Python绘制平行坐标图的多种方法(附带实例)
平行坐标图(Parallel Coordinate Plot)是一种用于可视化多个连续变量之间关系的图表。它通过在一个平行的坐标系中绘制多条平行的线段来表示每个数据点在各个变量上的取值。通过观察线段之间的交叉和趋势,可以揭示变量之间的关系。
平行坐标图方便观察和比较不同变量之间的趋势和关系,适用于可视化较多的连续变量。然而,当变量数量较多时,图形可能变得复杂且难以解读。因此,在使用平行坐标图时,应选择合适的变量和展示方式,以确保图表的可读性和有效地传达变量之间的关系。
在平行坐标图中,每个连续变量被表示为一个垂直的轴线,连接各个轴线的折线表示每个数据点。通过观察折线的形状和走势,可以推断出不同变量之间的关系和趋势。
平行坐标图适用于比较多个连续变量之间的关系和差异,观察变量之间的交叉效应和相互影响,检测异常值和离群点,以及识别数据聚类和模式。它具有可以同时可视化多个连续变量的优点,提供更全面的数据视图,发现变量之间的相关性和趋势,支持比较不同数据点之间的差异和相似性。
【实例 1】利用 Matplotlib 包绘制平行坐标图。输入如下代码:
【实例 2】利用 Matplotlib 包绘制平行坐标图。输入如下代码:
【实例 3】利用 Altair 包绘制平行坐标图。输入如下代码:
【实例 4】利用 Altair 包绘制平行坐标图。输入如下代码:
平行坐标图方便观察和比较不同变量之间的趋势和关系,适用于可视化较多的连续变量。然而,当变量数量较多时,图形可能变得复杂且难以解读。因此,在使用平行坐标图时,应选择合适的变量和展示方式,以确保图表的可读性和有效地传达变量之间的关系。
在平行坐标图中,每个连续变量被表示为一个垂直的轴线,连接各个轴线的折线表示每个数据点。通过观察折线的形状和走势,可以推断出不同变量之间的关系和趋势。
平行坐标图适用于比较多个连续变量之间的关系和差异,观察变量之间的交叉效应和相互影响,检测异常值和离群点,以及识别数据聚类和模式。它具有可以同时可视化多个连续变量的优点,提供更全面的数据视图,发现变量之间的相关性和趋势,支持比较不同数据点之间的差异和相似性。
【实例 1】利用 Matplotlib 包绘制平行坐标图。输入如下代码:
# 导入绘制平行坐标图所需的库
from pandas.plotting import parallel_coordinates
import matplotlib.pyplot as plt
# 导入鸢尾花数据集
from sklearn import datasets
import pandas as pd
# 载入鸢尾花数据集
iris = datasets.load_iris()
# 将数据集转换为DataFrame格式,仅保留前4个特征,并为列命名
X = pd.DataFrame(iris.data[:, :4],
columns=['sepal length', 'sepal width', 'petal length', 'petal width'])
X['class'] = iris.target
# 添加鸢尾花的类别列
parallel_coordinates(X, 'class')
# 绘制平行坐标图
plt.show()
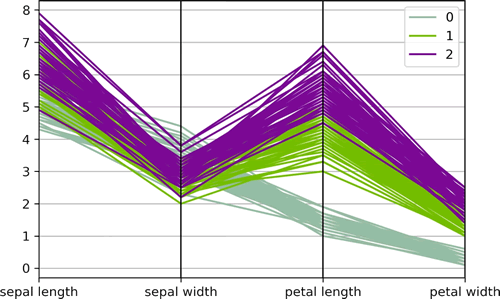
上述代码使用 Pandas 库的 parallel_coordinates() 函数绘制了平行坐标图,展示了鸢尾花数据集中 4 个特征在不同类别下的分布情况。输出的结果如下图所示:【实例 2】利用 Matplotlib 包绘制平行坐标图。输入如下代码:
from pandas.plotting import parallel_coordinates
import pandas as pd
import matplotlib.pyplot as plt
df_final = pd.read_csv("D:/DingJB/PyData/diamonds_filter.csv")
# 导入数据
# 绘制平行坐标图
plt.figure(figsize=(10, 6), dpi=200)
parallel_coordinates(df_final, 'cut', colormap='Dark2')
# 设置边框透明度
plt.gca().spines["top"].set_alpha(0)
plt.gca().spines["bottom"].set_alpha(.3)
plt.gca().spines["right"].set_alpha(0)
plt.gca().spines["left"].set_alpha(.3)
plt.title('Parallel Coordinated of Diamonds', fontsize=18)
# 设置标题
plt.grid(alpha=0.3)
# 设置网格线透明度
plt.xticks(fontsize=12)
# 设置X轴刻度标签字体大小
plt.yticks(fontsize=12)
# 设置Y轴刻度标签字体大小
plt.show()
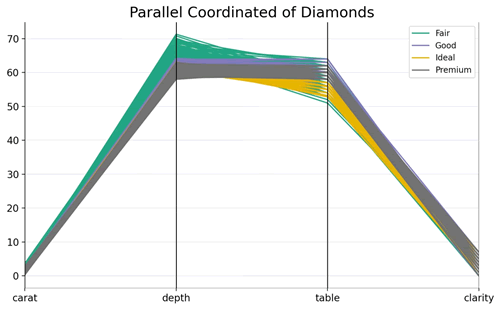
上述代码利用 Pandas 库的 parallel_coordinates() 函数绘制了平行坐标图,展示了钻石数据集中不同切割质量下各个特征的分布情况。输出的结果如下图所示。【实例 3】利用 Altair 包绘制平行坐标图。输入如下代码:
import altair as alt
from vega_datasets import data
from altair import datum
source = data.iris() # 加载鸢尾花数据集
# 创建图表,并进行数据转换
alt.Chart(source).transform_window(
index='count()' # 在数据集中添加一个索引列,用于绘制多条线
).transform_fold(
['petalLength', 'petalWidth', 'sepalLength', 'sepalWidth'] # 将特征列展开成长格式,以便进行后续处理
).transform_joinaggregate(
min='min(value)', # 计算每个特征的最小值
max='max(value)', # 计算每个特征的最大值
groupby=['key'] # 按照特征名称分组
).transform_calculate(
minmax_value=(datum.value - datum.min) / (datum.max - datum.min), # 计算每个特征的最小-最大归一化值
mid=(datum.min + datum.max) / 2 # 计算每个特征的中间值
).mark_line().encode(
x='key:N', # X轴为特征名称
y='minmax_value:Q', # Y轴为最小-最大归一化值
color='species:N', # 颜色编码为鸢尾花的类别
detail='index:N', # 详细编码为索引列,用于绘制多条线
opacity=alt.value(0.5) # 设置线条透明度
).properties(width=500) # 设置图表宽度为500像素
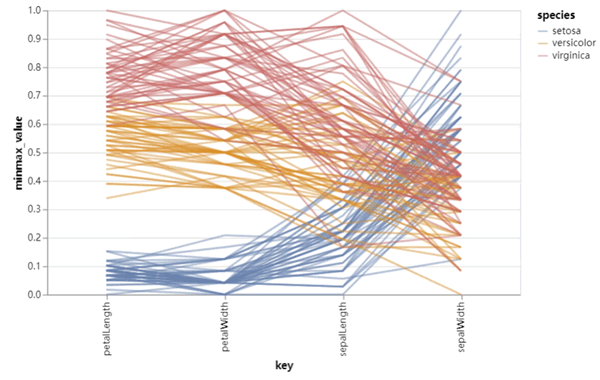
上述代码使用 Altair 库创建了一个图表,展示了鸢尾花数据集中各个特征的最小-最大归一化值的变化情况,并根据鸢尾花的类别进行了颜色编码。输出的结果如下图所示。【实例 4】利用 Altair 包绘制平行坐标图。输入如下代码:
import altair as alt
from vega_datasets import data
source = data.iris()
# 载入数据集
# 创建图表,进行窗口转换
alt.Chart(source).transform_window(
index='count()'
# 计算索引
).transform_fold(
['petalLength', 'petalWidth', 'sepalLength', 'sepalWidth']
# 折叠数据
).mark_line().encode(
x='key:N',
# X轴
y='value:Q',
# Y轴
color='species:N',
# 颜色编码
detail='index:N',
# 详细信息编码
opacity=alt.value(0.5)
# 设置透明度
).properties(width=500)
# 设置图表宽度
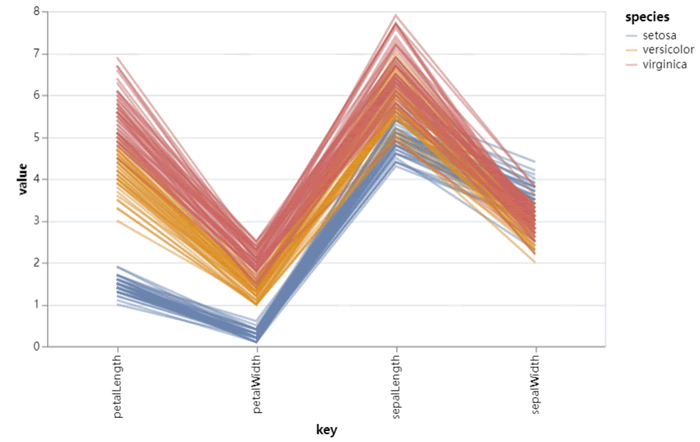
上述代码使用 Altair 库创建了一个平行坐标图,展示了鸢尾花数据集中各个特征的数值变化情况,并根据鸢尾花的类别进行了颜色编码。输出的结果如下图所示。 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: