Python read_html():读取HTML网页数据(附带实例)
读取 HTML 网页数据主要使用 Pandas 的 read_html() 函数,该函数用于读取带有 table 标签的网页表格数据,语法如下:
这里需要说明一点,在使用 read_html() 函数前,首先要确定网页表格是否为 table 类型的,因为只有这种类型的网页表格才能通过 read_html() 函数获取到其中的数据。
下面介绍如何判断网页表格是否为 table 类型的,以“NBA球员薪资网页为例,用鼠标右键单击该网页中的表格,在弹出的菜单中选择“检查”,查看代码中是否含有表格标签 <table>……</table> 的字样,如下图所示,确定后再使用 read_html() 函数。
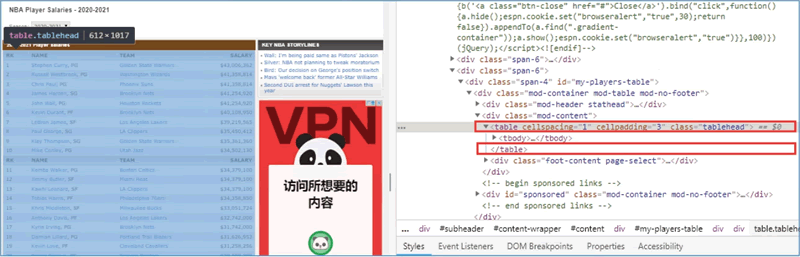
图 1 <table>……</table>表格标签
【实例 1】下面使用 read_html() 函数获取 NBA 球员薪资数据,程序代码如下:
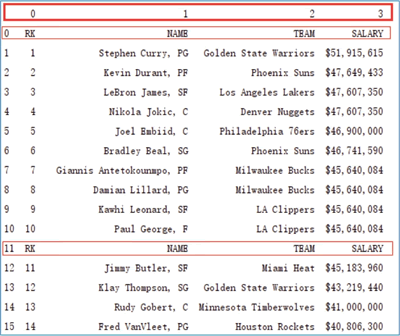
图 2 获取到的NBA球员薪资数据(部分数据)
从运行结果得知,首先数据中存在着一些无用的数据,如表头为数字 0、1、2、3 不能表明每列数据的作用,其次,数据存在重复的表头,如“RK”、“NAME”、“TEAM”和“SALARY”。
接下来进行数据清洗,首先去掉重复的表头数据,主要使用字符串函数 startswith(),遍历 DataFrame 对象的第 4 列(也就是索引为 3 的列),将以“$”字符开头的数据筛选出来,这样便去除了重复的表头,程序代码如下:
最后,重新赋予表头以说明每列的作用,方法是在数据导出为 Excel 文件时,通过 DataFrame 对象的 to_excel() 方法的 header 参数指定表头,程序代码如下:
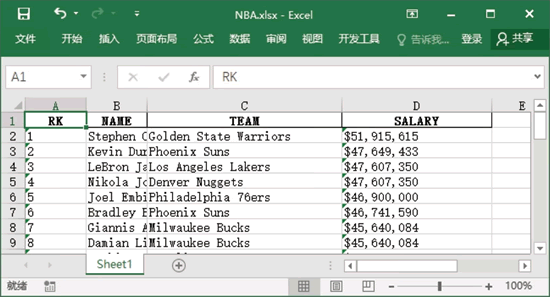
图 3 导出后的“NBA.xlsx”Excel文件
注意,运行程序如果出现 ImportError:lxml not found,please installit 错误提示信息,则需要安装 lxml 模块。另外需要注意的是,Pandas 从 1.4.0 本开始,DataFrame.append() 方法和 Series.append() 方法都被弃用,取而代之的是 _append() 方法。
pandas.read_html(io, match='.+', flavor=None, header=None, index_col=None, skiprows=None, attrs=None, parse_dates=False, thousands=',', encoding=None, decimal='.', converters=None, na_values=None, keep_default_na=True, displayed_only=True)主要参数说明:
- io:字符串,文件路径,也可以是 URL 链接。链接中不接受 https,可以尝试去掉 https 中的 s 后再读取;
- match:正则表达式,返回与正则表达式匹配的表格;
- flavor:解析器默认为“lxml”;
- header:指定列标题所在的行,列表为多重索引;
- index_col:指定行标题对应的列,列表为多重索引;
- encoding:字符串,默认为 None,表示文件的编码格式;
- 返回值:DataFrame 对象。
这里需要说明一点,在使用 read_html() 函数前,首先要确定网页表格是否为 table 类型的,因为只有这种类型的网页表格才能通过 read_html() 函数获取到其中的数据。
下面介绍如何判断网页表格是否为 table 类型的,以“NBA球员薪资网页为例,用鼠标右键单击该网页中的表格,在弹出的菜单中选择“检查”,查看代码中是否含有表格标签 <table>……</table> 的字样,如下图所示,确定后再使用 read_html() 函数。
图 1 <table>……</table>表格标签
【实例 1】下面使用 read_html() 函数获取 NBA 球员薪资数据,程序代码如下:
import pandas as pd
# 设置数据显示的编码格式为东亚宽度,以使列对齐
pd.set_option('display.unicode.east_asian_width', True)
# 设置数据显示的最大行数
pd.set_option('display.max_rows', 500)
# 创建空的DataFrame对象
df = pd.DataFrame()
# 创建空列表,以保持网页地址
url_list = []
# 获取网页地址,将地址保存在列表中
for i in range(1, 2):
# 网页地址字符串,使用str()函数将代表页码的整型变量i转换为字符串
url = 'http://www.e****.com/nba/salaries/_/page/' + str(i)
# 添加到列表
url_list.append(url)
# 遍历列表读取网页数据并添加到DataFrame对象中
for url in url_list:
df = df._append(pd.read_html(url), ignore_index=True)
# 输出数据
print(df)
运行程序,结果如下图所示:图 2 获取到的NBA球员薪资数据(部分数据)
从运行结果得知,首先数据中存在着一些无用的数据,如表头为数字 0、1、2、3 不能表明每列数据的作用,其次,数据存在重复的表头,如“RK”、“NAME”、“TEAM”和“SALARY”。
接下来进行数据清洗,首先去掉重复的表头数据,主要使用字符串函数 startswith(),遍历 DataFrame 对象的第 4 列(也就是索引为 3 的列),将以“$”字符开头的数据筛选出来,这样便去除了重复的表头,程序代码如下:
df=df[[x.startswith('$') for x in df[3]]]
再次运行程序,会发现数据条目发生了变化,重复的表头被去除了。最后,重新赋予表头以说明每列的作用,方法是在数据导出为 Excel 文件时,通过 DataFrame 对象的 to_excel() 方法的 header 参数指定表头,程序代码如下:
df.to_excel('NBA.xlsx',header=['RK','NAME','TEAM','SALARY'],index=False)
运行程序,在程序所在文件夹中将自动生成一个名为“NBA.xlsx”的 Excel 文件,打开该文件,结果如下图所示。图 3 导出后的“NBA.xlsx”Excel文件
注意,运行程序如果出现 ImportError:lxml not found,please installit 错误提示信息,则需要安装 lxml 模块。另外需要注意的是,Pandas 从 1.4.0 本开始,DataFrame.append() 方法和 Series.append() 方法都被弃用,取而代之的是 _append() 方法。
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: