数据分析到底是什么?
随着大数据及人工智能时代的来临,数据科学变得越来越重要。所谓数据科学,用最简单的一句话来解释就是:处理数据的科学。
网络爬虫、数据分析、数据可视化、机器学习等等,在日常学习或工作中,我们或多或少都听过上面这些名词。但是大多数人只停留在了解上,并不知道这些名词的背后其实是有着深层次联系的。如果想要从数据中提炼出有用的信息,一般流程是下面这样的:
图 1 是一张非常有价值的图,从中我们可以得到非常重要的两点信息:
有了这张图,我们在接触 Python 各个领域的时候,会有一个清晰的学习路线。
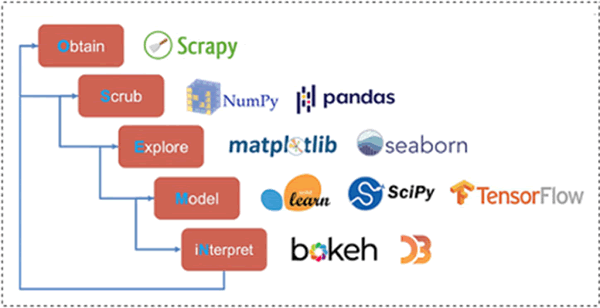
图 1
通过数据分析,我们可以挖掘出数据的内在规律及有用信息,进而帮助企业创造新的商业价值、提高运营效率、获得持续竞争的优势等。数据分析这种方式更加科学准确,远不是只凭个人经验(也就是“我觉得”)这种方式能比的,所以现在的企业越来越重视数据分析。
可能很多读者都听过“啤酒和纸尿裤的故事”,为什么沃尔玛将看似毫不相干的啤酒和纸尿裤摆在一起销售,并且它们的销量双双增长呢?这是因为沃尔玛很好地运用了数据分析手段,挖掘出了啤酒和纸尿裤之间的潜在关系。
除了商业领域,数据分析在其他领域也有着大量的应用,例如科学研究、社会调查、体育竞技等。
那么问题来了,学习 Python 数据分析,我们应该学些什么呢?
对于 Python 数据分析来说,它有非常重要的 3 个库:NumPy、Pandas、Matplotlib。这 3 个库又被叫作 Python 数据分析“三剑客”(见图 2)。
图 2 Python数据分析“三剑客”
可能有些读者会问:“既然 Excel 可以做数据分析,为什么还要使用 Python 呢?”
虽然 Excel 好用,但是它更适合处理中小量数据,而不适合处理大量数据(也就是所谓的大数据)。Python 处理大量数据的效率,远远不是 Excel 能比得上的。
除了执行效率比 Excel 高之外,Python 的工作量也少很多。业界有一句比较有意思的话:“Excel 十分钟,Python 两行代码。”这句话恰恰说明了 Python 的简单高效。
最后需要说明的是,Python 虽然是一门编程语言,但是它在数据分析上实现的功能和 Excel 是非常相似的。所以,我们在学习 Python 数据分析时,应该和 Excel 多多进行对比,这样更能加深理解和记忆,如下图所示。

图 3 Python和Excel
这是因为 Python 的设计者从来没想过要包揽所有的活儿,Python 本身只提供基础语法及一些常用的功能模块。如果把所有功能都集中到 Python 上面,那么 Python 就会变得非常“臃肿”并且难以维护,运行速度也会变得非常慢。
对于其他功能,Python 使用“分工”的方式来管理,不同的功能使用不同的库。例如网络爬虫可以使用 Scrapy,而数据分析可以用 Pandas 等。分工才能更好地管理,在实际开发中,需要用到什么功能,导入对应的库即可。
对于 Python 来说,有那么一句话:学习 Python,其实就是学习 Python 的各种库。细想一下,这句话也是有一定道理的。
【问题 2】学习Python数据分析之前,要不要先学习 Excel?
实际上这是没有太大必要的。虽然有 Excel 基础可以帮助我们更快地学习,但即使没有任何 Excel 基础,我们也一样能轻松地学习 Python。
当然,如果你既学会了 Python 又掌握了 Excel,那么能在工作、面试时加分不少。
【问题 3】学习数据分析之前,要不要先学习网络爬虫?
从数据科学工作流程可以看出,网络爬虫用于获取数据,而数据分析用于处理数据。从正常角度来看,应该是先学会怎么获取数据,然后再学习怎样对数据进行处理。
实际上,网络爬虫、数据分析、数据可视化是可以完全独立开来学习的。虽然它们在应用时有着比较大的联系,但是学习时没有必然的先后顺序。读者完全可以根据自己的喜好来安排学习顺序。
网络爬虫、数据分析、数据可视化、机器学习等等,在日常学习或工作中,我们或多或少都听过上面这些名词。但是大多数人只停留在了解上,并不知道这些名词的背后其实是有着深层次联系的。如果想要从数据中提炼出有用的信息,一般流程是下面这样的:
获取数据 -> 处理数据 -> 展示数据网络爬虫用于获取数据,数据分析用于处理数据,数据可视化用于展示数据。而机器学习则是进一步对数据进行建模,以便进行预测分析。对于数据科学来说,它的工作流可以总结成“OSEMN”,如下表和图 1 所示。
| 步 骤 | 常用库 |
|---|---|
| Obtain(获取数据) | Scrapy |
| Scrub (淸洗数据) | NumPy、Pandas |
| Explore(展示数据) | Matplotlib、Seaborn |
| Model(数据建模) | Scikit-Learn SciPy、TensorFlow |
| iNterpret(解析数据) | Bokeh、D3.js |
图 1 是一张非常有价值的图,从中我们可以得到非常重要的两点信息:
- Python不同领域之间的关系;
- 不同领域都会用到什么库。
有了这张图,我们在接触 Python 各个领域的时候,会有一个清晰的学习路线。
图 1
数据分析是什么?
数据分析,也就是数据科学中“Scrub”(清洗数据)这一环节。它指的是在统计学理论的支持下,使用合理的工具对相关数据进行一定程度的处理,然后把隐藏在数据中的重要信息提炼出来。通过数据分析,我们可以挖掘出数据的内在规律及有用信息,进而帮助企业创造新的商业价值、提高运营效率、获得持续竞争的优势等。数据分析这种方式更加科学准确,远不是只凭个人经验(也就是“我觉得”)这种方式能比的,所以现在的企业越来越重视数据分析。
可能很多读者都听过“啤酒和纸尿裤的故事”,为什么沃尔玛将看似毫不相干的啤酒和纸尿裤摆在一起销售,并且它们的销量双双增长呢?这是因为沃尔玛很好地运用了数据分析手段,挖掘出了啤酒和纸尿裤之间的潜在关系。
除了商业领域,数据分析在其他领域也有着大量的应用,例如科学研究、社会调查、体育竞技等。
数据分析学什么?
如果想要成为一名真正的数据分析师,那么至少要掌握这 3 个工具:Excel、Python、SQL。那么问题来了,学习 Python 数据分析,我们应该学些什么呢?
对于 Python 数据分析来说,它有非常重要的 3 个库:NumPy、Pandas、Matplotlib。这 3 个库又被叫作 Python 数据分析“三剑客”(见图 2)。
图 2 Python数据分析“三剑客”
可能有些读者会问:“既然 Excel 可以做数据分析,为什么还要使用 Python 呢?”
虽然 Excel 好用,但是它更适合处理中小量数据,而不适合处理大量数据(也就是所谓的大数据)。Python 处理大量数据的效率,远远不是 Excel 能比得上的。
除了执行效率比 Excel 高之外,Python 的工作量也少很多。业界有一句比较有意思的话:“Excel 十分钟,Python 两行代码。”这句话恰恰说明了 Python 的简单高效。
最后需要说明的是,Python 虽然是一门编程语言,但是它在数据分析上实现的功能和 Excel 是非常相似的。所以,我们在学习 Python 数据分析时,应该和 Excel 多多进行对比,这样更能加深理解和记忆,如下图所示。
图 3 Python和Excel
学数据分析的常见问题
【问题 1】对于 Python 来说,不同的功能需要使用不同的库,为什么它不将这些功能全部集合到自身呢?这是因为 Python 的设计者从来没想过要包揽所有的活儿,Python 本身只提供基础语法及一些常用的功能模块。如果把所有功能都集中到 Python 上面,那么 Python 就会变得非常“臃肿”并且难以维护,运行速度也会变得非常慢。
对于其他功能,Python 使用“分工”的方式来管理,不同的功能使用不同的库。例如网络爬虫可以使用 Scrapy,而数据分析可以用 Pandas 等。分工才能更好地管理,在实际开发中,需要用到什么功能,导入对应的库即可。
对于 Python 来说,有那么一句话:学习 Python,其实就是学习 Python 的各种库。细想一下,这句话也是有一定道理的。
【问题 2】学习Python数据分析之前,要不要先学习 Excel?
实际上这是没有太大必要的。虽然有 Excel 基础可以帮助我们更快地学习,但即使没有任何 Excel 基础,我们也一样能轻松地学习 Python。
当然,如果你既学会了 Python 又掌握了 Excel,那么能在工作、面试时加分不少。
【问题 3】学习数据分析之前,要不要先学习网络爬虫?
从数据科学工作流程可以看出,网络爬虫用于获取数据,而数据分析用于处理数据。从正常角度来看,应该是先学会怎么获取数据,然后再学习怎样对数据进行处理。
实际上,网络爬虫、数据分析、数据可视化是可以完全独立开来学习的。虽然它们在应用时有着比较大的联系,但是学习时没有必然的先后顺序。读者完全可以根据自己的喜好来安排学习顺序。