向量数据库和传统数据库的区别(非常详细)
传统数据库的设计初衷主要是面向结构化数据,对于高维向量检索任务,其性能和功能显得不足。在高维数据存储与检索场景中,传统数据库面临诸多局限性,例如索引结构无法适应高维空间的复杂性,查询效率显著下降,以及无法高效支持向量相似性计算。
本节将从传统数据库的设计原理出发,分析其在高维向量检索中的实现难点,并通过性能对比,阐明向量数据库在这一场景中的技术优势与应用价值。
传统数据库的主要设计原理如下。
1) 面向结构化数据的优化:传统数据库专注于存储和管理具有明确字段和类型的结构化数据,例如用户信息表(ID、姓名、地址等)。这种模式适合处理精确匹配或基于简单规则的查询。
2) 索引机制:使用索引(如 B 树索引)快速定位数据,提升查询效率。但这些索引主要适用于低维度数据,面对高维向量时,索引结构难以保持性能优势。
3) 事务支持和一致性:通过事务机制(原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability),即ACID特性)确保数据一致性,适用于金融、电子商务等场景中的精确数据处理。
尽管传统数据库在结构化数据管理方面表现优异,但在高维向量检索中存在显著局限性:
1) 无法支持向量相似性计算:传统数据库的查询逻辑基于精确匹配或范围匹配,而高维向量检索需要进行复杂的相似性计算(如余弦相似度或欧氏距离)。这些计算难以通过传统的索引结构实现高效支持。
2) 索引结构难以扩展到高维数据:高维空间中的“维度诅咒”使得传统索引(如B树或R树)无法有效分割数据,检索效率急剧下降,甚至需要扫描整个数据库才能获得结果。
3) 缺乏对非结构化数据的支持:高维向量通常来自非结构化数据(如文本嵌入、图像特征),而传统数据库在存储和管理此类数据时缺乏灵活性和优化能力。
4) 扩展性和性能不足:在面对大规模高维向量检索时,传统数据库的性能瓶颈明显,例如存在查询延迟增加、索引内存消耗高等问题,难以满足实时性要求。传统数据库的基本构成如下图所示。
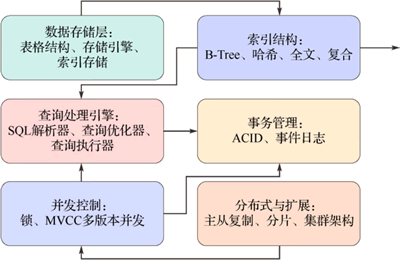
图 1 传统数据库的基本构成
综上所述,传统数据库的设计原理决定了其在处理高维向量检索任务时的局限性。随着非结构化数据和高维向量的广泛应用,向量数据库因其在高维检索和相似性计算中的优越性能,成为解决这一问题的重要工具。
然而,传统数据库并非为处理高维向量而设计,导致其在实现高维向量检索时面临诸多难点。
例如,要存储和检索一个嵌入向量,需要将其转换为适合数据库的格式,而这种转换过程本身可能带来额外的计算开销和性能损失。
例如,在存储数百万个 300 维嵌入向量时,传统数据库需要为每个维度分配固定的字段,进一步放大了存储需求。
例如,使用用户自定义函数(User-Defined Function,UDF)实现相似性计算,虽然能够完成任务,但在性能上会远远落后于基于ANN优化的向量数据库。
高维向量检索在传统数据库中面临的难点集中在索引效率、相似性计算、扩展性和存储成本等方面。这些问题在高维向量数据规模持续增长的背景下变得更加突出,进一步凸显了向量数据库的重要性和必要性。
向量数据库的基本构成如下图所示:
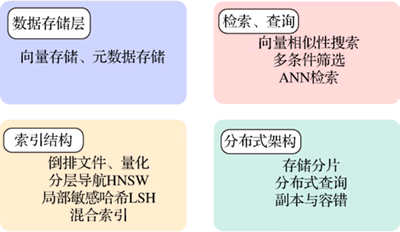
图 2 向量数据库的基本构成
接下来从多个维度分析二者的性能差异。
向量数据库专为高维数据设计,采用分层导航小世界(HNSW)图或倒排文件+量化(IVF-PQ)等优化索引。这些索引针对高维特性,能够在保证较高检索精度的同时,显著降低构建时间和内存占用。
向量数据库支持近似最近邻(ANN)搜索,通过牺牲少量精度实现检索速度的大幅提升。例如,HNSW 算法能在对数级的时间复杂度内完成高效检索,即使在百万级数据规模下也能实现毫秒级响应。
向量数据库内置对多种相似性计算方法的支持,能够高效完成向量间的相似性度量,并通过优化内核实现GPU加速,大幅降低计算开销。
向量数据库采用分布式存储和检索架构,能够动态扩展节点规模以应对数据增长。结合高效的存储压缩技术(如量化向量表示),向量数据库在资源利用和扩展性方面表现优异。
二者的差异如下表所示:
传统数据库在处理结构化数据时具有显著优势,但在高维向量检索场景中,性能的局限性难以满足复杂应用需求。相比之下,向量数据库通过优化索引和搜索算法,支持高效相似性计算以及更好的扩展性,成为高维检索的首选解决方案。
随着非结构化数据的广泛应用,向量数据库的技术价值和应用前景将愈发突出。
本节将从传统数据库的设计原理出发,分析其在高维向量检索中的实现难点,并通过性能对比,阐明向量数据库在这一场景中的技术优势与应用价值。
传统数据库的设计原理与局限性
传统数据库,如关系数据库(Relational Database Management System,RDBMS),以表格的形式组织和管理数据,其核心设计目标是高效存储和查询结构化数据。这类数据库依赖于固定的模式(Schema)来定义数据字段和类型,利用索引结构(如B树或哈希索引)优化查询性能。传统数据库的主要设计原理如下。
1) 面向结构化数据的优化:传统数据库专注于存储和管理具有明确字段和类型的结构化数据,例如用户信息表(ID、姓名、地址等)。这种模式适合处理精确匹配或基于简单规则的查询。
2) 索引机制:使用索引(如 B 树索引)快速定位数据,提升查询效率。但这些索引主要适用于低维度数据,面对高维向量时,索引结构难以保持性能优势。
3) 事务支持和一致性:通过事务机制(原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability),即ACID特性)确保数据一致性,适用于金融、电子商务等场景中的精确数据处理。
尽管传统数据库在结构化数据管理方面表现优异,但在高维向量检索中存在显著局限性:
1) 无法支持向量相似性计算:传统数据库的查询逻辑基于精确匹配或范围匹配,而高维向量检索需要进行复杂的相似性计算(如余弦相似度或欧氏距离)。这些计算难以通过传统的索引结构实现高效支持。
2) 索引结构难以扩展到高维数据:高维空间中的“维度诅咒”使得传统索引(如B树或R树)无法有效分割数据,检索效率急剧下降,甚至需要扫描整个数据库才能获得结果。
3) 缺乏对非结构化数据的支持:高维向量通常来自非结构化数据(如文本嵌入、图像特征),而传统数据库在存储和管理此类数据时缺乏灵活性和优化能力。
4) 扩展性和性能不足:在面对大规模高维向量检索时,传统数据库的性能瓶颈明显,例如存在查询延迟增加、索引内存消耗高等问题,难以满足实时性要求。传统数据库的基本构成如下图所示。
图 1 传统数据库的基本构成
综上所述,传统数据库的设计原理决定了其在处理高维向量检索任务时的局限性。随着非结构化数据和高维向量的广泛应用,向量数据库因其在高维检索和相似性计算中的优越性能,成为解决这一问题的重要工具。
高维向量检索在传统数据库中的实现难点
高维向量检索要求系统能够快速、高效地找到与查询向量相似的数据点,这在许多场景中具有重要意义,如推荐系统、图像搜索和自然语言处理。然而,传统数据库并非为处理高维向量而设计,导致其在实现高维向量检索时面临诸多难点。
1) 无法高效支持向量相似性计算
传统数据库的查询方式通常基于精确匹配或简单范围查询,而高维向量检索需要进行复杂的相似性度量,例如余弦相似度或欧氏距离。这种计算需要对所有维度进行复杂的数学运算,传统数据库的查询逻辑和索引结构很难直接支持这类操作。2) 索引效率随维度增加显著下降
传统数据库常用的索引结构(如B树、哈希索引)在低维数据上表现优异,但在高维空间中,这些索引结构难以维持有效性。具体表现如下:- 数据分布稀疏:高维空间中的数据点大多彼此远离,索引无法有效分割空间;
- 搜索复杂性增加:高维空间的查询往往退化为全表扫描,导致检索效率显著下降。
3) 缺乏对ANN技术的支持
近似最近邻(ANN)技术是高维向量检索中的重要方法,允许通过牺牲部分精度换取显著的性能提升。然而,传统数据库缺乏对 ANN 算法(如 LSH 或 HNSW)的支持,这使得其在大规模检索中的速度远低于专用向量数据库。4) 非结构化数据处理能力不足
高维向量通常来源于非结构化数据(如图像、音频或文本)。传统数据库的存储和检索机制主要面向结构化数据,对于非结构化数据的向量表示和相似性查询缺乏灵活性。例如,要存储和检索一个嵌入向量,需要将其转换为适合数据库的格式,而这种转换过程本身可能带来额外的计算开销和性能损失。
5) 扩展性与实时性不足
传统数据库在扩展大规模数据集和支持实时高维检索方面,主要有以下不足:- 扩展性瓶颈:当数据集规模扩大时,索引结构需要重新构建,增加了系统的维护成本;
- 查询延迟:高维向量检索的实时性需求无法通过传统的索引和查询机制得到满足。
6) 高维数据的存储成本高
高维向量的数据量通常很大,而传统数据库的存储机制缺乏专门针对高维数据优化的压缩技术,导致存储成本显著增加。例如,在存储数百万个 300 维嵌入向量时,传统数据库需要为每个维度分配固定的字段,进一步放大了存储需求。
7) 解决方案的局限性
尽管可以通过额外插件或中间层将部分高维检索功能集成到传统数据库中,但这些解决方案通常难以与向量数据库的专有优化技术相媲美。例如,使用用户自定义函数(User-Defined Function,UDF)实现相似性计算,虽然能够完成任务,但在性能上会远远落后于基于ANN优化的向量数据库。
高维向量检索在传统数据库中面临的难点集中在索引效率、相似性计算、扩展性和存储成本等方面。这些问题在高维向量数据规模持续增长的背景下变得更加突出,进一步凸显了向量数据库的重要性和必要性。
传统数据库与向量数据库的性能对比分析
传统数据库和向量数据库在高维向量检索中的表现差异显著。二者的性能对比主要体现在索引构建效率、检索速度、相似性计算能力和扩展性等方面。向量数据库的基本构成如下图所示:
图 2 向量数据库的基本构成
接下来从多个维度分析二者的性能差异。
1) 索引构建效率
传统数据库的索引主要面向结构化数据,常用的B树、哈希索引等在低维空间中表现出色。然而,在高维数据场景下,这些索引难以有效分割数据空间,构建效率随着维度的增加显著下降。向量数据库专为高维数据设计,采用分层导航小世界(HNSW)图或倒排文件+量化(IVF-PQ)等优化索引。这些索引针对高维特性,能够在保证较高检索精度的同时,显著降低构建时间和内存占用。
2) 检索速度
由于传统数据库无法直接支持高维向量相似性计算,检索往往退化为全表扫描,速度随数据量和维度的增加迅速下降。对于大规模数据集,查询延迟难以满足实时应用需求。向量数据库支持近似最近邻(ANN)搜索,通过牺牲少量精度实现检索速度的大幅提升。例如,HNSW 算法能在对数级的时间复杂度内完成高效检索,即使在百万级数据规模下也能实现毫秒级响应。
3) 相似性计算能力
传统数据库对数据的查询逻辑基于精确匹配或简单范围查询,缺乏对余弦相似度、欧氏距离等复杂相似性度量的支持。即使通过用户自定义函数扩展功能,其性能也远不及专门优化的向量数据库。向量数据库内置对多种相似性计算方法的支持,能够高效完成向量间的相似性度量,并通过优化内核实现GPU加速,大幅降低计算开销。
4) 扩展性与资源利用
在高维向量场景下,传统数据库的扩展性表现较差。随着数据量和维度的增长,其索引重建、存储成本和查询性能都会面临瓶颈,系统难以适应动态变化的业务需求。向量数据库采用分布式存储和检索架构,能够动态扩展节点规模以应对数据增长。结合高效的存储压缩技术(如量化向量表示),向量数据库在资源利用和扩展性方面表现优异。
二者的差异如下表所示:
| 对比维度 | 传统数据库 | 向量数据库 |
|---|---|---|
| 索引构建效率 | 高维向量场景下效率显著下降 | HNSW、IVF-PQ等优化索引效率较高 |
| 检索速度 | 数据量大时延迟显著 | 毫秒级响应,支持实时高效检索 |
| 相似性计算能力 | 缺乏支持,仅能通过扩展实现 | 原生支持多种度量,性能大幅领先 |
| 扩展性与资源利用 | 随数据增长面临性能瓶颈 | 分布式架构,支持动态扩展 |
传统数据库在处理结构化数据时具有显著优势,但在高维向量检索场景中,性能的局限性难以满足复杂应用需求。相比之下,向量数据库通过优化索引和搜索算法,支持高效相似性计算以及更好的扩展性,成为高维检索的首选解决方案。
随着非结构化数据的广泛应用,向量数据库的技术价值和应用前景将愈发突出。