Cypher WHERE语句用法详解(附带实例)
WHERE 语句的语法如下:
Neo4j Cypher 中的比较运算符包括 = 、< >、<、>、<=、>=,它们分别表示等于、不等于、小于、大于、小于或等于、大于或等于。
WHERE 语句中可以包含多个条件,条件之间通过布尔运算符进行连接。布尔运算符包括 AND(与)、OR(或)、NOT(非)、XOR(异或)等。
我们先删除图中的所有节点和关系,代码如下:
然后创建一些节点,代码如下:
最后创建关系,代码如下:
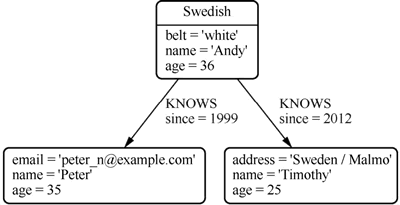
图 1 节点和关系构成的图
上述代码的返回值如下:
WHERE 语句中的 toLower 表示将大写字符串 AGE 转为小写字符串 age。上述代码的返回值如下:
基于正则表达式的过滤中可以使用 =~'regexp' 语句来匹配正则表达式,其中, regexp 表示正则表达式字符串。
例如,匹配 name 属性值为“Tim.*”形式的正则表达式的代码如下:
WHERE <property-name> <comparison-operator> <value>
- <property-name> 表示节点或关系的属性名称;
- <comparison-operator> 表示比较运算符;
- <value> 表示对应的属性值。
Neo4j Cypher 中的比较运算符包括 = 、< >、<、>、<=、>=,它们分别表示等于、不等于、小于、大于、小于或等于、大于或等于。
WHERE 语句中可以包含多个条件,条件之间通过布尔运算符进行连接。布尔运算符包括 AND(与)、OR(或)、NOT(非)、XOR(异或)等。
我们先删除图中的所有节点和关系,代码如下:
MATCH (n) DETACH DELETE n注意,上述代码会删除所有的节点及关系,读者在使用过程中一定要谨慎。
然后创建一些节点,代码如下:
CREATE (:Swedish {belt:"white",name:"Andy",age:36})
CREATE ({email:"peter_n@example.com",name:"Peter",age:35})
CREATE ({address:"Sweden/Malmo",name:"Timothy",age:25})
最后创建关系,代码如下:
MATCH (Andy:Swedish{name:"Andy"}),(Peter{name:"Peter"}),(Timothy{name:"Timothy"})
CREATE (Andy) - [:KNOWS{since:1999}] -> (Peter)
CREATE (Andy) - [:KNOWS{since:2012}] -> (Timothy)
上述节点和关系构成的图如下图所示:图 1 节点和关系构成的图
WHERE语句基本过滤
1) 布尔操作
匹配所有的节点,并对节点进行过滤,并返回符合如下过滤条件的节点,代码如下:- 节点的 name 属性值为 Peter;
- 异或节点的 age 属性值小于 30 且 name 属性值为“Timohthy”;
- 节点的 name 属性值不为“Timohthy”或“Peter”。
MATCH (n) WHERE n.name = 'Peter' XOR (n.age < 30 AND n.name = 'Timothy') OR NOT (n.name = 'Timothy' OR n.name = 'Peter') RETURN n.name, n.age这个过滤条件可能较为复杂,读者可以根据具体情况在代码中自行删减一些条件,以加深对代码的理解。
上述代码的返回值如下:
│"n.name" │"n.age"│ │"Andy" │36 │ │"Peter" │35 │ │"Timothy"│25 │
2) 过滤节点标签
过滤节点标签为 Swedish 的节点,并返回该节点的 name 和 age 属性值,代码如下:MATCH (n) WHERE n:Swedish RETURN n.name, n.age返回值如下:
│"n.name"│"n.age"│ │"Andy" │36 │
3) 过滤节点属性
匹配所有节点,过滤条件为节点的 age 属性值小于 30,过滤后返回节点的 name 和 age 属性值,代码如下:MATCH (n) WHERE n.age < 30 RETURN n.name, n.age返回值如下:
│"n.name" │"n.age" │ │"Timothy" │25 │
4) 过滤关系属性
匹配标签为 KNOWS 的关系,过滤 since 属性值小于 2000 的关系,并返回相关节点的对应属性值,代码如下:MATCH (n) - [k:KNOWS] -> (f) WHERE k.since < 2000 RETURN f.name, f.age, f.email返回值如下:
│"f.name" │"f.age" │"f.email" │ │"Peter" │35 │"peter_n@example.com"│
5) 过滤动态计算节点的属性
定义字符串 AGE 的别名为 propname,匹配并过滤所有节点,过滤条件为节点的 age 属性值小于 30。之后返回符合条件的节点的 name 和 age 属性,代码如下:WITH 'AGE' AS propname MATCH (n) WHERE n[toLower(propname)]< 30 RETURN n.name, n.age
WHERE 语句中的 toLower 表示将大写字符串 AGE 转为小写字符串 age。上述代码的返回值如下:
│"n.name" │"n.age" │ │"Timothy" │25 │
6) 过滤存在指定配置的节点或属性
过滤存在 belt 属性的节点,并返回节点的 name 和 age 属性,代码如下:MATCH (n) WHERE exists(n.belt) RETURN n.name, n.belt返回值如下:
│"n.name" │"n.belt" │ │"Andy" │"white" │
WHERE语句字符串过滤
当过滤条件为字符串时,字符串的前缀和后缀通过 STARTS WITH 和 ENDS WITH 语句进行匹配。对于子字符串搜索(不考虑字符串中的位置),可以使用 CONTAINS 语句。字符串匹配会区分字母大小写。对于非字符串的过滤,这些语句将返回 null。1) 使用STARTS WITH语句过滤字符串前缀
STARTS WITH 语句用于在字符串的开头执行匹配操作,代码如下:MATCH (n) WHERE n.name STARTS WITH 'Pet' RETURN n.name, n.age返回值如下:
│"n.name"│"n.age"│ │"Peter" │35 │返回的是 Peter 节点的 name 和 age 属性值,这是因为该节点的 name 属性值以“Pet”开头。
2) 使用ENDS WITH语句过滤字符串后缀
ENDS WITH 语句用于在字符串的结尾执行匹配操作,代码如下:MATCH (n) WHERE n.name ENDS WITH 'ter' RETURN n.name, n.age返回值如下:
│"n.name"│"n.age"│ │"Peter" │35 │返回的是 Peter 节点的 name 和 age 属性值,这是因为 name 属性值以“ter”结尾。
3) 使用CONTAINS语句搜索字符串
CONTAINS 语句用于判断是否包含指定字符串,区分字母大小写,不考虑字符串的具体位置。代码如下:MATCH (n) WHERE n.name CONTAINS 'ete' RETURN n.name, n.age返回值如下:
│"n.name"│"n.age"│ │"Peter" │35 │返回的是 Peter 节点的 name 和 age 属性值,这是因为该节点的 name 属性值包含“ete”。
3) 正则表达式过滤
Cypher 支持使用正则表达式进行过滤,其正则表达式语法继承自 Java 正则表达式的语法。正则表达式中支持改变字符串匹配方式的标志,其中包括不区分字母大小写(?i)、多行(?m)和逗点(?s)。标记位于正则表达式的开头,例如,不区分字母大小写的匹配代码如下:MATCH (n) WHERE n.name =~ '(?i)Lon.* ' RETURN n上述代码的返回值为 name 属性值为“London”或“LonDon”等的节点。
基于正则表达式的过滤中可以使用 =~'regexp' 语句来匹配正则表达式,其中, regexp 表示正则表达式字符串。
例如,匹配 name 属性值为“Tim.*”形式的正则表达式的代码如下:
MATCH (n) WHERE n.name =~ 'Tim.*' RETURN n.name, n.age返回值如下:
│"n.name" │"n.age"│ │"Timothy"│25 │
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: