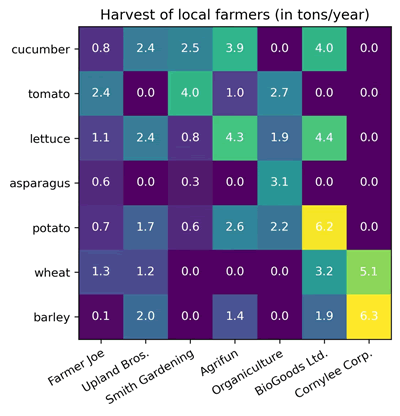
【实例 6】使用 Matp lotlib 库绘制热图,展示不同农场主种植的蔬菜收成量。输入如下代码:
import matplotlib.pyplot as plt
import numpy as np
vegetables = ["cucumber", "tomato", "lettuce", "asparagus",
"potato", "wheat", "barley"]
farmers = ["Farmer Joe", "Upland Bros.", "Smith Gardening",
"Agrifun", "Organiculture", "BioGoods Ltd.", "Cornylee Corp."]
harvest = np.array([
[0.8, 2.4, 2.5, 3.9, 0.0, 4.0, 0.0],
[2.4, 0.0, 4.0, 1.0, 2.7, 0.0, 0.0],
[1.1, 2.4, 0.8, 4.3, 1.9, 4.4, 0.0],
[0.6, 0.0, 0.3, 0.0, 3.1, 0.0, 0.0],
[0.7, 1.7, 0.6, 2.6, 2.2, 6.2, 0.0],
[1.3, 1.2, 0.0, 0.0, 0.0, 3.2, 5.1],
[0.1, 2.0, 0.0, 1.4, 0.0, 1.9, 6.3]
])
fig, ax = plt.subplots(figsize=(5, 5)) # 创建图形和轴对象
im = ax.imshow(harvest) # 绘制热图
# 显示所有刻度,并使用对应的列表条目进行标注
ax.set_xticks(np.arange(len(farmers)))
ax.set_yticks(np.arange(len(vegetables)))
ax.set_xticklabels(farmers)
ax.set_yticklabels(vegetables)
# 旋转刻度标签并设置对齐方式
plt.setp(ax.get_xticklabels(), rotation=30, ha="right", rotation_mode="anchor")
# 循环遍历数据维度并创建文本注释
for i in range(len(vegetables)):
for j in range(len(farmers)):
text = ax.text(j, i, harvest[i, j], ha="center", va="center", color="w")
# 设置标题和调整布局
ax.set_title("Harvest of local farmers (in tons/year)")
fig.tight_layout()
plt.show()
上述代码创建了一个 2D 数组 harvest,包含蔬菜的收成量,通过 imshow() 函数绘制了热图,对X轴和Y轴的刻度进行了设置和标注,对刻度标签进行了旋转和对齐处理,并在热图上添加了文本注释,表示收成量。最后,设置了标题并调整了布局。输出的结果如下图所示:
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: