Python read_excel():读取Excel文件(附带实例)
Python 程序中读取 Excel 文件,主要使用 pandas 模块的 read_excel() 方法,语法如下:
其范围包括头和尾:
下面通过快速示例,详细介绍如何读取 Excel 文件。
【实例 2】读取指定 Sheet 页的数据。
除了指定 Sheet 页的名字,还可以指定 Sheet 页的顺序,从 0 开始。例如,sheet_name=0 表示第一个 Sheet 页的数据,sheet_name=1 表示第二个 Sheet 页的数据,以此类推。
如果不指定 sheet_name 参数,则默认读取第一个 Sheet 页的数据。
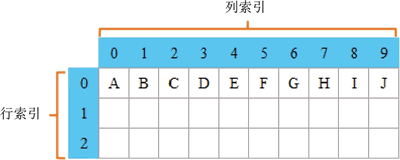
图 1 DataFrame行列索引示意图
如果通过指定行索引读取 Excel 文件,则需要设置 index_col 参数。下面将“买家名”作为行索引(位于第 0 列)读取 Excel 文件,程序代码如下:
如果通过指定列索引读取 Excel 文件,则需要设置 header 参数,主要代码如下:
如果将数字指定为列索引,可以设置 header 参数为 None,主要代码如下:
那么,为什么要指定索引呢?因为通过索引可以快速检索数据,例如,通过 df3[0] 就可以快速检索到“买家名”这一列数据。
下面读取第 1 列数据(索引为 0),程序代码如下:
如果要读取多列数据,则可以在列表中指定多个值。例如,读取第 1 列和第 4 列数据,主要代码如下:
也可以指定列名称,主要代码如下:
pandas.read_excel(io, sheet_name=0, header=0, names=None, index_col=None, usecols=None, squeeze=False, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, na_values=None, keep_default_na=True, verbose=False, parse_dates=False, date_parser=None, thousands=None, comment=None, skipfooter=0, convert_float=True, mangle_dupe_cols=True, **kwds)主要参数说明:
- io:字符串,xls 或 xlsx 路径文件或类文件对象。
- sheet_name:None、字符串、整数、字符串列表或整数列表,默认值为 0。字符串为 Excel 工作表的名称;整数为索引,表示工作表的位置;字符串列表或整数列表用于请求多个工作表;为 None 时表示获取所有的工作表。参数值如下表所示。
| 值 | 说明 |
|---|---|
| sheet_name=0 | 将第一个 Sheet 页中的数据作为 DataFrame |
| sheet_name=1 | 将第二个 Sheet 页中的数据作为 DataFrame |
| sheet_name="Sheet1" | 将名为“Sheet1”的 Sheet 页中的数据作为 DataFrame |
| sheet_name=[0,1,'Sheet3'] | 将第一个、第二个和名为“Sheet3”的 Sheet 页中的数据作为 DataFrame |
- header:指定作为列名的行,默认值为 0,即读取第一行的值为列名。数据为除列名以外的数据;若数据不包含列名,则设置 header=None;
- names:默认值为 None,表示要使用的列名列表;
- index_col:指定列为索引列,默认值为 None,索引 0 是 DataFrame 的行标签;
-
usecols:int、list 或字符串,默认值为 None。
- 如果为 None,则解析所有列;
- 如果为 int,则解析最后一列;
- 如果为 list,则解析列表中的列;
- 如果为字符串,则解析 Excel 中特定字母的列和范围列表(例如“A:E”或“A,C,E:F”)。
其范围包括头和尾:
- squeeze:布尔值,默认值为 False,如果解析的数据只包含一列,则返回一个 Series 对象;
- dtype:列的数据类型名称或字典,默认值为 None。例如{'a':np.float64,'b':np.int32};
- skiprows:省略指定行数的数据,从第一行开始;
- skipfooter:省略指定行数的数据,从最后一行开始。
下面通过快速示例,详细介绍如何读取 Excel 文件。
Python常规读取Excel文件
【实例 1】读取 Excel 文件。下面使用 read_excel() 函数读取文件名为“data2.xlsx”的 Excel 文件,程序代码如下:
# 导入pandas模块
import pandas as pd
# 解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
# 读取Excel文件
df=pd.read_excel('../datas/data2.xlsx')
# 输出前5条数据
print(df.head())
运行程序,输出前 5 条数据,结果为:
买家名 买家实际支付金额 收货人姓名 教程名称
0 mrhy1 49.99 周某某 C语言入门教程
1 mrhy2 49.99 杨某某 C语言入门教程
2 mrhy3 49.99 刘某某 C语言入门教程
3 mrhy4 49.99 张某某 C语言入门教程
4 mrhy5 49.99 赵某某 Python基础教程
注意,如果读取的 Excel 文件是 .xls 类型的,则需要安装 xlrd 模块,否则程序会报错。Python读取指定的Sheet页
一个 Excel 文件包含多个 Sheet 页,通过设置 sheet_name 参数就可以读取指定 Sheet 页的数据。【实例 2】读取指定 Sheet 页的数据。
# 读取Excel文件 df = pd.read_excel(io='../datas/data2.xlsx', sheet_name='C语言') # 输出前5条数据 print(df.head())运行程序,运行结果会输出前 5 条数据。
除了指定 Sheet 页的名字,还可以指定 Sheet 页的顺序,从 0 开始。例如,sheet_name=0 表示第一个 Sheet 页的数据,sheet_name=1 表示第二个 Sheet 页的数据,以此类推。
如果不指定 sheet_name 参数,则默认读取第一个 Sheet 页的数据。
Python通过行列索引读取指定行列数据
DataFrame 是二维数据结构,因此它既有行索引,又有列索引。当导入 Excel 数据时,行索引会自动生成,如 0、1、2,而列索引则默认为第 0 行数据,如下图所示。图 1 DataFrame行列索引示意图
如果通过指定行索引读取 Excel 文件,则需要设置 index_col 参数。下面将“买家名”作为行索引(位于第 0 列)读取 Excel 文件,程序代码如下:
# 导入pandas模块
import pandas as pd
# 解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
df1 = pd.read_excel(io='../datas/data2.xlsx', index_col=0) # 设置“买家名”为行索引
print(df1.head()) # 输出前5条数据
如果通过指定列索引读取 Excel 文件,则需要设置 header 参数,主要代码如下:
df2 = pd.read_excel(io='../datas/data2.xlsx', header=1) # 设置第 1 行为列索引
如果将数字指定为列索引,可以设置 header 参数为 None,主要代码如下:
df3 = pd.read_excel(io='../datas/data2.xlsx', header=None) # 列索引为数字
那么,为什么要指定索引呢?因为通过索引可以快速检索数据,例如,通过 df3[0] 就可以快速检索到“买家名”这一列数据。
Python读取指定列数据
一个 Excel 文件中往往包含多列数据,如果只需要其中的几列,则可以通过 usecols 参数指定需要的列,从 0 开始(0 表示第 1 列,以此类推)。下面读取第 1 列数据(索引为 0),程序代码如下:
# 导入pandas模块
import pandas as pd
# 解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
# 通过指定列索引读取第1列数据(索引为0)
df1 = pd.read_excel(io='../datas/data2.xlsx', usecols=[0])
print(df1.head())
如果要读取多列数据,则可以在列表中指定多个值。例如,读取第 1 列和第 4 列数据,主要代码如下:
df1 = pd.read_excel(io='../datas/data2.xlsx', usecols=[0, 3])
也可以指定列名称,主要代码如下:
df1 = pd.read_excel(io='../datas/data2.xlsx', usecols=['买家名', '教程名称'])
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: