支持向量机详解(附带实例,Python实现)
支持向量机(support vector machine,SVM)是机器学习的一种形式,可用于分类或回归。
尽可能简单地说,支持向量机找到了划分两组数据的最佳直线或平面,或者在回归的情况下,找到了在容差范围内描述趋势的最佳路径。
在样本空间中,划分超平面可通过如下形式来描述:
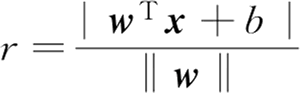
其中,常数 b 类似于逻辑回归中的截距。
有了分类器,接下来就是找到最小间隔的数据点,然后将其最大化并求出参数 w 和 b。可以写作:
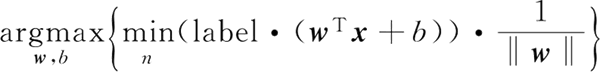
显然 label·(wTxi+b)≥1,i=1,2,…,m,为了最大化间隔只需要最大化:
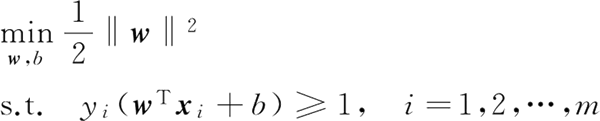
上式本身是个凸二次规划的问题,能够使用现成的优化计算包求解,但可以有更高效的办法。
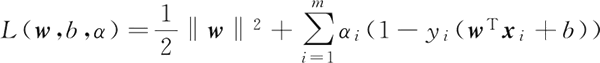
令 L(w, b, α) 对 w 和 b 的偏导为 0 可得:

将上式代入 L 得最终的优化目标函数:
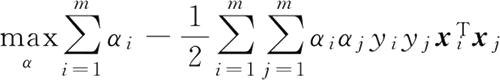
约束条件为:
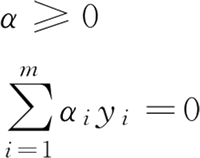
求解出 α 后,求出 w 与 b 即可得到模型。接下来根据上面最后三个式子进行优化。
SMO 算法的工作原理:每次循环选择两个 alpha 进行优化处理,一旦找到一对合适的 alpha,那么就增大其中一个同时减小另一个。这里所谓的合适就是指两个 alpha 必须在间隔边界之外、还没经过区间化处理或者不在边界上。
SVM 中优化目标函数是写成内积的形式,向量的内积就是两向量相乘得到单个标量或数值,假设 ϕ(x) 表示将 x 映射后的特征向量,那么优化目标函数变成:
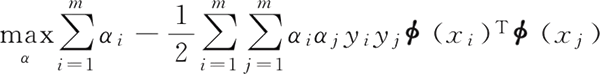
要想直接求解 ϕ(xi)Tϕ(xj) 是困难的。为了避开这个困难,设想了一个函数:
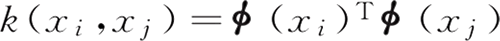
即 xi 与 xj 在特征空间的内积等于它们在原始样本空间中通过函数 k(·, ·) 计算的结果。这样的函数就是核函数。核函数不仅应用于支持向量机,还应用到很多其他的机器学习算法中。
SVM 比较流行的核函数称作径向基核函数,常用的核函数有线性核、多项式核、拉普拉斯核、sigmoid 核、高斯核等。具体公式表现如下:
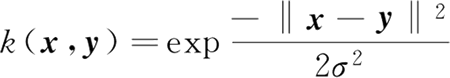
其中,σ 是用户定义的确定到达率或函数值跌落到 0 的速度参数。
【实例】利用支持向量机对鸢尾花数据实现分类。

图 1 线性核分类效果

图 2 多项式核分类效果
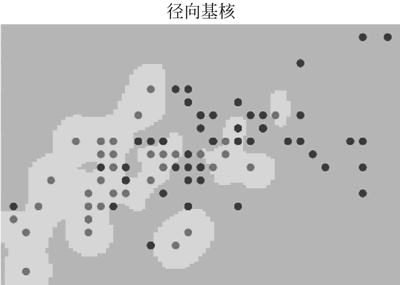
图 3 径向基核分类效果
尽可能简单地说,支持向量机找到了划分两组数据的最佳直线或平面,或者在回归的情况下,找到了在容差范围内描述趋势的最佳路径。
间隔与支持向量
SVM 的工作原理是,找到离分隔超平面最近的点,确保它们离分隔面的距离尽可能地远。点到分隔面的距离的两倍称为间隔。支持向量就是离分隔超平面最近的那些点。在样本空间中,划分超平面可通过如下形式来描述:
wTx+b
其中,w=(w1, w2, …, wd)T 为法向量,决定了超平面的方向;b 为位移项,决定了超平面与原点之间的距离。下面将其记为 (w, b),样本空间中任意点 x 到超平面 (w, b) 的距离可写为:其中,常数 b 类似于逻辑回归中的截距。
确定分类器
确定一个分类器,对任意的实数,当 wTx+b>1 时,yi=1;当 wTx+b<-1 时,yi=-1。有了分类器,接下来就是找到最小间隔的数据点,然后将其最大化并求出参数 w 和 b。可以写作:
显然 label·(wTxi+b)≥1,i=1,2,…,m,为了最大化间隔只需要最大化:
‖w‖-1
这等价于最小化:‖w‖2
所以支持向量机的基本式为:上式本身是个凸二次规划的问题,能够使用现成的优化计算包求解,但可以有更高效的办法。
对偶问题
对支持向量机的基本式使用拉格朗日乘子法可得到其对偶问题。该问题的拉格朗日函数可写为:令 L(w, b, α) 对 w 和 b 的偏导为 0 可得:
将上式代入 L 得最终的优化目标函数:
约束条件为:
求解出 α 后,求出 w 与 b 即可得到模型。接下来根据上面最后三个式子进行优化。
SMO算法
SMO 算法通过将大优化问题分解为许多小优化问题进行求解,并且对它们顺序求解的结果与将它们作为整体求解的结果是完全一致的,但时间还要短得多。SMO 算法的工作原理:每次循环选择两个 alpha 进行优化处理,一旦找到一对合适的 alpha,那么就增大其中一个同时减小另一个。这里所谓的合适就是指两个 alpha 必须在间隔边界之外、还没经过区间化处理或者不在边界上。
核函数
SVM 在处理线性不可分的问题时,通常将数据从一个特征空间转换到另一个特征空间。在新的特征空间下往往有比较清晰的测试结果。总结得到,如果原始空间是有限维的,即属性有限,那么一定存在一个高维特征空间使样本可分。SVM 中优化目标函数是写成内积的形式,向量的内积就是两向量相乘得到单个标量或数值,假设 ϕ(x) 表示将 x 映射后的特征向量,那么优化目标函数变成:
要想直接求解 ϕ(xi)Tϕ(xj) 是困难的。为了避开这个困难,设想了一个函数:
即 xi 与 xj 在特征空间的内积等于它们在原始样本空间中通过函数 k(·, ·) 计算的结果。这样的函数就是核函数。核函数不仅应用于支持向量机,还应用到很多其他的机器学习算法中。
SVM 比较流行的核函数称作径向基核函数,常用的核函数有线性核、多项式核、拉普拉斯核、sigmoid 核、高斯核等。具体公式表现如下:
其中,σ 是用户定义的确定到达率或函数值跌落到 0 的速度参数。
支持向量机实现
前面介绍了支持向量机的间隔、确定分类器、对偶问题、SMO 算法、核函数等问题,下面直接通过实例演示支持向量机如何实现分类。【实例】利用支持向量机对鸢尾花数据实现分类。
import numpy as np
from sklearn import svm
import pylab as pl
from sklearn import datasets
svc = svm.SVC(kernel = 'linear')
#鸢尾花数据集是sklearn自带的.
irics = datasets.load_iris() #irics为字典
#取出前两个特征
irics_feature = irics['data'][:,:2]
irics_target = irics['target']
#基于这些特征和目标训练支持向量机
#svc.fit(irics_feature,irics_target)
#将预测结果可视化
from matplotlib.colors import ListedColormap
#鸢尾花是3分类问题,我们要对样本和预测结果均用三种颜色区分开
camp_light = ListedColormap(['# FFAAAA','# AAFFAA','# AAAAFF'])
camp_bold = ListedColormap(['# FF0000','# 00FF00','# 0000FF'])
pl.figure()
def plot_estimater(estimator,X,y):
'''
这个函数的作用是基于分类器,对预测结果与原始标签进行可视化
'''
estimator.fit(X,y)
#确定网格最大最小值作为边界
x_min,x_max = X[:,0].min()-.1,X[:,0].max() + .1
y_min,y_max = X[:,1].min()-.1,X[:,1].max() + .1
#产生网格节点
#linspace作用为在区间[x_min,x_max]产生100个元素的数列
xx,yy = np.meshgrid(np.linspace(x_min,x_max,100),np.linspace(y_min,y_max,100))
#基于分离器,对网格节点做预测
#np.c_[xx.ravel(),yy.ravel()]相当于产生一个坐标
Z = estimator.predict(np.c_[xx.ravel(),yy.ravel()])
#对预测结果上色,维度保持一致
Z = Z.reshape(xx.shape)
pl.pcolormesh(xx,yy,Z,cmap = camp_light)
#同时对原始训练样本上色
pl.scatter(X[:,0],X[:,1],c = y,cmap = camp_bold)
pl.axis('tight')
pl.axis('off')
pl.tight_layout()
'''不同kernel对比'''
X,y = irics_feature[np.in1d(irics_target,[1,2])],irics_target[np.in1d(irics_target,[1,2])]
svc = svm.SVC(kernel = 'linear')
plot_estimater(svc,X,y)
pl.scatter(svc.support_vectors_[:,0],svc.support_vectors_[:,1],s = 80,facecolors = 'none',
zorder = 10)
pl.title('线性核')
pl.show()
svc = svm.SVC(kernel = 'poly',degree = 4)
plot_estimater(svc,X,y)
pl.title('多项式核')
pl.show()
svc = svm.SVC(kernel = 'rbf',gamma = 1e2)
plot_estimater(svc,X,y)
pl.title('径向基核')
pl.show()
运行程序,效果如图 1 ~图 3 所示:图 1 线性核分类效果
图 2 多项式核分类效果
图 3 径向基核分类效果
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: