C++ STL是什么(非常详细)
STL(standard template library,标准模板库) 的诞生是 C++ 发展史上一个重要的里程碑,对 C++ 开发产生了深远的影响。
首先,STL 使得 C++ 更加灵活和强大。STL 的设计理念基于泛型编程,使程序员可以更加高效地实现各种数据结构和算法,而不必关注具体的数据类型。这使得 C++ 语言具有了更高的可扩展性和通用性,同时也使得 C++ 更加容易学习和使用。
其次,STL 推动了软件开发的标准化和规范化。STL 成为 C++ 标准库的一部分,同时其设计理念和实现方式也影响了其他编程语言,成为了一种通用的编程模式和设计思想。
STL 到底有什么用呢?一起来体会下。假设要在 C++ 中定义一个数组,可以采用如下方式:
除了这种定义方式,还可以采用在堆空间中动态申请内存的方法,此时数组长度可以是变量:
但如果程序执行过程中出现空间不足的情况,需要加大存储空间时,就需要进行如下 3 步操作:
1) 新申请一个较大的内存空间,代码为:
2) 将原来内存空间的数据全部复制到新申请的内存空间中,代码为:
3) 将原来的堆空间释放,代码为:
而完成相同的操作,采用 STL 会简单很多,因为不用再关心内存操作细节。一起来看下 STL 向量容器 vector 可实现的功能:
数据结构指的是计算机存储、组织数据的方式,关注的焦点是数据的存储,以及存储后的增加、删除、修改、查询等操作。其中,最常用到的数据结构是线性结构,如数组、栈、队列和链表;非线性结构则包括树、堆、散列表、图等。
一种好的数据结构可以带来高效的运行效率或存储效率。
数组中,各元素在内存中是连续存放的,因此可通过数组名(或指针)和偏移量快速访问任意一个元素,但添加和删除数据却比较麻烦和耗时。因此,数组结构适用于需要频繁查询数据,但对存储空间要求不大,数据增、删操作较少的情况。
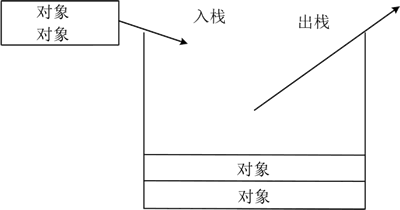
图 1 栈结构示意图
栈中,从栈顶放入数据的操作叫作入栈,取出数据的操作叫作出栈。栈不擅长在随机位置插入和删除对象(需要借助其他方法才能实现),比较耗时。若存储的对象超过自身容量,会发生栈溢出。
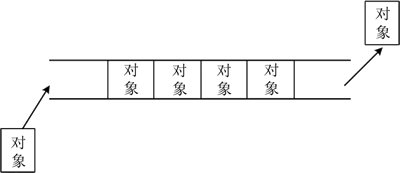
图 2 队列结构示意图
队列中,从一端放入元素的操作称为入队,从另一端取出元素的操作称为出队。队列结构分为顺序存储和链式存储两种。和栈一样,队列也不擅长在随机位置插入和删除对象。
单链表中每个结点含有 1 个指针,双向链表中每个结点含有两个指针,改变指针指向,就可以轻松地实现链表结点的增加和删除,如下图所示。
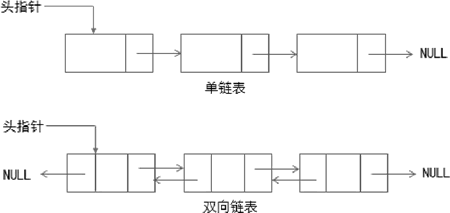
图 3 链表结构示意图
链表的存储空间是随机、分散的,无法通过索引快速定位元素,只能通过遍历自身找到元素,因此查找元素效率较低。
二叉树中,每个结点最多有两个子结点,左子树和右子树是有顺序的,次序不能颠倒。二叉树的结构示意图如下图所示。
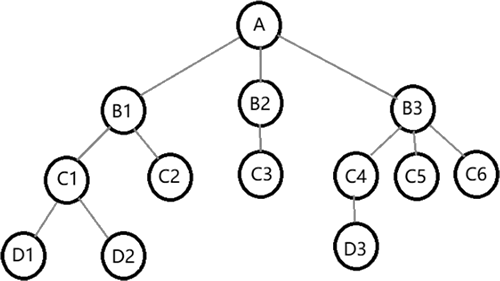
图 4 树结构示意图
使用二叉树添加和删除数据都非常快,查找数据方面也有很多优化的算法。所以,二叉树既有链表的好处,也有数组的好处,是两者的优化方案,在处理大批量的动态数据方面非常有用。
散列表的结构示意图如下图所示。
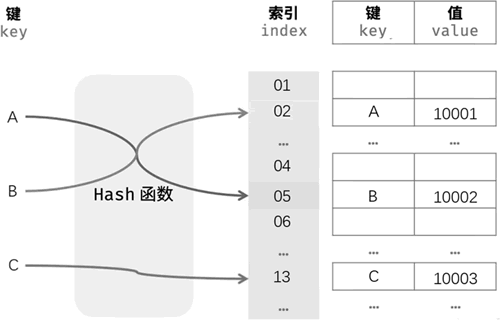
图 5 散列表结构示意图
散列表中,数据以键值对的形式存储。通过哈希函数,将键(key)映射为一个固定大小的数组索引,将值(value)存储在以该数字为下标的数组空间里。这种存储方式可以充分利用数组的优势来查找元素。散列表的关键是哈希函数的设计。散列表支持高效的数据插入、查找和删除操作。
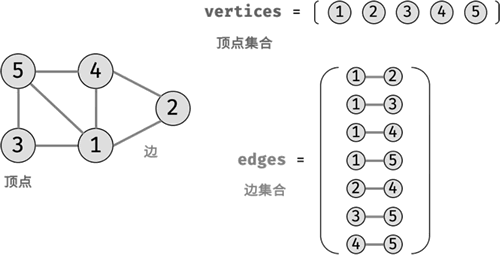
图 6 图结构示意图
根据边是否具有方向,可将图分为有向图和无向图。
STL 中,容器类对常用数据结构进行了实现、扩展和封装。在各类数据结构中均可实现元素的查询、插入、删除和修改操作。
注意,逻辑插入意味着元素所在的存储单元不发生真的插入操作。例如,数组元素所在的内存单元是连续的,无法在中间插入数据,因此数组插入操作的实质是:将数组元素和待插入元素复制给另外一个容量 +1 的数组,然后销毁原来的内存空间。逻辑删除的原理与此相同。
首先,STL 使得 C++ 更加灵活和强大。STL 的设计理念基于泛型编程,使程序员可以更加高效地实现各种数据结构和算法,而不必关注具体的数据类型。这使得 C++ 语言具有了更高的可扩展性和通用性,同时也使得 C++ 更加容易学习和使用。
其次,STL 推动了软件开发的标准化和规范化。STL 成为 C++ 标准库的一部分,同时其设计理念和实现方式也影响了其他编程语言,成为了一种通用的编程模式和设计思想。
STL 到底有什么用呢?一起来体会下。假设要在 C++ 中定义一个数组,可以采用如下方式:
int a[n];这种定义数组的方法需要事先知道数组的长度,因为 n 必须为常量。如果无法确定数组长度,就需要将数组长度设为可能的最大值,这会导致存储空间的极大浪费。
除了这种定义方式,还可以采用在堆空间中动态申请内存的方法,此时数组长度可以是变量:
int *p = new int[n];这种定义方式可根据变量 n 动态申请内存,不会出现存储空间浪费的问题。
但如果程序执行过程中出现空间不足的情况,需要加大存储空间时,就需要进行如下 3 步操作:
1) 新申请一个较大的内存空间,代码为:
int * temp = new int[m];
2) 将原来内存空间的数据全部复制到新申请的内存空间中,代码为:
memecpy(temp, p, sizeof(int)*n);
3) 将原来的堆空间释放,代码为:
delete [] p; p = temp;
而完成相同的操作,采用 STL 会简单很多,因为不用再关心内存操作细节。一起来看下 STL 向量容器 vector 可实现的功能:
vector<int> a; //使用 vector 容器定义动态数组 a for (int i = 0; i < 10; i++) //向 a 中添加 10 个元素 a.push_back(i); a.resize(100); //设置 a 的大小为 100 a[90] = 100; //为 a[90]赋值 100 a.clear(); //删除 a 中所有元素,a 的大小变为 0 a.resize(20, -1); //设置 a 的大小为 20,所有元素初始化为-1对比以上两种使用数组的方式,不难看出,使用 STL 可以更加灵活、方便地处理数据,既简单又高效。最关键的是,STL 使得开发者不用再关注底层数据结构的实现原理,直接使用就行。
C++ STL封装数据结构
C++ 模板设计的初衷是为了封装数据结构。数据结构指的是计算机存储、组织数据的方式,关注的焦点是数据的存储,以及存储后的增加、删除、修改、查询等操作。其中,最常用到的数据结构是线性结构,如数组、栈、队列和链表;非线性结构则包括树、堆、散列表、图等。
一种好的数据结构可以带来高效的运行效率或存储效率。
1) 数组
数组(array)是最典型的线性结构,其基本特点是数据元素是有限且有序的。数组会为每个存储的元素分配一个下标(索引),此下标从 0 开始,连续自增,通过数组名和下标可快速访问所有的元素。数组中,各元素在内存中是连续存放的,因此可通过数组名(或指针)和偏移量快速访问任意一个元素,但添加和删除数据却比较麻烦和耗时。因此,数组结构适用于需要频繁查询数据,但对存储空间要求不大,数据增、删操作较少的情况。
2) 栈
栈(stack)是一种特殊的线性结构,数据的存储和访问仅能在线性表的一端(即栈顶)进行,栈底则不允许操作。栈是一种“后进先出”的数据结构,类似于一个从上方打开的箱子,存取货物(数据)都只能通过一端进行,如下图所示。图 1 栈结构示意图
栈中,从栈顶放入数据的操作叫作入栈,取出数据的操作叫作出栈。栈不擅长在随机位置插入和删除对象(需要借助其他方法才能实现),比较耗时。若存储的对象超过自身容量,会发生栈溢出。
3) 队列
队列(queue)的特点是“先进先出”,即只能在线性表的一端插入数据,在另一端删除数据。这非常类似于生活中的排队,所有人(数据)都只能从队列的后方加入,从队列的前方离开,如下图所示。图 2 队列结构示意图
队列中,从一端放入元素的操作称为入队,从另一端取出元素的操作称为出队。队列结构分为顺序存储和链式存储两种。和栈一样,队列也不擅长在随机位置插入和删除对象。
4) 链表
链表(linked list)是一种非连续、非顺序的线性结构,由一系列结点组成。第一个元素的位置由头指针(head)给出,其后每个结点中都含有数据部分和指针部分,通过指针可访问下一个元素,链表尾部结点的指针指向空(NULL)。单链表中每个结点含有 1 个指针,双向链表中每个结点含有两个指针,改变指针指向,就可以轻松地实现链表结点的增加和删除,如下图所示。
图 3 链表结构示意图
链表的存储空间是随机、分散的,无法通过索引快速定位元素,只能通过遍历自身找到元素,因此查找元素效率较低。
5) 树
树(tree)是一种由多个结点组成的具有层次关系的集合,最常见的就是二叉树。之所以称为“树”,是因为这种数据结构从外观上看起来很像一棵倒挂的树,根结点在上,叶结点在下,所有结点都可用来存储数据。二叉树中,每个结点最多有两个子结点,左子树和右子树是有顺序的,次序不能颠倒。二叉树的结构示意图如下图所示。
图 4 树结构示意图
使用二叉树添加和删除数据都非常快,查找数据方面也有很多优化的算法。所以,二叉树既有链表的好处,也有数组的好处,是两者的优化方案,在处理大批量的动态数据方面非常有用。
6) 散列表
散列表(Hash table),又称为哈希表、哈希映射,是一种先建立映射关系,然后通过关键字访问其对应值的数据结构。散列表的结构示意图如下图所示。
图 5 散列表结构示意图
散列表中,数据以键值对的形式存储。通过哈希函数,将键(key)映射为一个固定大小的数组索引,将值(value)存储在以该数字为下标的数组空间里。这种存储方式可以充分利用数组的优势来查找元素。散列表的关键是哈希函数的设计。散列表支持高效的数据插入、查找和删除操作。
7) 图
图(graph)是一种复杂的非线性数据结构,可表示多对多的数据关系。图由顶点和边组成,每条边连接一对顶点,如下图所示。图 6 图结构示意图
根据边是否具有方向,可将图分为有向图和无向图。
STL 中,容器类对常用数据结构进行了实现、扩展和封装。在各类数据结构中均可实现元素的查询、插入、删除和修改操作。
- 查询:通过输入或根据已知条件,在数据结构中找到相应的元素;
- 插入:在各个元素之间,逻辑插入一个元素;
- 删除:在各个元素中,逻辑删除一个元素;
- 修改:通过输入或根据已知条件,在数据结构中修改相应的元素。
注意,逻辑插入意味着元素所在的存储单元不发生真的插入操作。例如,数组元素所在的内存单元是连续的,无法在中间插入数据,因此数组插入操作的实质是:将数组元素和待插入元素复制给另外一个容量 +1 的数组,然后销毁原来的内存空间。逻辑删除的原理与此相同。
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: