Python绘制直方图(附带实例)
直方图(Histogram)是一种用于可视化连续变量的分布情况的统计图表。
直方图的主要特点是通过柱状图展示连续变量在每个区间内的观测频数。横轴表示连续变量的取值范围,纵轴表示频数或频率(频数除以总数)。每个柱子的高度表示该区间内的观测频数。
直方图常用于观察数据的分布情况,包括集中趋势、离散程度和偏态。它可以帮助我们识别数据的峰值、模式、异常值以及数据的整体形态。直方图是数据探索和分析的常见工具,为我们提供了对数据分布的直观认识,从而有助于做出推断和决策。
连续变量直方图用于显示给定变量的频率分布。基于类型变量对频率条进行分组,可以更好地了解连续变量和类型变量。类型变量直方图用于显示该变量的频率分布。通过对条形图进行着色,可以将分布与表示颜色的另一个类型变量相关联。
【实例 1】使用 Matplotlib 创建不同类型的直方图。输入如下代码:
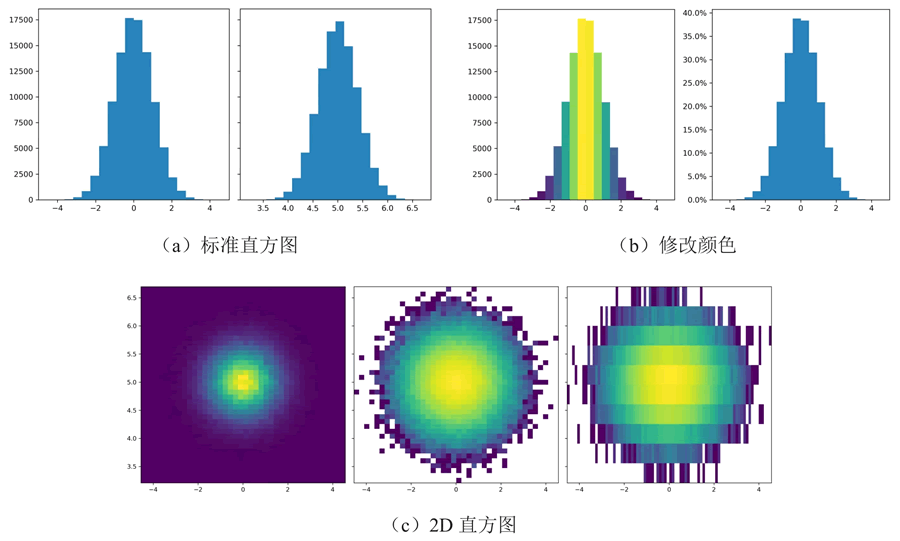
图 1 直方图
【实例 2】自行生成一个正态分布的样本数据,绘制直方图以及对应的拟合曲线。输入如下代码:
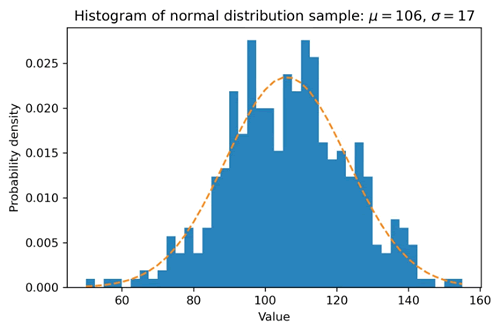
图 2 直方图以及对应的拟合曲线
【实例 3】绘制一幅叠直方图,用于显示不同车辆类型(class)发动机排量(displ)的分布情况,并为每个车辆类型分配不同的颜色。输入如下代码:
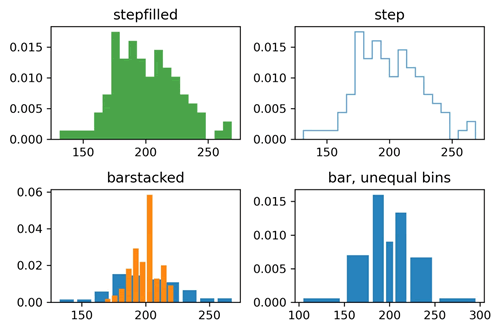
图 3 不同类型的直方图1
【实例 4】使用Matplotlib绘制不同类型的直方图,并对其进行堆叠和图例标注。输入如下代码:
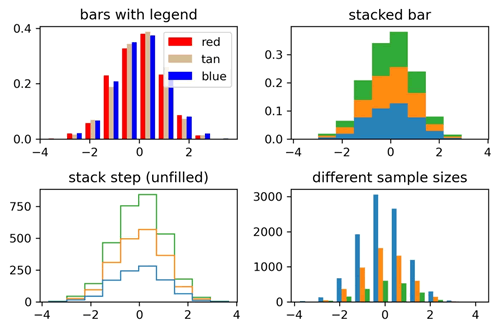
图 4 不同类型的直方图2
【实例 5】绘制堆叠直方图,用于显示不同车辆类型(class)的发动机排量(displ)的分布情况,并为每个车辆类型分配不同的颜色。输入如下代码:
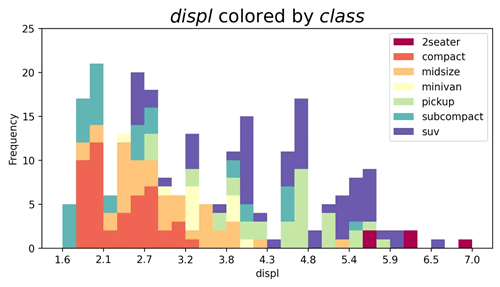
图 5 堆叠直方图1
【实例 6】使用 Matplotlib 库绘制堆叠直方图,展示不同车辆类型在发动机排量(displ)上的分布情况,不同颜色代表不同的车辆类型。输入如下代码:
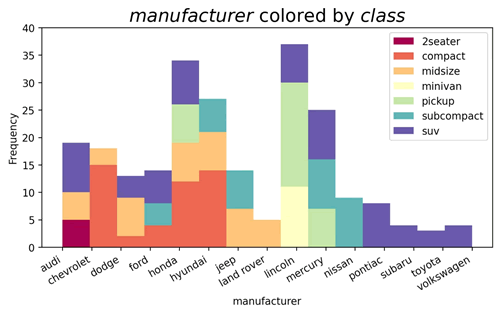
图 6 堆叠直方图2
直方图的主要特点是通过柱状图展示连续变量在每个区间内的观测频数。横轴表示连续变量的取值范围,纵轴表示频数或频率(频数除以总数)。每个柱子的高度表示该区间内的观测频数。
直方图常用于观察数据的分布情况,包括集中趋势、离散程度和偏态。它可以帮助我们识别数据的峰值、模式、异常值以及数据的整体形态。直方图是数据探索和分析的常见工具,为我们提供了对数据分布的直观认识,从而有助于做出推断和决策。
连续变量直方图用于显示给定变量的频率分布。基于类型变量对频率条进行分组,可以更好地了解连续变量和类型变量。类型变量直方图用于显示该变量的频率分布。通过对条形图进行着色,可以将分布与表示颜色的另一个类型变量相关联。
【实例 1】使用 Matplotlib 创建不同类型的直方图。输入如下代码:
import matplotlib.pyplot as plt
import numpy as np
from matplotlib import colors
from matplotlib.ticker import PercentFormatter
# 使用固定的种子创建随机数生成器,以便结果可复现
rng = np.random.default_rng(19781101)
N_points = 1000000
n_bins = 20
# 生成两个正态分布
dist1 = rng.standard_normal(N_points)
dist2 = 0.4 * rng.standard_normal(N_points) + 5
# 创建具有共享 Y 轴的子图
fig, axs = plt.subplots(1, 2, figsize=(8, 4), sharey=True, tight_layout=True)
# 使用 *bins* 关键字参数设置每个子图的箱数
axs[0].hist(dist1, bins=n_bins)
axs[1].hist(dist2, bins=n_bins)
# 创建新的图形,具有共享 Y 轴的子图
fig, axs = plt.subplots(1, 2, figsize=(8, 4), tight_layout=True)
# N 是每个箱中的计数,bins 是每个箱的下限
N, bins, patches = axs[0].hist(dist1, bins=n_bins)
# 通过高度对颜色进行编码,但用户可以使用任何标量
fracs = N / N.max()
# 将数据归一化为 0 - 1 的范围,以适应色彩映射的完整范围
norm = colors.Normalize(fracs.min(), fracs.max())
# 遍历对象,并相应地设置每个对象的颜色
for thisfrac, thispatch in zip(fracs, patches):
color = plt.cm.viridis(norm(thisfrac))
thispatch.set_facecolor(color)
# 将输入归一化为总计数
axs[1].hist(dist1, bins=n_bins, density=True)
# 格式化 Y 轴以显示百分比
axs[1].yaxis.set_major_formatter(PercentFormatter(xmax=1))
# 创建新的图形(2D 直方图),具有共享 X 轴和 Y 轴的子图
fig, axs = plt.subplots(1, 3, figsize=(15, 5), sharex=True, sharey=True,
tight_layout=True)
axs[0].hist2d(dist1, dist2, bins=40)
# 定义颜色的归一化
axs[1].hist2d(dist1, dist2, bins=40, norm=colors.LogNorm())
# 为每个轴定义自定义数量的箱
axs[2].hist2d(dist1, dist2, bins=(80, 10), norm=colors.LogNorm())
plt.show()
上述代码创建了不同类型的直方图,并自定义了颜色和比例尺。这些直方图可以帮助用户理解数据的分布和关系。输出的结果如下图所示。图 1 直方图
【实例 2】自行生成一个正态分布的样本数据,绘制直方图以及对应的拟合曲线。输入如下代码:
import matplotlib.pyplot as plt
import numpy as np
rng = np.random.default_rng(19781101) # 设置随机数生成器的种子
# 示例数据
mu = 106 # 分布的均值
sigma = 17 # 分布的标准差
x = rng.normal(loc=mu, scale=sigma, size=420)
num_bins = 42
fig, ax = plt.subplots() # 创建图形和坐标轴
n, bins, patches = ax.hist(x, num_bins, density=True) # 绘制数据的直方图
# 添加拟合线
y = (1 / (np.sqrt(2 * np.pi) * sigma)) * np.exp(-0.5 * (1 / sigma * (bins - mu)) ** 2)
ax.plot(bins, y, '--') # 绘制拟合线
ax.set_xlabel('Value') # 设置 X 轴标签
ax.set_ylabel('Probability density') # 设置 Y 轴标签
ax.set_title('Histogram of normal distribution sample:\n$\mu={:.0f}$, $\sigma={:.0f}$'.format(mu, sigma)) # 设置标题
# 调整间距以防止 Y 轴标签被裁剪
fig.tight_layout()
plt.show()
上述代码创建了一个正态分布的样本数据,并绘制了其直方图。随后根据样本数据拟合了正态分布的概率密度函数,并将拟合曲线绘制在直方图上。最后,对图形进行了标签设置,并调整了布局以避免标签被裁剪。输出的结果如下图所示。图 2 直方图以及对应的拟合曲线
【实例 3】绘制一幅叠直方图,用于显示不同车辆类型(class)发动机排量(displ)的分布情况,并为每个车辆类型分配不同的颜色。输入如下代码:
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(19781101) # 固定随机数种子,以便结果可复现
# 生成第 1 个正态分布
mu_x = 200
sigma_x = 25
x = np.random.normal(mu_x, sigma_x, size=100)
# 生成第 2 个正态分布
mu_w = 200
sigma_w = 10
w = np.random.normal(mu_w, sigma_w, size=100)
fig, axs = plt.subplots(nrows=2, ncols=2) # 创建 2×2 的子图
# 绘制步骤填充的直方图
axs[0, 0].hist(x, 20, density=True, histtype='stepfilled', facecolor='g', alpha=0.75)
axs[0, 0].set_title('stepfilled')
# 绘制步骤的直方图
axs[0, 1].hist(x, 20, density=True, histtype='step', facecolor='g', alpha=0.75)
axs[0, 1].set_title('step')
# 绘制堆叠的直方图
axs[1, 0].hist(x, density=True, histtype='barstacked', rwidth=0.8)
axs[1, 0].hist(w, density=True, histtype='barstacked', rwidth=0.8)
axs[1, 0].set_title('barstacked')
# 创建直方图,并提供不等间距的箱体边界
bins = [100, 150, 180, 195, 205, 220, 250, 300]
axs[1, 1].hist(x, bins, density=True, histtype='bar', rwidth=0.8)
axs[1, 1].set_title('bar, unequal bins')
fig.tight_layout() # 调整布局以避免重叠
plt.show()
上述代码创建了 2×2 个子图,分别用于展示阶梯填充的直方图、阶梯的直方图、堆叠的直方图以及提供了不等间距箱体边界的直方图。这些直方图的不同类型和参数可以帮助用户更好地理解数据的分布情况。输出的结果如下图所示。图 3 不同类型的直方图1
【实例 4】使用Matplotlib绘制不同类型的直方图,并对其进行堆叠和图例标注。输入如下代码:
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(19781101) # 固定随机数种子,以便结果可复现
n_bins = 10
x = np.random.randn(1000, 3)
fig, (ax0, ax1), (ax2, ax3) = plt.subplots(nrows=2, ncols=2) # 创建 2x2 的子图
colors = ['red', 'tan', 'blue'] # 定义颜色列表
# 绘制带有图例的直方图
ax0.hist(x, n_bins, density=True, histtype='bar', color=colors, label=colors)
ax0.legend(prop={'size': 10})
ax0.set_title('bars with legend')
# 绘制堆叠的直方图
ax1.hist(x, n_bins, density=True, histtype='bar', stacked=True)
ax1.set_title('stacked bar')
# 绘制堆叠的步骤直方图(未填充)
ax2.hist(x, n_bins, histtype='step', stacked=True, fill=False)
ax2.set_title('stack step (unfilled)')
# 绘制不同样本大小的多个直方图
x_multi = [np.random.randn(n) for n in [10000, 5000, 2000]]
ax3.hist(x_multi, n_bins, histtype='bar')
ax3.set_title('different sample sizes')
fig.tight_layout() # 调整布局以避免重叠
plt.show()
上述代码展示了 4 种不同的直方图类型:带有图例的直方图、堆叠的直方图、堆叠的步骤直方图(未填充)以及不同样本大小的多个直方图。这些直方图的不同参数和特性可以帮助用户更好地理解数据的分布情况。输出的结果如下图所示。图 4 不同类型的直方图2
【实例 5】绘制堆叠直方图,用于显示不同车辆类型(class)的发动机排量(displ)的分布情况,并为每个车辆类型分配不同的颜色。输入如下代码:
import pandas as pd # 导入 Pandas 库并简写为 pd
import numpy as np # 导入 NumPy 库并简写为 np
import matplotlib.pyplot as plt # 导入 Matplotlib.pyplot 库并简写为 plt
# 导入数据
df = pd.read_csv("D:/DingJB/PyData/mpg_ggplot2.csv") # 读取数据并存入 DataFrame 对象 df 中
x_var = 'displ' # 指定 X 轴变量为发动机排量
groupby_var = 'class' # 指定分组变量为车辆类型
# 根据分组变量对数据进行分组并聚合
df_agg = df.loc[:, [x_var, groupby_var]].groupby(groupby_var)
vals = [df[x_var].values.tolist() for i, df in df_agg] # 提取每个分组的数据值
plt.figure(figsize=(8, 4), dpi=250) # 设置图形大小
# 使用色谱来为每个分组分配颜色
colors = [plt.cm.Spectral(i / float((len(vals) - 1)) for i in range(len(vals))]
# 绘制堆叠直方图
n, bins, patches = plt.hist(vals, 30, stacked=True, density=False,
color=colors[:len(vals)])
# 图例
legend_dict = {group: col for group, col in zip(
np.unique(df[groupby_var]).tolist(), colors[:len(vals)])} # 添加图例
plt.legend(legend_dict)
# 图形修饰
plt.title(f"${x_var}$ colored by ${groupby_var}$", fontsize=18) # 设置标题
plt.xlabel(x_var) # 设置 X 轴标签
plt.ylabel("Frequency") # 设置 Y 轴标签
plt.ylim(0, 25) # 设置 Y 轴范围
plt.xticks(ticks=bins[:3], # 设置 X 轴刻度和标签
labels=[round(b, 1) for b in bins[:3]])
plt.show()
上述代码从 CSV 文件中读取数据,并根据指定的车辆类型(class)对发动机排量(displ)进行分组。最终绘制一个堆叠直方图,将不同车辆类型的发动机排量分布显示在同一个图形中,并为每个车辆类型分配了不同的颜色。图例显示每种颜色对应的车辆类型。代码最后对图形进行了修饰,包括添加标题、坐标轴标签以及设置坐标轴范围和刻度等。输出的结果如下图所示。图 5 堆叠直方图1
【实例 6】使用 Matplotlib 库绘制堆叠直方图,展示不同车辆类型在发动机排量(displ)上的分布情况,不同颜色代表不同的车辆类型。输入如下代码:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv("D:/DingJB/PyData/mpg_ggplot2.csv") # 导入数据
# 准备数据
x_var = 'manufacturer' # X 轴变量为制造商
groupby_var = 'class' # 分组变量为车辆类型
# 根据分组变量对数据进行分组并聚合
df_agg = df.loc[:, [x_var, groupby_var]].groupby(groupby_var)
# 提取每个分组的数据值
vals = [df[x_var].values.tolist() for i, df in df_agg]
plt.figure(figsize=(8, 5), dpi=250) # 创建图形
# 使用色谱来为每个分组分配颜色
colors = [plt.cm.Spectral(i / float((len(vals) - 1)) for i in range(len(vals))]
# 绘制堆叠直方图,其中,n 为 bin 的数量,bins 为 bin 的边界值,patches 为 patch 对象
n, bins, patches = plt.hist(vals, df[x_var].unique().__len__(), stacked=True, density=False, color=colors[:len(vals)])
# 创建一个字典,将分组变量与对应的颜色关联起来
legend_dict = {group: col for group, col in zip(
np.unique(df[groupby_var]).tolist(), colors[:len(vals)])}
plt.legend(legend_dict)
# 图形修饰
plt.title(f"${x_var}$ colored by ${groupby_var}$", fontsize=18)
plt.xlabel(x_var)
plt.ylabel("Frequency")
plt.ylim(0, 40)
plt.xticks(ticks=np.arange(len(np.unique(df[x_var]))),
labels=np.unique(df[x_var]).tolist(),
rotation=30, horizontalalignment='right')
plt.show()
上述代码根据车辆类型(class)对制造商(manufacturer)进行分组,并绘制了一个堆叠直方图,展示了不同制造商的车辆分布,并用不同颜色表示不同类型的车辆。图例显示了每种颜色对应的车辆类型。最后,对图形进行了修饰,包括添加标题、坐标轴标签以及设置坐标轴范围和刻度。输出的结果如下图所示。图 6 堆叠直方图2
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: