TensorBoard add_histogram()的用法(附带实例)
使用 add_histogram() 方法来记录一组数据的直方图。通过观察数据、训练参数和特征的直方图,我们可以了解它们大致的分布情况,从而辅助神经网络的训练过程。
add_histogram() 方法的语法格式如下:
示例代码如下:
下图左图和右图分别为 "DISTRIBUTIONS" 界面和 "HISTOGRAMS" 界面。
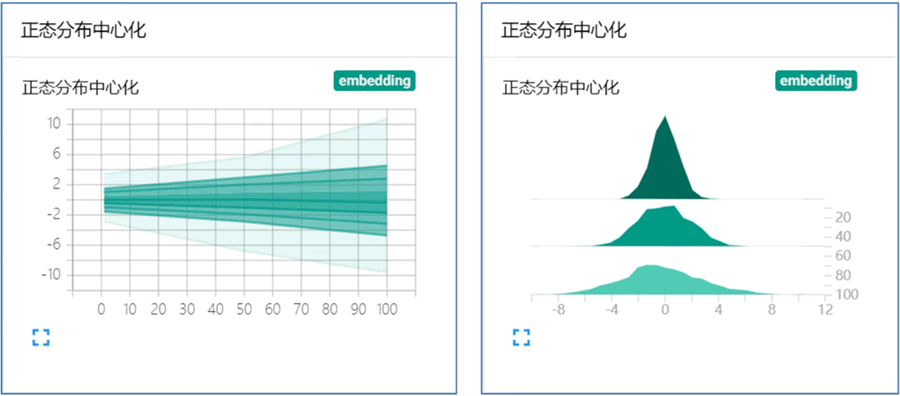
图 1 可视化统计图
add_histogram() 方法的语法格式如下:
add_histogram(tag, values, global_step=None, bins='tensorflow', walltime=None, max_bins=None)各个参数的含义如下:
- tag (string):数据名称;
- values (torch.Tensor, numpy.array, or string/blobname):用来构建直方图的数据;
- global_step (int, optional):训练的 step;
- bins (string, optional):取值有 'tensorflow'、'auto'、'fd' 等,该参数决定了分桶的方式;
- walltime (float, optional):记录发生的时间,默认为 time.time();
- max_bins (int, optional):最大分桶数。
示例代码如下:
# 导入相关库
from tensorboardX import SummaryWriter
import numpy as np
# 创建一个SummaryWriter对象,指定日志保存的路径为'runs/embedding_example'
writer = SummaryWriter('runs/embedding_example')
# 向SummaryWriter中添加正态分布的直方图数据,global_step 分别为 1、50、100
writer.add_histogram('正态分布中心化', np.random.normal(0, 1, 1000), global_step=1)
writer.add_histogram('正态分布中心化', np.random.normal(0, 2, 1000), global_step=50)
writer.add_histogram('正态分布中心化', np.random.normal(0, 3, 1000), global_step=100)
使用 NumPy 从不同方差的正态分布中进行采样。打开浏览器可视化界面后,我们发现多出了 "DISTRIBUTIONS" 和 "HISTOGRAMS" 两栏,它们都是用来观察数据分布的。在 "HISTOGRAMS" 中,同一数据集不同步骤(step)的直方图可以选择上下错位排布(OFFSET),或重叠排布(OVERLAY)。下图左图和右图分别为 "DISTRIBUTIONS" 界面和 "HISTOGRAMS" 界面。
图 1 可视化统计图
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: