Tesseract OCR下载、安装和使用教程(附官网安装包,非常详细)
Tesseract OCR 是一款开源、免费的文字识别工具,它能够把图片上的文字识别出来,并整理成可复制、编辑的文本。

Tesseract OCR 可以识别多种格式的图片,包括 PNG、JPEG、TIFF、GIF、BMP、PNM 等。相应地,它可以将识别出的文本整理到 Txt、PDF、HTML 等格式的文件里。
Tesseract OCR 能够识别 100+ 多种语言的文字,包括常用的英文和简体中文。我们提供的图片清晰度越好,它识别的准确度越高。
和 Tesseract OCR 同赛道的工具有很多,比如主流的 ABBYY FineReader 、EasyOCR、百度智能云 OCR 等。相比之下,Tesseract OCR 的优势是完全免费,离线状态下也可以使用,支持跨平台(Windows、Linux 和 Mac OS),经过训练可以完成更负责的识别任务。
注意,Tesseract OCR 是不带图形界面的,只能编写命令或者程序操控它,这一点对新手不太友好。不过,普通用户只需要记住几条最常用的命令,也足够用了。
普通用户直接选择 .exe 安装包,具备编程能力的小伙伴可以尝试 .zip 和 .tar.gz。
1) 下载得到 tesseract-ocr-w64-setup-5.5.0.20241111.exe,双击运行,保持默认的 English 语言,点击“OK”:
2) 点击“Next”:
3) 点击“I Agree”:

4) 继续点击“Next”:
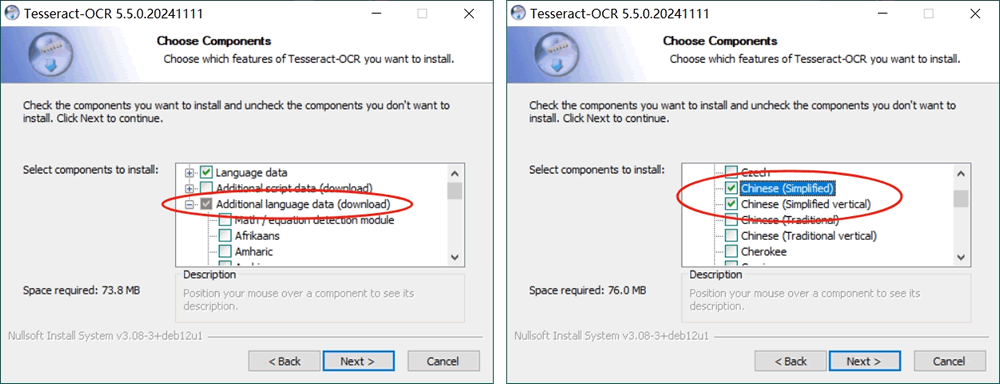
5) Tesseract OCR 默认是不识别中文的,这里我们需要手动勾选上,如下图所示。当然,大家可以把所有感兴趣的语言都勾选上。然后点击“Next”:
6) Tesseract OCR 默认是安装到 C 盘(系统盘),强烈建议手动安装到其它盘,比如下图中的 D 盘,然后点击 “Next”:

7) 点击 “Install”:

8) 等待安装完成,然后点击“Next”:

9) 出现下图所示的窗口,表示安装完成:
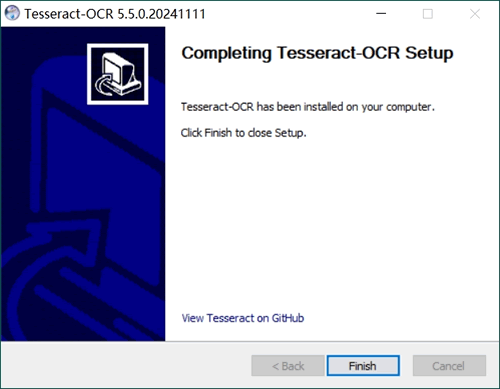
1) 配置环境变量,步骤如下:
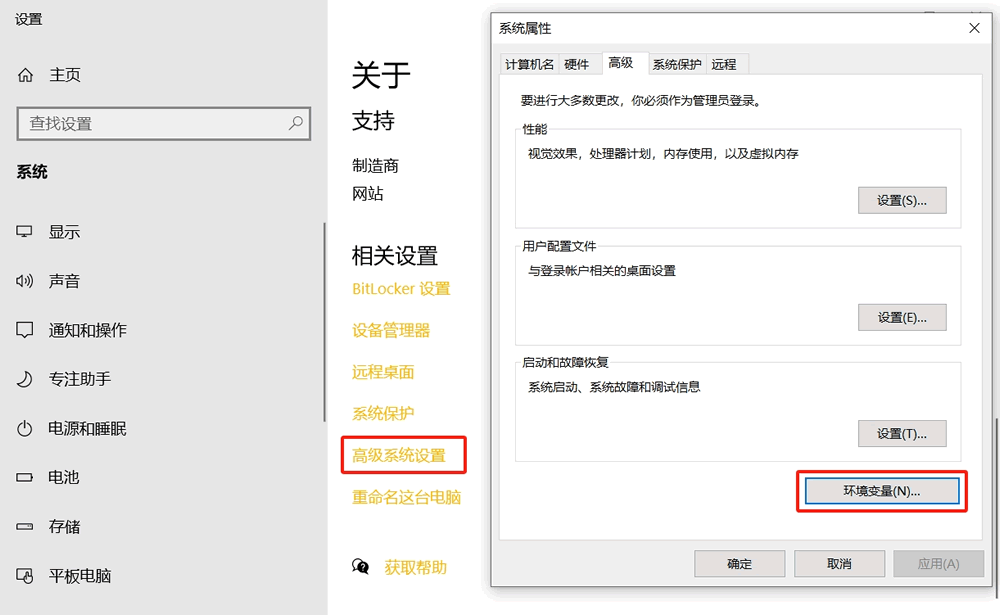
① 按照下图所示,打开电脑的设置窗口:

② 按照下图找到环境变量的设置入口:
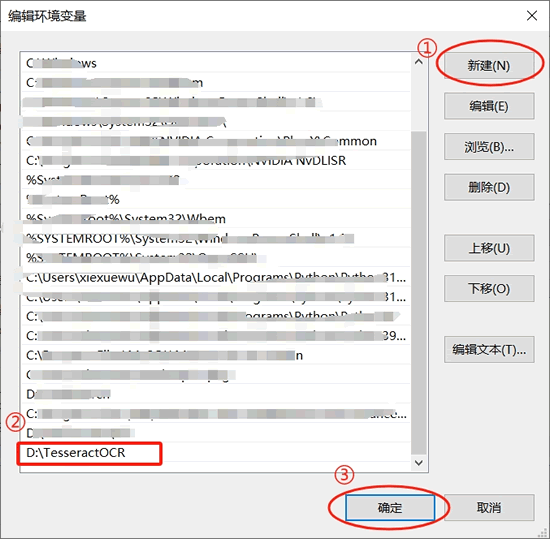
③ 找到系统变量 Path,双击打开它:

④ 在 Path 系统变量中,添加 Tesseract OCR 的安装路径,比如笔者将它安装到了 D 盘下的 TesseractOCR 文件夹里:
2) 检测环境变量是否配置成功。按“Win+R”组合键,输入“cmd” 打开 CMD 命令行窗口,如下图所示,输入 tesseract -v 命令:
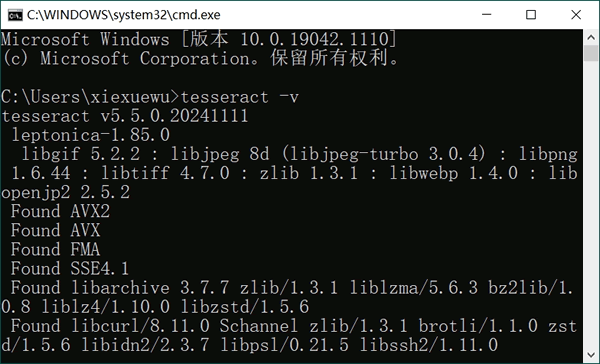
输出了 Tesseract OCR 的版本信息,表示安装成功了,接下来就可以使用 Tesseract OCR 识别图片了。
3) 接下来,我们以下面的图片为例,教大家编写 cmd 命令来操控 Tesseract OCR:

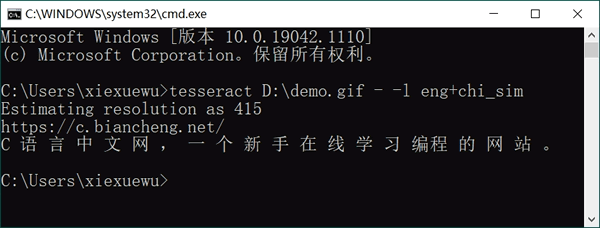
这张图的存储位置是:D:\demo.gif,在 CMD 命令行窗口中执行如下命令:
可以看到,Tesseract OCR 识别出了图片中的所有字母和汉字。
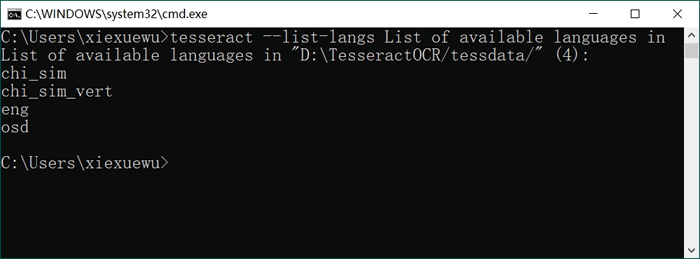
通过执行如下命令,可以查看 Tesseract OCR 当前支持识别的语言:
我们还可以指定 Tesseract OCR 将识别出的内容存储到指定的文件里,比如执行如下指令:

执行完成后,D 盘下会新增一个名叫 temp 的 txt 文本文件,里面就有 Tesseract OCR 识别的全部内容:

关于 tesseract 更复杂的用法,大家可以执行 tesseract man 命令查看,或者前往 tesseract 说明页面,这里不再过多赘述。
Tesseract OCR 可以识别多种格式的图片,包括 PNG、JPEG、TIFF、GIF、BMP、PNM 等。相应地,它可以将识别出的文本整理到 Txt、PDF、HTML 等格式的文件里。
Tesseract OCR 能够识别 100+ 多种语言的文字,包括常用的英文和简体中文。我们提供的图片清晰度越好,它识别的准确度越高。
和 Tesseract OCR 同赛道的工具有很多,比如主流的 ABBYY FineReader 、EasyOCR、百度智能云 OCR 等。相比之下,Tesseract OCR 的优势是完全免费,离线状态下也可以使用,支持跨平台(Windows、Linux 和 Mac OS),经过训练可以完成更负责的识别任务。
注意,Tesseract OCR 是不带图形界面的,只能编写命令或者程序操控它,这一点对新手不太友好。不过,普通用户只需要记住几条最常用的命令,也足够用了。
下载Tesseract OCR
Tesseract OCR 官方发布了 3 种安装包:- tesseract-ocr-w64-setup-5.5.0.20241111.exe:适用于 Windows 平台的安装包;
- tesseract-5.5.0.zip 和 tesseract-5.5.0.tar.gz 都是源代码压缩包,前者适用于 Windows,后者适用于 Linux 和 Mac OS。
普通用户直接选择 .exe 安装包,具备编程能力的小伙伴可以尝试 .zip 和 .tar.gz。
安装Tesseract OCR
笔者的电脑系统是 Windows x64 ,所以接下来以 Windows 为例,手把手教大家在 Windows 平台上安装 Tesseract OCR。1) 下载得到 tesseract-ocr-w64-setup-5.5.0.20241111.exe,双击运行,保持默认的 English 语言,点击“OK”:
2) 点击“Next”:
3) 点击“I Agree”:
4) 继续点击“Next”:
5) Tesseract OCR 默认是不识别中文的,这里我们需要手动勾选上,如下图所示。当然,大家可以把所有感兴趣的语言都勾选上。然后点击“Next”:
6) Tesseract OCR 默认是安装到 C 盘(系统盘),强烈建议手动安装到其它盘,比如下图中的 D 盘,然后点击 “Next”:
7) 点击 “Install”:
8) 等待安装完成,然后点击“Next”:
9) 出现下图所示的窗口,表示安装完成:
使用Tesseract OCR
普通用户经常用 Tesseract OCR 识别图片上的文字,记住几个常用的命令即可。1) 配置环境变量,步骤如下:
① 按照下图所示,打开电脑的设置窗口:
② 按照下图找到环境变量的设置入口:
③ 找到系统变量 Path,双击打开它:
④ 在 Path 系统变量中,添加 Tesseract OCR 的安装路径,比如笔者将它安装到了 D 盘下的 TesseractOCR 文件夹里:
2) 检测环境变量是否配置成功。按“Win+R”组合键,输入“cmd” 打开 CMD 命令行窗口,如下图所示,输入 tesseract -v 命令:
输出了 Tesseract OCR 的版本信息,表示安装成功了,接下来就可以使用 Tesseract OCR 识别图片了。
3) 接下来,我们以下面的图片为例,教大家编写 cmd 命令来操控 Tesseract OCR:
这张图的存储位置是:D:\demo.gif,在 CMD 命令行窗口中执行如下命令:
tesseract D:\demo.gif - -l eng+chi_sim
其中 eng 表示识别英文,chi_sim 表示是被简体中文。大家要自己修改图片的存储位置,其它不用改,执行结果为:可以看到,Tesseract OCR 识别出了图片中的所有字母和汉字。
通过执行如下命令,可以查看 Tesseract OCR 当前支持识别的语言:
tesseract --list-langs List of available languages in
我们还可以指定 Tesseract OCR 将识别出的内容存储到指定的文件里,比如执行如下指令:
tesseract D:\demo.gif D:\temp -l eng+chi_sim
执行完成后,D 盘下会新增一个名叫 temp 的 txt 文本文件,里面就有 Tesseract OCR 识别的全部内容:
关于 tesseract 更复杂的用法,大家可以执行 tesseract man 命令查看,或者前往 tesseract 说明页面,这里不再过多赘述。
Tesseract OCR手动安装语言包
如果安装过程中忘记或者遗漏了语言包,Tesseract OCR 官网提供了语言包:下载完成后会得到一个压缩包,里面的 xxx.traineddata 都是语言包,将它们放到 Tesseract-OCR\tessdata 目录下即可。下载地址:Tesseract OCR语言包
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: