C语言union联合体的用法(非常详细)
在 C语言中,联合体(union)是一种特殊的数据类型,它允许在相同的内存位置存储不同类型的数据。联合体的大小等于其最大成员的大小。使用联合体时,同一时刻只能访问其中一个成员,因为其他成员的数据会被覆盖。
联合体常用于节省内存空间,特别是在嵌入式系统或处理大量数据时。下面是一个简单的联合体示例:
联合体的语法非常类似于结构体的语法,几乎仅仅换了一个关键字而已。让我们来看看它们之间的差别。我们先使用 sizeof 分别测试它们的大小,具体代码如下:
对于结构体来说,char 占用 1 字节,short 占用 2 字节,long long 占用 8 字节。它们如果相邻紧密排列,则在逻辑上将占用 11 字节。这两个结果似乎都有些奇怪,让我们输出它们成员的地址,详细地分析它们的内存分布情况,具体代码如下:
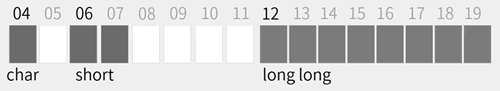
图 1 结构体的内存分布
我们注意到在 char 和 short 类型之间留出了 1 字节的空间,而在 short 和 long long 类型之间留出了 4 字节的空间。
这种现象被称为内存对齐。虽然这样做会浪费一些内存空间,但是对齐后的数据能够更快地被访问。因此,内存对齐可以提高数据访问速度。
内存对齐(memory alignment)是一种处理器、操作系统和编译器共同实现的优化策略,旨在提高数据访问速度。它要求数据在内存中以其自然边界对齐。具体来说,对于大小为 N 字节的数据类型,它的内存地址应该是 N 的整数倍。这是因为处理器在访问特定边界对齐的内存时,通常能更高效地读取和写入数据。内存对齐只需简单理解即可,无须深入探讨和研究。
下面我们来看看联合体中成员的内存分布情况。联合体 u 的成员 c、s 和 ll 在内存中的首地址都为 8649896,如下图所示:
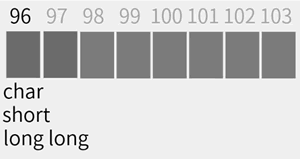
图 2 首地址重叠
我们可以看到,联合体中不同成员的首地址是重叠的。
首先,程序将 123 赋值给 u.c,然后输出它。输出将显示 u.c = 123。
接着,程序将 0 赋值给 u.s。由于联合体成员共享同一内存空间,这将覆盖 u.c 的值。然后,程序再次输出 u.c 的值,输出将显示 u.c = 0。这是因为赋值给 u.s 的操作已经改变了共享的内存内容。程序执行结果为:
如果我们用结构体 struct 来存储这种信息,那么结构体中就需要准备三个不同类型的成员。由于一次只会出现一种形态,因此每次仅用一个成员,其他两个成员便会留空。另外,还需要一个整型的 type 成员来标记这一次是什么类型。
例如:1 代表整型,2 代表浮点,3 代表字符串。根据上述的内容,我们可以写出如下的结构体:
接下来,我们可以定义一个函数 printMsg(),根据消息的 type 使用不同的方式处理消息。
完整的代码如下:
printMsg() 函数接收一个 message 类型的参数,根据 type 成员的值来输出不同类型的数据。如果 type 为 1,则输出整数;如果为 2,则输出浮点数;如果为 3,则输出字符串。
在 main() 函数中,我们创建了一个 message 类型的数组 msg,包含三个元素,并且为这三个元素分别赋值。第一个元素表示一个整数,所以将 type 设为 1。第二个元素表示一个浮点数,所以将 type 设为 2。第三个元素表示一个字符串,所以将 type 设为 3。
然后,我们使用一个 for 循环遍历数组,调用 printMsg() 函数输出每个元素的值。
运行结果如下,该程序成功输出了对应的值。
这种改进能够节省内存空间,因为使用联合体只会为 int n、float f和char *str 中最大的成员分配空间。联合体成员共享内存,因此整个结构体占用的空间会减少。
另外,还有一种匿名嵌套的写法。嵌套的 union 中没必要写明成员名 u。在其后的使用中,union 中的成员被当作 message 的成员一样处理。
联合体常用于节省内存空间,特别是在嵌入式系统或处理大量数据时。下面是一个简单的联合体示例:
union {
char c;
short s;
long long ll;
}u;
联合体的语法非常类似于结构体的语法,几乎仅仅换了一个关键字而已。让我们来看看它们之间的差别。我们先使用 sizeof 分别测试它们的大小,具体代码如下:
#include <stdio.h>
int main()
{
struct {
char c;
short s;
long long ll;
} s;
union {
char c;
short s;
long long ll;
} u;
printf("sizeof s %d\n", sizeof(s));
printf("sizeof u %d\n", sizeof(u));
return 0;
}
运行结果如下:
sizeof s 16
sizeof u 8
对于结构体来说,char 占用 1 字节,short 占用 2 字节,long long 占用 8 字节。它们如果相邻紧密排列,则在逻辑上将占用 11 字节。这两个结果似乎都有些奇怪,让我们输出它们成员的地址,详细地分析它们的内存分布情况,具体代码如下:
#include <stdio.h>
int main()
{
struct {
char c;
short s;
long long ll;
} s;
union {
char c;
short s;
long long ll;
} u;
printf("&s.c %d \n", &s.c);
printf("&s.s %d \n", &s.s);
printf("&s.ll %d \n\n", &s.ll);
printf("&u.c %d \n", &u.c);
printf("&u.s %d \n", &u.s);
printf("&u.ll %d \n", &u.ll);
return 0;
}
运行结果为:
&s.c 8649904
&s.s 8649906
&s.ll 8649912
&u.c 8649896
&u.s 8649896
&u.ll 8649896
图 1 结构体的内存分布
我们注意到在 char 和 short 类型之间留出了 1 字节的空间,而在 short 和 long long 类型之间留出了 4 字节的空间。
这种现象被称为内存对齐。虽然这样做会浪费一些内存空间,但是对齐后的数据能够更快地被访问。因此,内存对齐可以提高数据访问速度。
内存对齐(memory alignment)是一种处理器、操作系统和编译器共同实现的优化策略,旨在提高数据访问速度。它要求数据在内存中以其自然边界对齐。具体来说,对于大小为 N 字节的数据类型,它的内存地址应该是 N 的整数倍。这是因为处理器在访问特定边界对齐的内存时,通常能更高效地读取和写入数据。内存对齐只需简单理解即可,无须深入探讨和研究。
下面我们来看看联合体中成员的内存分布情况。联合体 u 的成员 c、s 和 ll 在内存中的首地址都为 8649896,如下图所示:
图 2 首地址重叠
我们可以看到,联合体中不同成员的首地址是重叠的。
C语言联合体的性质
由于联合体中的各成员之间存在重叠的部分,存储一个成员后,将覆盖其他成员的数据。下面的程序展示了一个使用联合体的示例。
#include <stdio.h>
int main()
{
union {
char c;
short s;
long long ll;
} u;
u.c = 123;
printf("u.c = %d\n", u.c);
u.s = 0;
printf("u.c = %d\n", u.c);
return 0;
}
这段代码定义了一个联合体 u,包含了三个成员:char c、short s 和 long long ll。接下来,程序执行以下操作:首先,程序将 123 赋值给 u.c,然后输出它。输出将显示 u.c = 123。
接着,程序将 0 赋值给 u.s。由于联合体成员共享同一内存空间,这将覆盖 u.c 的值。然后,程序再次输出 u.c 的值,输出将显示 u.c = 0。这是因为赋值给 u.s 的操作已经改变了共享的内存内容。程序执行结果为:
u.c = 123
u.c = 0
C语言联合体的应用
下面是一个使用联合体的应用示例。假设有一种信息它只有三种形态,即整数、浮点数和字符串,并且一次只能出现一种形态。如果我们用结构体 struct 来存储这种信息,那么结构体中就需要准备三个不同类型的成员。由于一次只会出现一种形态,因此每次仅用一个成员,其他两个成员便会留空。另外,还需要一个整型的 type 成员来标记这一次是什么类型。
例如:1 代表整型,2 代表浮点,3 代表字符串。根据上述的内容,我们可以写出如下的结构体:
struct message {
int type;
int n;
float f;
char *str;
};
接下来,我们可以定义一个函数 printMsg(),根据消息的 type 使用不同的方式处理消息。
void printMsg(struct message msg)
{
switch (msg.type)
{
case 1:
printf("%d\n", msg.n);
break;
case 2:
printf("%f\n", msg.f);
break;
case 3:
printf("%s\n", msg.str);
break;
}
}
完整的代码如下:
#include <stdio.h>
struct message {
int type;
int n;
float f;
char *str;
};
void printMsg(struct message msg)
{
switch (msg.type)
{
case 1:
printf("%d\n", msg.n);
break;
case 2:
printf("%f\n", msg.f);
break;
case 3:
printf("%s\n", msg.str);
break;
}
}
int main()
{
struct message msg[3];
// 第一条信息为整型,type 为 1
msg[0].type = 1;
msg[0].n = 123;
// 第二条信息为浮点型,type 为 2
msg[1].type = 2;
msg[1].f = 3.1415926;
// 第三条信息为字符串,type 为 3
msg[2].type = 3;
msg[2].str = "HelloWorld";
for (int i = 0; i < 3; i++)
{
printMsg(msg[i]);
}
return 0;
}
这段代码定义了一个名为 message 的结构体,用于存储不同类型的数据(整数、浮点数和字符串)。printMsg() 函数接收一个 message 类型的参数,根据 type 成员的值来输出不同类型的数据。如果 type 为 1,则输出整数;如果为 2,则输出浮点数;如果为 3,则输出字符串。
在 main() 函数中,我们创建了一个 message 类型的数组 msg,包含三个元素,并且为这三个元素分别赋值。第一个元素表示一个整数,所以将 type 设为 1。第二个元素表示一个浮点数,所以将 type 设为 2。第三个元素表示一个字符串,所以将 type 设为 3。
然后,我们使用一个 for 循环遍历数组,调用 printMsg() 函数输出每个元素的值。
运行结果如下,该程序成功输出了对应的值。
123
3.141593
HelloWorld
struct message
{
int type;
union {
int n;
float f;
char *str;
} u;
};
当然,type 成员必须有,否则无法判断是什么类型的信息。收到消息后,程序还需要根据消息的 type 使用不同的方式进行处理。确定 type 后,程序从 msg 中找到联合体成员 u,再根据类型,并选择对应的成员进行处理。完整的代码如下:
#include <stdio.h>
struct message {
int type;
union {
int n;
float f;
char* str;
} u;
};
void printMsg(struct message msg)
{
switch (msg.type)
{
case 1:
printf("%d\n", msg.u.n);
break;
case 2:
printf("%f\n", msg.u.f);
break;
case 3:
printf("%s\n", msg.u.str);
break;
}
}
int main()
{
struct message msg[3];
// 第一条信息为整型,type 为 1
msg[0].type = 1;
msg[0].u.n = 123;
// 第二条信息为浮点型,type 为 2
msg[1].type = 2;
msg[1].u.f = 3.14159;
// 第三条信息为字符串,type 为 3
msg[2].type = 3;
msg[2].u.str = "HelloWorld";
for (int i = 0; i < 3; i++)
{
printMsg(msg[i]);
}
return 0;
}
与前面的示例相比,这段代码将结构体中的 int n、float f 和 char *str 成员替换为一个名为 u 的联合体。联合体 u 包含三个成员:int n、float f和char *str。这种改进能够节省内存空间,因为使用联合体只会为 int n、float f和char *str 中最大的成员分配空间。联合体成员共享内存,因此整个结构体占用的空间会减少。
另外,还有一种匿名嵌套的写法。嵌套的 union 中没必要写明成员名 u。在其后的使用中,union 中的成员被当作 message 的成员一样处理。
struct message
{
int type;
union {
int n;
float f;
char *str; // 这里省略成员名 u 作为匿名嵌套成员
};
};
void printMsg(struct message msg)
{
switch (msg.type)
{
case 1:
printf("%d\n", msg.n); // msg.u.n 被省略为 msg.n
break;
case 2:
printf("%f\n", msg.f); // msg.u.f 被省略为 msg.f
break;
case 3:
printf("%s\n", msg.str); // msg.u.str 被省略为 msg.str
break;
}
}
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: