Java DOM4J解析xml文件(非常详细,附带实例)
XML 解析指通过解析器读取 XML 文件,将数据解析成不同的格式。对 XML 的一切操作都是由解析开始的,因此解析非常重要。
解析 XML 文件,主要有两种不同底层形式,一种是基于树形结构的 DOM 解析,另一种是基于事件流的 SAX 解析。DOM 是 W3C 组织推荐的处理 XML 的一种方式。SAX 不是官方标准,但它是 XML 社区实际上的标准,几乎所有的 XML 解析器都支持它。
DOM(Document Object Model)翻译为文档对象模型,是基于树形结构的 XML 解析,也是 Java 自带的 XML 解析方式。它要求解析器把整个 XML 文件装载到内存,并解析成一个 Document 对象。解析之后,元素与元素之间仍保留结构关系,方便对其进行增、删、改、查操作。不足之处在于,如果 XML 文件过大,可能会出现内存溢出问题。
SAX(Simple API for XML)是基于事件流的 XML 文件解析,是一种速度更快,更有效的方式,对 XML 文件逐行扫描,一边扫描一边解析,每执行一行,都会触发对应的事件。相比 DOM 解析方式,它不会出现内存问题,而且可以处理大的文件,但 SAX 解析只能从上到下按顺序读取文件,不能回写。
DOM 与 SAX 的对比如下表所示:
在这两种解析方式的基础上,基于底层 API 的、进行更高级封装的解析器也应运而生,比如面向 Java 的 JDOM、DOM4J 和 PULL 等。XML 解析技术体系如下图所示,DOM 解析相对简单,效率较高,后台多采用此种方式解析,需要重点掌握。而 SAX 解析主要适用于移动平台,这里了解即可。
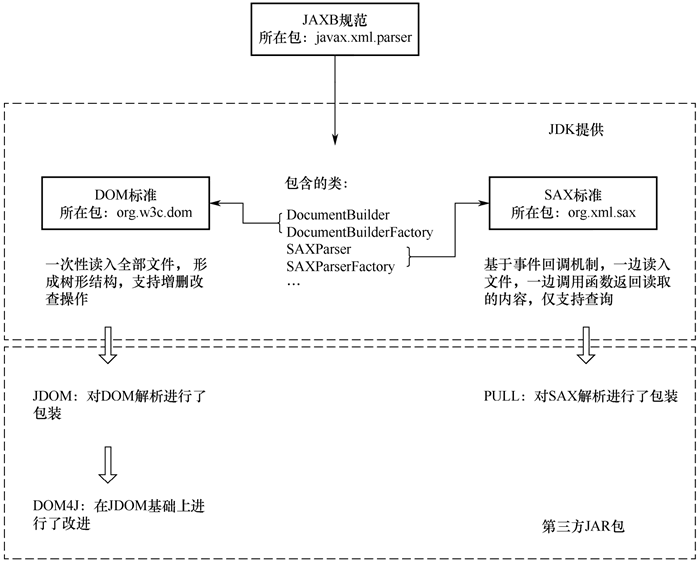
图 1 XML解析技术体系
接下来,我们重点介绍一下 DOM4J 的常用 API,以及解析 XML 文件的具体步骤。
与 JDOM 不同的是,DOM4J 使用接口和抽象基类,虽然 DOM4J 的 API 相对要复杂一些,但它提供了比 JDOM 更好的灵活性。DOM4J 可以用于处理 XML、XPath 和 XSLT,它基于 Java 平台,使用 Java 的集合框架,全面集成了 DOM、SAX 和 JAXP。
下面介绍 DOM4J 常用的 API。
1) 创建 SAXReader 对象,读取 XML 文件:
2) 解析 XML 获取 Document 对象,需要传入要解析的 XML 文件的字节输入流:
3) 通过 Document 对象,获取 XML 文件中的根标签:
4) 获取标签的子标签,包括获取所有子标签及根据指定标签名获取:
5) 获取标签的名字:
6) 获取子标签体内的文本内容:
7) 获取标签的某个属性的值:
了解了 DOM4J 的常用 API,接下来我们就可以应用它来解析文件了。使用 DOM4J 解析 XML 文件,具体步骤如下。
下面演示使用 DOM4J 对 teachers.xml 文件进行解析。teachers.xml 文件示例代码如下:
使用 DOM4J 解析并遍历该文件,示例代码如下:
另外,DOM4J 还能够对 XML 文件进行增、删、改操作。例如,使用 DOM4J 对 teacher.xml 文件进行修改,演示添加新结点、修改 XML 文件的格式,该内容了解即可,示例代码如下:
在 teachers.xml 文件中,使用 DOM4J 创建 XML 文件,并添加 teacher 结点,示例代码如下:
解析 XML 文件,主要有两种不同底层形式,一种是基于树形结构的 DOM 解析,另一种是基于事件流的 SAX 解析。DOM 是 W3C 组织推荐的处理 XML 的一种方式。SAX 不是官方标准,但它是 XML 社区实际上的标准,几乎所有的 XML 解析器都支持它。
DOM(Document Object Model)翻译为文档对象模型,是基于树形结构的 XML 解析,也是 Java 自带的 XML 解析方式。它要求解析器把整个 XML 文件装载到内存,并解析成一个 Document 对象。解析之后,元素与元素之间仍保留结构关系,方便对其进行增、删、改、查操作。不足之处在于,如果 XML 文件过大,可能会出现内存溢出问题。
SAX(Simple API for XML)是基于事件流的 XML 文件解析,是一种速度更快,更有效的方式,对 XML 文件逐行扫描,一边扫描一边解析,每执行一行,都会触发对应的事件。相比 DOM 解析方式,它不会出现内存问题,而且可以处理大的文件,但 SAX 解析只能从上到下按顺序读取文件,不能回写。
DOM 与 SAX 的对比如下表所示:
| DOM | SAX | |
|---|---|---|
| 速度 | 需要一次性加载整个 XML 文件,然后将其转换为 DOM 树,速度较差 | 顺序解析 XML 文件,无须将整个 XML 都加载到内存中,速度快 |
| 重复访问 | 将 XML 转换为 DOM 树之后,在解析时,DOM 树将常驻内存,可以重复访问 | 顺序解析 XML 文件,已解析过的数据,如果没有保存,将不能获得,除非重新解析 |
| 内存要求 | 内存占用较大 | 内存占用率低 |
| 增、删、改、查操作 | 可以对 XML 文件进行增、删、改、查操作 | 只能进行解析(查询操作) |
| 复杂度 | 完全面向对象的解析方式,容易使用 | 采用事件回调机制,通过事件的回调函数来解析 XML 文件,略复杂 |
在这两种解析方式的基础上,基于底层 API 的、进行更高级封装的解析器也应运而生,比如面向 Java 的 JDOM、DOM4J 和 PULL 等。XML 解析技术体系如下图所示,DOM 解析相对简单,效率较高,后台多采用此种方式解析,需要重点掌握。而 SAX 解析主要适用于移动平台,这里了解即可。
图 1 XML解析技术体系
- JDOM(Java-based Document Object Model):基于 Java 优化的文档对象模型。简化了 DOM 解析,针对 Java 进行了优化。
- DOM4J:DOM4J 是一个非常优秀的 Java XML API,具有性能优异、功能强大和极易使用的特点,同时它也是一个开放源代码的软件。如今,越来越多的 Java 软件都在使用 DOM4J 读写 XML。
- PULL:Android 内置的 XML 解析方式,类似于 SAX,都是轻量级的解析。区别在于,SAX 属于被动解析,一旦开始解析,则必须等待解析完成,期间不能控制事件的处理而主动结束。但 PULL 属于主动解析,可以在满足需要的条件后停止解析,不再获取事件,比 SAX 更加灵活。
接下来,我们重点介绍一下 DOM4J 的常用 API,以及解析 XML 文件的具体步骤。
DOM4J解析XML文件
DOM4J 是一个简单、灵活的开放源代码库,由早期开发 JDOM 的团队分离出来后独立开发。与 JDOM 不同的是,DOM4J 使用接口和抽象基类,虽然 DOM4J 的 API 相对要复杂一些,但它提供了比 JDOM 更好的灵活性。DOM4J 可以用于处理 XML、XPath 和 XSLT,它基于 Java 平台,使用 Java 的集合框架,全面集成了 DOM、SAX 和 JAXP。
下面介绍 DOM4J 常用的 API。
1) 创建 SAXReader 对象,读取 XML 文件:
SAXReader saxReader = new SAXReader();
2) 解析 XML 获取 Document 对象,需要传入要解析的 XML 文件的字节输入流:
Document document = saxReader.read(inputStream);
3) 通过 Document 对象,获取 XML 文件中的根标签:
Element rootElement = document.getRootElement();
4) 获取标签的子标签,包括获取所有子标签及根据指定标签名获取:
// 获取所有子标签
List<Element> sonElementList = rootElement.elements();
// 获取指定标签名的子标签
List<Element> sonElementList = rootElement.elements("标签名");
5) 获取标签的名字:
String text = element.getName();
6) 获取子标签体内的文本内容:
String text = element.elementText("标签名");
7) 获取标签的某个属性的值:
String value = element.attributeValue("属性名");
了解了 DOM4J 的常用 API,接下来我们就可以应用它来解析文件了。使用 DOM4J 解析 XML 文件,具体步骤如下。
- 导入 DOM4J 相应的 jar 包;
- 创建解析器对象(SAXReader);
- 解析 XML 文件获得 Document 对象,Document 对象指的是加载到内存的整个 XML 文件;
- 获取根结点 RootElement,根结点的类型为 Element 对象,指的是 XML 文件中的单个结点;
- 获取根结点下的子结点。
下面演示使用 DOM4J 对 teachers.xml 文件进行解析。teachers.xml 文件示例代码如下:
<?xml version="1.0" encoding="UTF-8"?>
<teachers>
<teacher id="1">
<tname>王老师</tname>
<tage>35</tage>
</teacher>
<teacher id="2">
<tname>张老师</tname>
<tage>50</tage>
</teacher>
</teachers>
使用 DOM4J 解析并遍历该文件,示例代码如下:
// 1、创建解析器对象
SAXReader reader = new SAXReader();
// 2、使用解析器将 XML 文件转换为内存中的 document 对象
// 注意: teachers.xml 位置是相对在项目根路径下查找 XML 文件
Document document = reader.read("teachers.xml");
// 3、通过 Document 对象可以获取 XML 文件的根标签
Element rootElement = document.getRootElement();
// 4、根据根标签获取所有根标签的子标签集合
List<Element> elements = rootElement.elements();
// 5、遍历集合中的标签,并将所有的数据解析出来
for (Element element : elements) {
// 每次遍历就代表一个 teacher 信息
System.out.println("正在遍历的标签名:" + element.getName());
System.out.println("正在遍历标签的 id 属性值:" + element.attributeValue("id"));
// 获取 teacher 的子标签的内容
String tname = element.elementText("tname");
System.out.println("tname:" + tname);
}
另外,DOM4J 还能够对 XML 文件进行增、删、改操作。例如,使用 DOM4J 对 teacher.xml 文件进行修改,演示添加新结点、修改 XML 文件的格式,该内容了解即可,示例代码如下:
SAXReader reader = new SAXReader();
Document document = reader.read("teachers.xml");
Element rootElement = document.getRootElement();
// 添加一个新的 teacher 结点
Element newEle = rootElement.addElement("teacher");
// 创建一个良好的 xml 格式
OutputFormat format = OutputFormat.createPrettyPrint();
// 写入文件
XMLWriter xmlWriter = new XMLWriter(new FileWriter("teachers.xml"), format);
xmlWriter.write(document);
xmlWriter.close();
在 teachers.xml 文件中,使用 DOM4J 创建 XML 文件,并添加 teacher 结点,示例代码如下:
// 1. 创建 XML 文件
Document document = DocumentHelper.createDocument();
// 2. 添加根元素
Element root = document.addElement("teachers");
// 3. 添加元素结点
Element tceEle1 = root.addElement("teacher");
Element tceEle2 = root.addElement("teacher");