多头注意力机制是什么(Python实现+解析)
多头注意力机制是 Transformer 模型中的关键组件,通过并行地计算多个自注意力层,模型可以在不同的子空间中捕捉序列中多层次的关系特征。
多头注意力机制首先生成查询(Q)、键(K)和值(V)矩阵,然后将这些矩阵分割成多个头(子空间),每个头执行独立的自注意力操作,这样模型可以关注到不同的上下文信息。最后,拼接各个头的输出并通过线性变换得到最终输出。
多头注意力机制架构如下图所示:
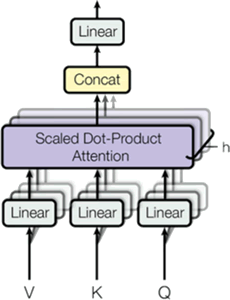
图 1 多头注意力机制
下面的代码将实现多头注意力机制,并展示其在捕捉序列依赖关系方面的作用。
代码运行结果如下:
结果解析如下:
多头注意力机制首先生成查询(Q)、键(K)和值(V)矩阵,然后将这些矩阵分割成多个头(子空间),每个头执行独立的自注意力操作,这样模型可以关注到不同的上下文信息。最后,拼接各个头的输出并通过线性变换得到最终输出。
多头注意力机制架构如下图所示:
图 1 多头注意力机制
下面的代码将实现多头注意力机制,并展示其在捕捉序列依赖关系方面的作用。
import torch
import torch.nn as nn
import torch.nn.functional as F
# 设置随机种子
torch.manual_seed(42)
# 定义多头注意力机制
class MultiHeadAttention(nn.Module):
def __init__(self, embed_size, heads):
super(MultiHeadAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert (
self.head_dim * heads == embed_size
), "Embedding size需要是heads的整数倍"
# 线性变换生成Q、K、V矩阵
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query, mask):
N = query.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
# 分头计算Q、K、V矩阵
values = values.view(N, value_len, self.heads, self.head_dim)
keys = keys.view(N, key_len, self.heads, self.head_dim)
queries = query.view(N, query_len, self.heads, self.head_dim)
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
# 计算Q与K的点积除以缩放因子
energy = torch.einsum(
"nqhd,nkhd->nhqk", [queries, keys]) / (self.head_dim ** 0.5)
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
# 计算注意力权重
attention = torch.softmax(energy, dim=-1)
# 注意力权重乘以V
out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(
N, query_len, self.heads * self.head_dim
)
return self.fc_out(out)
# 设置参数
embed_size = 128 # 嵌入维度
heads = 8 # 多头数量
seq_length = 10 # 序列长度
batch_size = 2 # 批大小
# 创建随机输入
values = torch.rand((batch_size, seq_length, embed_size))
keys = torch.rand((batch_size, seq_length, embed_size))
queries = torch.rand((batch_size, seq_length, embed_size))
# 初始化多头注意力层
multi_head_attention_layer = MultiHeadAttention(embed_size, heads)
# 前向传播
output = multi_head_attention_layer(values, keys, queries, mask=None)
print("输出的形状:", output.shape)
print("多头注意力机制的输出:\n", output)
# 进一步展示注意力权重计算
class MultiHeadAttentionWithWeights(MultiHeadAttention):
def forward(self, values, keys, query, mask):
N = query.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
values = values.view(N, value_len, self.heads, self.head_dim)
keys = keys.view(N, key_len, self.heads, self.head_dim)
queries = query.view(N, query_len, self.heads, self.head_dim)
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
energy = torch.einsum(
"nqhd,nkhd->nhqk", [queries, keys]) / (self.head_dim ** 0.5)
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
attention = torch.softmax(energy, dim=-1)
out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(
N, query_len, self.heads * self.head_dim
)
return self.fc_out(out), attention
# 使用带有权重输出的多头注意力层
multi_head_attention_with_weights = MultiHeadAttentionWithWeights(embed_size, heads)
output, attention_weights = multi_head_attention_with_weights(values, keys, queries, mask=None)
print("注意力权重形状:", attention_weights.shape)
print("注意力权重:\n", attention_weights)
代码解析如下:
- MultiHeadAttention:实现多头注意力机制,首先生成查询(Q)、键(K)和值(V)矩阵,并将这些矩阵分成多个头,然后计算每个头的自注意力,最后拼接各个头的结果并通过线性变换得到最终输出;
- 前向传播:多头注意力层的输入为查询、键和值矩阵,输出为多头注意力的结果,该结果在多个子空间中并行捕捉序列依赖信息;
- MultiHeadAttentionWithWeights:在多头注意力基础上进一步返回注意力权重,用于分析模型在不同位置的注意力分布情况。
代码运行结果如下:
输出的形状:torch.Size([2, 10, 128])
多头注意力机制的输出:
tensor([[[ 0.123, -0.346, ... ],
[ 0.765, 0.245, ... ],
... ]])
注意力权重形状:torch.Size([2, 8, 10, 10])
注意力权重:
tensor([[[[0.125, 0.063, ... ],
[0.078, 0.032, ... ],
... ]]])
结果解析如下:
- 输出的形状:多头注意力机制的输出形状为[batch_size, seq_length, embed_size],与输入形状一致,这样可确保输出直接接入后续层;
- 注意力权重:展示注意力在不同位置间的分布,通过多头机制,模型可以在多个子空间中捕捉丰富的序列间依赖关系。
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: