什么是过拟合(非常详细)
过拟合是什么呢?举个极端的例子,假设根据一些训练集,某机器学习方法找到了一个函数:
这个函数没什么用处,但它在训练数据上的损失是 0。把训练数据通通输入这个函数,它的输出跟训练集的标签一模一样,所以在训练数据上,这个函数的损失是 0。可在测试数据上,它的损失会变得很大,因为它其实什么都没有预测。这个例子比较极端,但一般情况下,也有可能发生类似的事情。
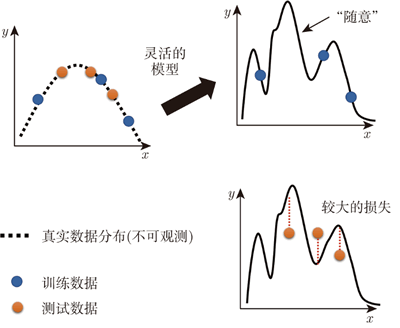
图 1 模型灵活性太大导致的问题
如上图所示,假设输入的特征为 x,输出为 y,x 与 y 都是一维的,它们的关系是一条平滑的曲线。我们真正可以观察到的是训练集,训练集可以想象成从这条曲线上随机采样得到的几个点。
模型的能力非常强,灵活性很大,只给它 3 个点。在这 3 个点上,要让损失低,所以模型的这条曲线会通过这 3 个点;但是在别的地方,模型的灵活性很高,因此模型可以变成各种各样的函数,产生各式各样奇怪的结果。
再输入测试数据,测试数据和训练数据当然不会一模一样,它们可能是从同一个分布采样出来的,测试数据是橙色的点,训练数据是蓝色的点。用蓝色的点找出一个函数以后,测试在橙色的点上不一定会好。如果模型的自由度很高,就会产生非常奇怪的曲线,导致训练集上的表现很好,但测试集上的损失很大。
怎么解决过拟合的问题呢?有两个可能的方向。第一个方向往往是最有效的方向,即增大训练集。 因此,如果蓝色的点变多了,虽然模型的灵活性可能很大,但是模型仍然可以被限制住,看起来的形状还是会很像产生这些数据背后的二次曲线,如下图所示。 数据增强(data augmentation)的方法并不算使用了额外的数据。
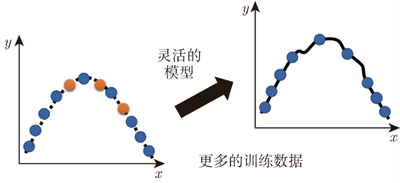
图 2 增加数据
数据增强就是根据对问题的理解创造出新的数据。举个例子,在做图像识别的时候,一个常见的招式是,假设训练集里面有一张图片,把它左右翻转,或者将其中的一部分截出来放大等等。对图像进行左右翻转,数据就变成原来的两倍。但是数据增强不能够随便乱做。
在图像识别里面,很少看到有人把上下颠倒图像当作数据增强。因为这些图片都是合理的图像,左右翻转图像,并不会影响到里面的内容。 但把图像上下颠倒,可能就不是一个训练集或真实世界里才会出现的图像了。
如果机器根据奇怪的图像进行学习,它可能就会学得奇怪的结果。所以,要根据对数据的特性以及要处理问题的理解,选择合适的数据增强方式。
另一个方向是给模型一些限制,让模型不要有太高的灵活性。假设和背后的关系其实就是一条二次曲线,只是这条二次曲线里面的参数是未知的。
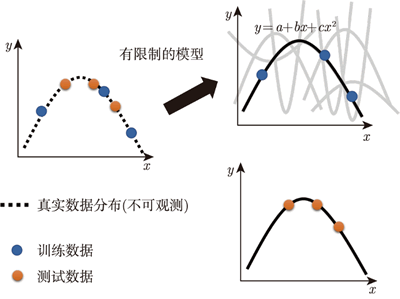
图 3 对模型施加限制
如上图所示,要用多大限制的模型才会好取决于对这个问题的理解。因为这种模型是我们自己设计的,设计出不同的模型,结果不同。假设模型是二次曲线,在选择函数的时候就会有很大的限制。 因为二次曲线的外形都很相似,所以当训练集有限的时候,只能选有限的几个函数。所以虽然只给了 3 个点,但是因为能选择的函数有限,我们也可能正好选到跟真正的分布比较接近的函数,在测试集上得到比较好的结果。
为了解决过拟合的问题,要给模型一些限制,具体来说,有如下方法:
即便如此,也不要给模型太多的限制。 以线性模型为例,图下中有 3 个点,没有任何一条直线可以同时通过这 3 个点。
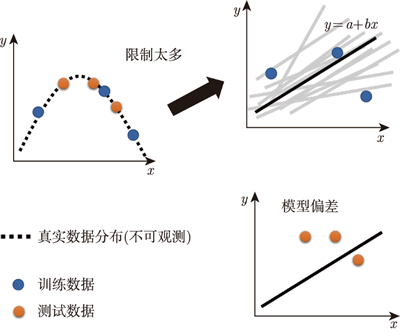
图 4 限制太大会导致模型偏差
只能找到一条直线,这条直线与这些点是比较近的。 这时候模型的限制就太大了,在测试集上就不会得到好的结果。这种情况下的结果不好,并不是因为过拟合,而是因为给了模型太多的限制,多到有了模型偏差的问题。
模型的复杂程度和灵活性没有明确的定义。比较复杂的模型包含的函数比较多,参数也比较多。
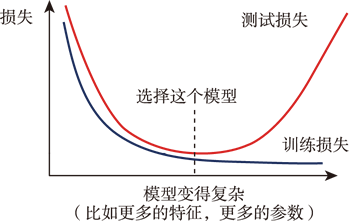
图 5 模型的复杂程度与损失的关系
如上图所示,随着模型越来越复杂,训练损失可以越来越低。 但在测试时,随着模型越来越复杂,刚开始测试损失会显著下降,但是当复杂程度超过一定程度后,测试损失就突然增加了。这是因为当模型越来越复杂时,过拟合的情况就会出现,所以在训练损失上可以得到比较好的结果。而在测试损失上,结果不怎么好,可以选一个中庸的模型,不太复杂,也不太简单,要刚好既可以使训练损失最低,也可以使测试损失最低。
假设 3 个模型的复杂程度不太一样,不知道要选哪一个模型才会刚刚好,从而在测试集上得到最好的结果。因为太复杂的模型会导致过拟合,而太简单的模型会导致模型偏差的问题。把这 3 个模型的结果都跑出来,损失最低的模型显然就是最好的模型.
- 只要输入 x 出现在训练集中,就把对应的输出 y 输出;
- 如果 x 没有出现在训练集中,就输出一个随机值。
这个函数没什么用处,但它在训练数据上的损失是 0。把训练数据通通输入这个函数,它的输出跟训练集的标签一模一样,所以在训练数据上,这个函数的损失是 0。可在测试数据上,它的损失会变得很大,因为它其实什么都没有预测。这个例子比较极端,但一般情况下,也有可能发生类似的事情。
图 1 模型灵活性太大导致的问题
如上图所示,假设输入的特征为 x,输出为 y,x 与 y 都是一维的,它们的关系是一条平滑的曲线。我们真正可以观察到的是训练集,训练集可以想象成从这条曲线上随机采样得到的几个点。
模型的能力非常强,灵活性很大,只给它 3 个点。在这 3 个点上,要让损失低,所以模型的这条曲线会通过这 3 个点;但是在别的地方,模型的灵活性很高,因此模型可以变成各种各样的函数,产生各式各样奇怪的结果。
再输入测试数据,测试数据和训练数据当然不会一模一样,它们可能是从同一个分布采样出来的,测试数据是橙色的点,训练数据是蓝色的点。用蓝色的点找出一个函数以后,测试在橙色的点上不一定会好。如果模型的自由度很高,就会产生非常奇怪的曲线,导致训练集上的表现很好,但测试集上的损失很大。
怎么解决过拟合的问题呢?有两个可能的方向。第一个方向往往是最有效的方向,即增大训练集。 因此,如果蓝色的点变多了,虽然模型的灵活性可能很大,但是模型仍然可以被限制住,看起来的形状还是会很像产生这些数据背后的二次曲线,如下图所示。 数据增强(data augmentation)的方法并不算使用了额外的数据。
图 2 增加数据
数据增强就是根据对问题的理解创造出新的数据。举个例子,在做图像识别的时候,一个常见的招式是,假设训练集里面有一张图片,把它左右翻转,或者将其中的一部分截出来放大等等。对图像进行左右翻转,数据就变成原来的两倍。但是数据增强不能够随便乱做。
在图像识别里面,很少看到有人把上下颠倒图像当作数据增强。因为这些图片都是合理的图像,左右翻转图像,并不会影响到里面的内容。 但把图像上下颠倒,可能就不是一个训练集或真实世界里才会出现的图像了。
如果机器根据奇怪的图像进行学习,它可能就会学得奇怪的结果。所以,要根据对数据的特性以及要处理问题的理解,选择合适的数据增强方式。
另一个方向是给模型一些限制,让模型不要有太高的灵活性。假设和背后的关系其实就是一条二次曲线,只是这条二次曲线里面的参数是未知的。
图 3 对模型施加限制
如上图所示,要用多大限制的模型才会好取决于对这个问题的理解。因为这种模型是我们自己设计的,设计出不同的模型,结果不同。假设模型是二次曲线,在选择函数的时候就会有很大的限制。 因为二次曲线的外形都很相似,所以当训练集有限的时候,只能选有限的几个函数。所以虽然只给了 3 个点,但是因为能选择的函数有限,我们也可能正好选到跟真正的分布比较接近的函数,在测试集上得到比较好的结果。
为了解决过拟合的问题,要给模型一些限制,具体来说,有如下方法:
- 给模型比较少的参数:如果是深度学习,就给它比较少的神经元,如本来每层有 1000 个神经元,改成 100 个神经元,或者让模型共用参数,可以让一些参数有一样的数值。全连接网络(fully-connected network)其实是一种比较灵活的架构,而卷积神经网络(Convolutional Neural Network,CNN)是一种比较有限制的架构。CNN 针对图像的特性来限制模型的灵活性。所以,对于全连接神经网络,可以找出来的函数所形成的集合其实是比较大的;而对于 CNN,可以找出来的函数所形成的集合其实是比较小的。 正是因为 CNN 给了模型比较大的限制,所以 CNN 在图像识别等任务上反而做得比较好。
- 提供比较少的特征:例如,将原本给前 3 天的数据改成只给2天的数据作为特征,结果就可能更好一些。
- 其他的方法:如早停(early stopping)、正则化(regularization)、丢弃法(dropout method)等。
即便如此,也不要给模型太多的限制。 以线性模型为例,图下中有 3 个点,没有任何一条直线可以同时通过这 3 个点。
图 4 限制太大会导致模型偏差
只能找到一条直线,这条直线与这些点是比较近的。 这时候模型的限制就太大了,在测试集上就不会得到好的结果。这种情况下的结果不好,并不是因为过拟合,而是因为给了模型太多的限制,多到有了模型偏差的问题。
模型的复杂程度和灵活性没有明确的定义。比较复杂的模型包含的函数比较多,参数也比较多。
图 5 模型的复杂程度与损失的关系
如上图所示,随着模型越来越复杂,训练损失可以越来越低。 但在测试时,随着模型越来越复杂,刚开始测试损失会显著下降,但是当复杂程度超过一定程度后,测试损失就突然增加了。这是因为当模型越来越复杂时,过拟合的情况就会出现,所以在训练损失上可以得到比较好的结果。而在测试损失上,结果不怎么好,可以选一个中庸的模型,不太复杂,也不太简单,要刚好既可以使训练损失最低,也可以使测试损失最低。
假设 3 个模型的复杂程度不太一样,不知道要选哪一个模型才会刚刚好,从而在测试集上得到最好的结果。因为太复杂的模型会导致过拟合,而太简单的模型会导致模型偏差的问题。把这 3 个模型的结果都跑出来,损失最低的模型显然就是最好的模型.
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: