时序数据库是什么(非常详细)
时序数据库的全称为时间序列数据库,主要指用于处理带时间标签(按照时间的顺序进行变化,即时间序列化)的数据。带时间标签的数据也称为时间序列数据。
时间序列数据主要是各类实时监测、检查与分析设备所采集或产生的数据,这些数据的典型特点是:
下面是 DB-Engines Ranking 发布的时序数据库流行度排行榜:
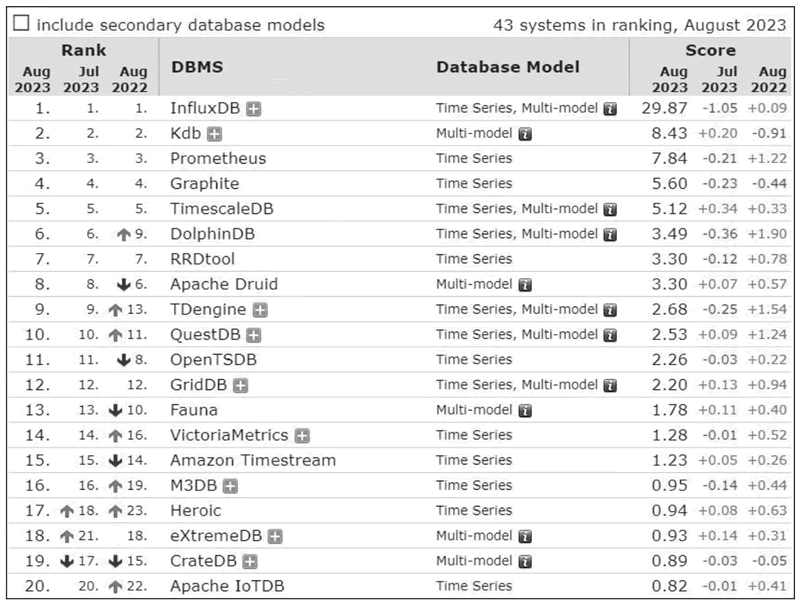
图 1 时序数据库排行榜(部分)
作为代表的数据库 RRDtool Whisper 是固定大小的数据库,可以快速存储数值型数据,但是这类数据库的读性能比较弱,缺乏针对时间的特殊优化。
随着大数据的发展,时序数据出现爆发式增长。不只是监控系统,其他系统也有更多处理时序数据的需求。2011 年出现了以 OpenTSDB、KairosDB 为代表的基于分布式存储的时序数据库,这类时序数据库在继承通用存储优势的基础上,针对时间进行优化。比如:
这类专用于时序数据的数据库比第一代时序数据库在存储和查询性能上有明显提高,但也有许多不足,比如低效的全局 UID 机制、依赖 Hadoop 和 HBase 环境、部署及维护成本高等。
随着微服务的发展,时序数据库在高速发展,OpenTSDB 存在的不足促进了低成本的垂直型时序数据库的诞生。以 IfluxDB 为代表的垂直型时序数据库成为时序数据库市场的主流,对时序数据具备更高效的存储读取等数据处理能力。
InfluxDB 的单机版本采用类似日志结构合并树的时间结构合并树存储结构,引入了时间线的概念,根据时间特征对数据实现了很好的分类,减少了冗余存储,提高了数据压缩率。相对于 OpenTSDB 需要配置 Java 环境和 HBase 环境,InfluxDB 基于 Goland 语言,并且使用类 SQL 语言的 InfluxQL,更易于开发人员使用。
写多读少。与时序数据相关的 95%~99% 的操作是写操作,说明时序数据是典型的写多读少数据。这与其数据特性相关,例如监控数据,监控项可能很多,但是真正读取的数据可能比较少,人们通常只关心几个特定的关键指标或者特定场景的数据。
实时写入最近生成的数据,无更新。时序数据的写入是实时的,且每次写入都是最近生成的数据。这与其数据生成的特点相关,因为数据生成是随着时间推进来进行的,而新生成的数据会实时地进行写入。
已写入数据无更新。在时间维度上,随着时间的推进,每次写入的数据都是新数据,不存在旧数据的更新。
时间序列数据主要是各类实时监测、检查与分析设备所采集或产生的数据,这些数据的典型特点是:
- 产生频率高:每一个监测点一秒可产生多条数据;
- 严重依赖采集时间:每一条数据均要对应唯一的时间;
- 测点多且数据量大:常规的实时监测系统均有成千上万个的监测点,监测点每秒都会产生数据。
下面是 DB-Engines Ranking 发布的时序数据库流行度排行榜:
图 1 时序数据库排行榜(部分)
时序数据库的发展历程
时序数据库虽然近几年才进入大众视野,但其发展可以追溯到 20 世纪 90 年代。当时监控领域出现了时序数据存储的需求,由此出现了第一代时序数据库。作为代表的数据库 RRDtool Whisper 是固定大小的数据库,可以快速存储数值型数据,但是这类数据库的读性能比较弱,缺乏针对时间的特殊优化。
随着大数据的发展,时序数据出现爆发式增长。不只是监控系统,其他系统也有更多处理时序数据的需求。2011 年出现了以 OpenTSDB、KairosDB 为代表的基于分布式存储的时序数据库,这类时序数据库在继承通用存储优势的基础上,针对时间进行优化。比如:
- OpenTSDB 底层依赖 HBase 集群存储,根据时序的特征对数据进行压缩,节省存储空间;
- 用时序守护进程进行读/写处理,对时序数据的常用查询进行封装,提供数据聚合、过滤等操作。
这类专用于时序数据的数据库比第一代时序数据库在存储和查询性能上有明显提高,但也有许多不足,比如低效的全局 UID 机制、依赖 Hadoop 和 HBase 环境、部署及维护成本高等。
随着微服务的发展,时序数据库在高速发展,OpenTSDB 存在的不足促进了低成本的垂直型时序数据库的诞生。以 IfluxDB 为代表的垂直型时序数据库成为时序数据库市场的主流,对时序数据具备更高效的存储读取等数据处理能力。
InfluxDB 的单机版本采用类似日志结构合并树的时间结构合并树存储结构,引入了时间线的概念,根据时间特征对数据实现了很好的分类,减少了冗余存储,提高了数据压缩率。相对于 OpenTSDB 需要配置 Java 环境和 HBase 环境,InfluxDB 基于 Goland 语言,并且使用类 SQL 语言的 InfluxQL,更易于开发人员使用。
时序数据库的核心特点
1) 数据写入的特点
写入平稳、持续、高并发高吞吐。时序数据的写入是比较平稳的,这点与应用数据不同。应用数据通常与应用的访问量成正比,其访问量通常存在波峰/波谷。时序数据的产生通常以一个固定的时间频率产生,不会受其他因素的制约。数据生成的速度是相对比较平稳的。写多读少。与时序数据相关的 95%~99% 的操作是写操作,说明时序数据是典型的写多读少数据。这与其数据特性相关,例如监控数据,监控项可能很多,但是真正读取的数据可能比较少,人们通常只关心几个特定的关键指标或者特定场景的数据。
实时写入最近生成的数据,无更新。时序数据的写入是实时的,且每次写入都是最近生成的数据。这与其数据生成的特点相关,因为数据生成是随着时间推进来进行的,而新生成的数据会实时地进行写入。
已写入数据无更新。在时间维度上,随着时间的推进,每次写入的数据都是新数据,不存在旧数据的更新。
2) 数据存储的特点
1) 数据量大
从监控数据为例,如果我们采集监控数据的时间间隔是 1s,那么一个监控项每天会产生 86400 个时间点。若有 10000 个监控项,则一天就会产生 864000000 个数据点。在物联网场景下,这个数字会更大,每天采集的数据的规模是 TB 级甚至是 PB 级的。2) 冷热分明
时序数据有非常典型的冷热特征,越是历史的数据,被查询和分析的概率越低。3) 具有时效性
时序数据通常会有一个保存周期,超过这个保存周期的数据可以被认为是失效的,可以进行回收。这么做一方面是因为越是历史的数据,可利用的价值越低;另一方面是为了节省存储成本,低价值的数据可以被清理。4) 多精度数据存储
在查询的特点中我们提到时序数据出于存储成本和查询效率的考虑,会需要一个多精度的查询,同样时序数据库也需要一个多精度数据的存储。时序数据库的应用场景
时序数据库的应用场景在物联网、互联网等领域应用广泛,下面列举了一些时序数据库的应用场景:- 公共安全:上网记录、通话记录、个体追踪、区间筛选;
- 电力行业:智能电表、电网、发电设备的集中监测;
- 互联网:服务器/应用监测、用户访问日志、广告点击日志;
- 物联网:电梯、锅炉、水表等各种联网设备的监测;
- 交通行业:实时路况、路口流量的监测;
- 金融行业:交易记录、存取记录,以及相关设备的监测。
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: