HBase是什么,HBase数据库简介(新手必看)
HBase 是一个开源的、分布式的 NoSQL 数据库,可应用于列式存储,允许同一列不同行的数据类型不同,因此可以存储结构化和半结构化的数据。
例如,一些网站可以将自己的网页及相关日志数据存储到 HBase 中。
HBase 的实现源自 Google 公司在 2006 年 11 月发表的一篇关于 BigTable 的论文,由于 BigTable 的源码并未对外开放,因此 HBase 项目发起人根据此论文在 2007 年 2 月提出了 HBase 的原型,并介绍了相关概念及底层数据存储结构的设计。
由于 HBase 基于 Hadoop 的 HDFS,因此 HBase 的版本需要与 Hadoop 版本相匹配:
HBase 官网已发布的 HBase 版本如下图所示:
相关的历史版本可以参考 HBase 的历史归档列表。在实际的生产环境中,我们不建议使用最新版本的 HBase,因为它的性能一般不太稳定,而是建议从历史归档列表中选择性能稳定的 HBase 版本。
HBase 支持的 Hadoop 版本如下图所示:
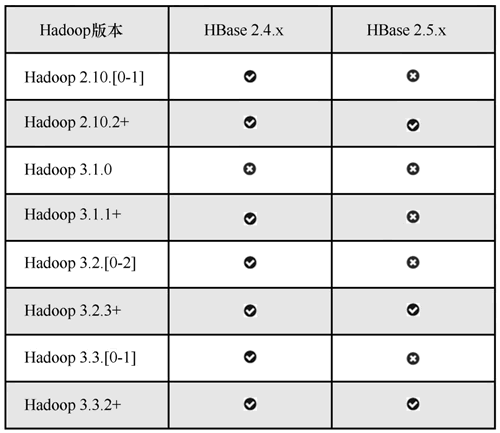
图 2 HBase支持的Hadoop版本
HBase 和 Hadoop 类似,也可以进行横向扩展,通过横向增加低配的个人计算机来增加集群的节点,实现扩容和提高计算能力。
HBase 具有以下显著的特性:
对于 HBase 数据表来说,单表存储数据达百亿行甚至更多的数据都没有性能问题,这是因为它采用了日志结构合并(Log Structured Merge,LSM)树结构来存储数据,会定期将小文件合并成大文件,从而减少对磁盘的访问量。
行存储和列存储如下图所示:
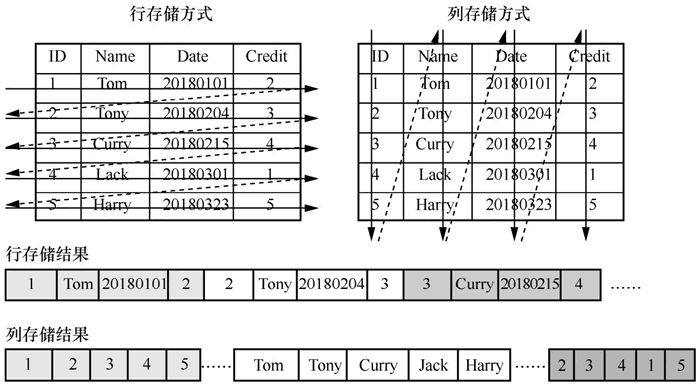
图 3 行存储与列存储
在进行插入、更新数据时,行式存储相对容易一些。在查询数据时,行存储需要读取所有的数据,而列存储只需读取相应的列,这可以有效降低系统输入/输出(Input/Output, I/O)压力。
HBase 通常可以设计成稀疏矩阵形式,这种方式其实更加接近现实中的场景。
HBase 数据表根据 Region 的大小进行分区,然后将 Region 分别存储于不同的服务器节点。当增加节点时,新节点启动 HBase 服务进程,集群会动态进行调整。这里的扩展是热扩展,即在 HBase 服务进程不停止的前提下,增加或者减少节点。
我们从下图中可以看出 HBase 在 Hadoop 生态系统中的位置。
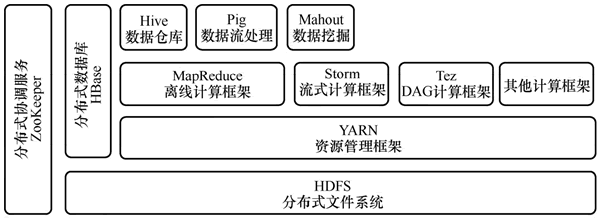
图 4 Hadoop生态系统
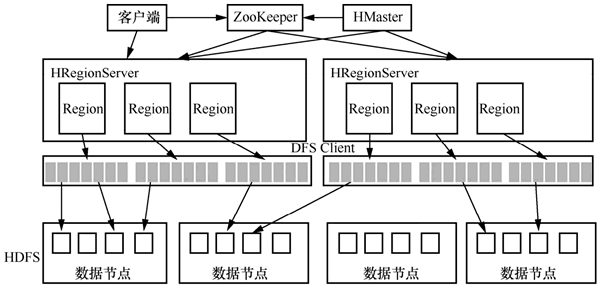
图 5 HBase系统架构
一般地,客户端与 HMaster 进行管理类操作的通信,在获取到 HRegionServer 节点的信息后,直接与 HRegionServer 进行数据读/写类操作的通信,获取并缓存 Region 数据块的位置信息,以加速后续的访问过程。
HBase 为开发者提供了多种客户端,比如 HBase Shell、Java API,以及通过 Thrift 服务来连接 Python 等其他语言接口。
ZooKeeper 在 HBase 中的协调任务如下:
① HMaster 节点选举。在 HBase 集群中,多个 HMaster 并存。HBase 通过竞争选举机制保证同一时刻只有一个主 HMaster 活跃,一旦这个节点故障,就从备用的 HMaster 中选出一个作为顶替,从而保证集群的高可靠性。
② 系统容错。在整个 HBase 集群启动时,每个 HRegionServer 会注册到 ZooKeeper 服务中,并创建一个状态节点。ZooKeeper 通过心跳机制来监控这些已注册的 HRegionServer 的状态,同时 HMaster 也会监控他们的状态。当某个 HRegionServer 故障后,ZooKeeper 会因接收不到它的心跳信息而将其状态节点删除,并通知 HMaster。此时, HMaster 会调度其他的节点,并开启容错机制。
③ Region 元数据管理。在 HBase 集群中,数据库的表信息、列族信息及列族的存储位置信息均属于元数据。Region 元数据存储在 Meta 表中,Meta 表位置信息以非临时 znode (ZooKeeper 中的节点)的方式注册到 ZooKeeper 中。客户端每次发起请求时,需先查询 Meta 表,然后获取 Region 位置信息。当 Region 发生变化时,可以通过 ZooKeeper 感知这一变化,从而保证客户端获取到正确的 Region 元数据。
① 管理用户对数据表所执行的增、删、改、查等操作。HMaster 提供的接口如下表所示:
② 管理 HRegionServer 的负载均衡,处理 HRegionServer 的故障转移。
③ 调整 Region 的分布,分配和移除 Region。
HMaster 通常运行在 HDFS 的 NameNode 节点上,通过 ZooKeeper 来避免单点故障的出现。
它包含的功能如下:
例如,一些网站可以将自己的网页及相关日志数据存储到 HBase 中。
HBase 的发展历史
HBase 最初是 Powerset 公司为处理自然语言搜索产生的海量数据而开展的项目,由查德·沃特斯(Chad Walters)和吉姆·凯勒曼(Jim Kellerman)发起,经过两年发展为 Apache 软件基金会的顶级项目。HBase 的实现源自 Google 公司在 2006 年 11 月发表的一篇关于 BigTable 的论文,由于 BigTable 的源码并未对外开放,因此 HBase 项目发起人根据此论文在 2007 年 2 月提出了 HBase 的原型,并介绍了相关概念及底层数据存储结构的设计。
由于 HBase 基于 Hadoop 的 HDFS,因此 HBase 的版本需要与 Hadoop 版本相匹配:
- 2007 年 10 月,第一版 HBase 随同 Hadoop 0.15.0 版本一起发布,此版本只实现了最基本的模块,其功能还不完善;
- 2008 年 1 月,Hadoop 升级为 Apache 软件基金会的顶级项目,HBase 作为 Hadoop 的子项目而存在。随后 HBase 的发展非常活跃,而 Hadoop 发展逐渐成熟,更新速度逐渐减缓;
- 2010 年 6 月,HBase 发布了 HBase 0.89.x 版本后不再与 Hadoop 关联发布。2010 年,HBase 也成为 Apache 软件基金会的顶级项目,并在 2015 年 2 月发布了较为成熟的版本 HBase 1.0.0;
- 2017 年,HBase 2.0.0-Alpha-1 发布,这是一个里程碑式的版本,对 PostgreSQL 协议的支持、S3 备份、缓存性能的提高等使 HBase 变得更加健壮,适应性强。
HBase 官网已发布的 HBase 版本如下图所示:
相关的历史版本可以参考 HBase 的历史归档列表。在实际的生产环境中,我们不建议使用最新版本的 HBase,因为它的性能一般不太稳定,而是建议从历史归档列表中选择性能稳定的 HBase 版本。
HBase 支持的 Hadoop 版本如下图所示:
图 2 HBase支持的Hadoop版本
HBase的特性
HBase 是分布式、可扩展、列式存储、适用于稀疏数据存储的非关系数据库,由行键、列键和时间戳共同索引的多维有序映射数据库,既可以存储结构化数据,也可以存储半结构化数据。它在 Hadoop 生态系统的 HDFS 的基础之上提供海量数据的分布式存储,在 Hadoop 生态系统的 MapReduce 的基础上提供分布式并行计算。HBase 和 Hadoop 类似,也可以进行横向扩展,通过横向增加低配的个人计算机来增加集群的节点,实现扩容和提高计算能力。
HBase 具有以下显著的特性:
1) 容量巨大
HBase 的单表存储量可以达到数十亿行、数百万列。而对于关系数据库来说,当单表存储数据规模达到亿级别时,它的读/写性能会呈指数级下降。对于 HBase 数据表来说,单表存储数据达百亿行甚至更多的数据都没有性能问题,这是因为它采用了日志结构合并(Log Structured Merge,LSM)树结构来存储数据,会定期将小文件合并成大文件,从而减少对磁盘的访问量。
2) 列式存储
关系数据库是面向行存储的,同一行数据存储在同一块内存中。而 HBase 是面向列存储的,同一列的数据存储在同一块内存中,可以针对某一列数据进行独立检索。行存储和列存储如下图所示:
图 3 行存储与列存储
在进行插入、更新数据时,行式存储相对容易一些。在查询数据时,行存储需要读取所有的数据,而列存储只需读取相应的列,这可以有效降低系统输入/输出(Input/Output, I/O)压力。
3) 稀疏性
在传统的关系数据库中,每一个字段类型通常是预先定义好的,即使对应的值为缺失值,也需要占用内存空间。而 HBase 面向列存储且其字段类型都是字符串,当字段为缺失值时并不占用内存空间,因而解决了数据的稀疏问题,在很大程度上节省了内存空间。HBase 通常可以设计成稀疏矩阵形式,这种方式其实更加接近现实中的场景。
4) 扩展性强
HBase 基于 Hadoop 的 HDFS,因而继承了 HDFS 可扩展的特性,支持分布式表,可以进行横向扩展,通过将服务器节点增加到现有的集群中来实现扩容。HBase 数据表根据 Region 的大小进行分区,然后将 Region 分别存储于不同的服务器节点。当增加节点时,新节点启动 HBase 服务进程,集群会动态进行调整。这里的扩展是热扩展,即在 HBase 服务进程不停止的前提下,增加或者减少节点。
5) 高可靠性
HDFS 的多副本机制可以让 HBase 在出现故障时自动恢复,同时 HBase 内部也提供了预写日志(Write-Ahead Logging,WAL)和副本机制:- 预写日志用于记录 HBase 服务器处理数据所执行插入、删除等操作内容,确保 HBase 在写数据时不会因集群异常而导致写入数据的丢失。
- 副本机制基于日志操作来同步数据。当集群中的某个节点异常时,协调服务组件(ZooKeeper)通知集群主节点,将故障节点的 HLog 日志信息分发给各个从节点进行数据恢复。
我们从下图中可以看出 HBase 在 Hadoop 生态系统中的位置。
图 4 Hadoop生态系统
HBase系统的组件与功能
HBase 系统架构如下图所示,其中包括客户端、ZooKeeper 服务器、HMaster 主服务器、HRegionServer() 数据节点服务器等。图 5 HBase系统架构
1) 客户端
客户端是整个 HBase 系统的入口,用于操作 HBase。一般地,客户端与 HMaster 进行管理类操作的通信,在获取到 HRegionServer 节点的信息后,直接与 HRegionServer 进行数据读/写类操作的通信,获取并缓存 Region 数据块的位置信息,以加速后续的访问过程。
HBase 为开发者提供了多种客户端,比如 HBase Shell、Java API,以及通过 Thrift 服务来连接 Python 等其他语言接口。
2) ZooKeeper
ZooKeeper 是一种分布式应用程序的协调服务,主要用于解决分布式应用中经常出现的数据管理问题,如数据的发布/订阅、分布式协调/通知、集群管理、HMaster 选举、分布式锁等。ZooKeeper 在 HBase 中的协调任务如下:
① HMaster 节点选举。在 HBase 集群中,多个 HMaster 并存。HBase 通过竞争选举机制保证同一时刻只有一个主 HMaster 活跃,一旦这个节点故障,就从备用的 HMaster 中选出一个作为顶替,从而保证集群的高可靠性。
② 系统容错。在整个 HBase 集群启动时,每个 HRegionServer 会注册到 ZooKeeper 服务中,并创建一个状态节点。ZooKeeper 通过心跳机制来监控这些已注册的 HRegionServer 的状态,同时 HMaster 也会监控他们的状态。当某个 HRegionServer 故障后,ZooKeeper 会因接收不到它的心跳信息而将其状态节点删除,并通知 HMaster。此时, HMaster 会调度其他的节点,并开启容错机制。
③ Region 元数据管理。在 HBase 集群中,数据库的表信息、列族信息及列族的存储位置信息均属于元数据。Region 元数据存储在 Meta 表中,Meta 表位置信息以非临时 znode (ZooKeeper 中的节点)的方式注册到 ZooKeeper 中。客户端每次发起请求时,需先查询 Meta 表,然后获取 Region 位置信息。当 Region 发生变化时,可以通过 ZooKeeper 感知这一变化,从而保证客户端获取到正确的 Region 元数据。
3) HMaster
HBase 集群的主服务器 HMaster 负责监控所有的 HRegionServer,同时负责表和 Region 的管理工作,具体如下:① 管理用户对数据表所执行的增、删、改、查等操作。HMaster 提供的接口如下表所示:
| 接口 | 功能 |
|---|---|
| HBase 数据表 | 添加表、删除表、修改表 |
| HBase 列族 | 添加列族、删除列族、修改列族 |
| HBase 数据表 Region | 移除 Region、分配和合并 Region |
② 管理 HRegionServer 的负载均衡,处理 HRegionServer 的故障转移。
③ 调整 Region 的分布,分配和移除 Region。
HMaster 通常运行在 HDFS 的 NameNode 节点上,通过 ZooKeeper 来避免单点故障的出现。
4) HRegionServer
HRegionServer 一般运行在 HDFS 的 DataNode 节点上,主要负责响应客户端的读/写数据请求,最终实现在 HDFS 中读/写数据。每个 HRegionServer 可存储多个 Region。它包含的功能如下:
- ① 处理分配的 Region,以及拆分与合并 Region;
- ② 处理客户端的读/写请求;
- ③ 刷新缓存,并把缓存写入到 HDFS 中;
- ④ 执行数据的压缩算法。
HBase的应用场景
下面介绍一些常见的适合使用 HBase 的场景:- 场景1:数据模式是动态可变的,存储结构化数据和半结构化数据;
- 场景2:数据库中的列包含很多空值的稀疏数据;
- 场景3:需要很高的吞吐量,存在写入海量数据的需求;
- 场景4:需要数据存储具有高可靠性、高可扩展性,整个系统可动态扩展;
- 场景5:如搜索引擎存储海量网页、监控参数、用户交互数据等应用。