C++线程池的具体实现(带源码和解析)
线程池是一种管理线程的机制,在程序运行期间维护一组预先创建的线程,用于执行后台任务,避免重复地创建和销毁线程以节省系统的调度时间。线程池可以提高程序的性能和资源利用率,同时也减少了线程创建和销毁的开销。
线程池通常包含任务队列、线程池管理、工作线程:
使用线程池的主要好处是可以控制线程数量,方便在并发和资源调配上找出一个比较合理的平衡。线程的创建和销毁是一项昂贵的操作,线程池可以重用已创建的线程,减少这些开销,避免系统资源过度消耗和竞争,能够提供更好的系统资源管理。线程池可以根据系统资源的情况来动态地调整线程的数量,从而更好地利用系统资源。
在 C++11 标准库中,提供了主要的线程操作模块,但是并没有实现线程池。线程池作为一种高效的线程处理手段在实际开发中会经常用到。本节实现了一个简易的线程池,成员变量定义的代码如下:
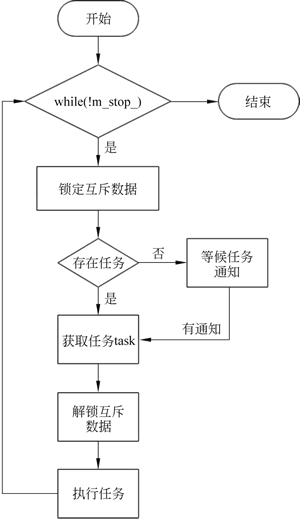
图 1 线程池调度流程图
run_task__() 函数用于在线程池中循环执行任务,是线程池处理调度的核心代码。它的主要作用是不断地从任务队列中获取任务并执行它们,实际上会根据线程池的池容量启动若干个 run_task__() 线程。当线程池被标记为停止并且任务队列为空时,该函数会退出,具体步骤见图 1,run_task__() 函数的代码如下:
add() 用于向线程池中添加任务,对需要执行的任务进行排队。它接收一个函数对象 f 和任意数量的参数 args,并返回一个 std::future 对象,后期用于获取任务的返回值。模板参数 Func_t 是函数类型,Args... 是 Func_t 参数表类型。
在 add() 函数的实现中返回的返回值使用类型推导的方式实现,所以返回值类型使用了 auto,通过 -> 操作对返回值进行推导。在这里是 std::future<返回值类型>,无论函数的实际返回值是什么都返回一个 std::future 类型。函数的实际返回值类型则通过 std::result_of<> 元函数获取 std::result_of<F(Args...)>::type,代码如下:
std::packaged_task() 用于包装任何可调用目标(如函数、lambda 表达式、bind 表达式或函数对象),以便它可以被异步调用,其主要功能是将可调用对象的执行结果传递给一个 std::future 对象,这样可以在另一个线程中异步获取该结果。要返回的 std::future 对象通过 std::packaged_task 的成员函数 get_future() 获取。
最后任务的返回值通过 std::future 读取,代码如下:
start() 函数的功能是启动线程池操作,函数参数 start 的默认值为 true,在参数值为 true 的情况下启动线程池,在参数值为 false 的情况下停止线程池。for 循环根据构造函数配置的线程池数量启动对应数量的线程,线程执行的任务就是 run_task__() 函数。
当需要结束线程池时首先清理掉还没有执行的任务列表,然后根据操作系统结束正在运行的线程,代码如下:
在这个模块完成了基础的线程池功能,但是并没有考虑任务数量的上限,这可能会造成内存负载过高,在使用时需要注意这点,读者可以根据自己的需要调整代码,以便添加任务上限的约束,例如当任务数量达到上限时拒绝添加任务。如果要进行这样的修改,则可以将判断的内容添加到 add() 函数的实现中。
下面是一个简单的使用线程池的示例程序,演示如何使用 threadPool 模块,代码如下:
线程池通常包含任务队列、线程池管理、工作线程:
- 任务队列用于存储待执行的任务。任务可以是任意的代码块或函数;
- 线程池管理负责创建和销毁线程,以及监控任务队列的状态,并处理好多个线程的执行顺序和资源的竞争;
- 工作线程用于获取队列中的任务并执行任务。
使用线程池的主要好处是可以控制线程数量,方便在并发和资源调配上找出一个比较合理的平衡。线程的创建和销毁是一项昂贵的操作,线程池可以重用已创建的线程,减少这些开销,避免系统资源过度消耗和竞争,能够提供更好的系统资源管理。线程池可以根据系统资源的情况来动态地调整线程的数量,从而更好地利用系统资源。
在 C++11 标准库中,提供了主要的线程操作模块,但是并没有实现线程池。线程池作为一种高效的线程处理手段在实际开发中会经常用到。本节实现了一个简易的线程池,成员变量定义的代码如下:
//threadPool.h
class threadPool
{
private:
std::vector<std::thread > m_works__; //线程池运行中的线程组
std::queue<std::function<void() >> m_tasks__; //任务队列
std::mutex m_queue_mutex__; //互斥锁
std::condition_variable m_condition__; //调度控制的条件变量
std::atomic< bool > m_stop__; //是否已经停止
std::atomic< int > m_count__; //线程池容量
private:
线程调度模块的处理流程如下图所示:图 1 线程池调度流程图
- 首先检查线程池是否在运行,如果在运行,则锁定运行数据,检查是否存在任务;
- 如果不存在任务,则等待任务。如果存在任务,则从任务队列中读取任务调度以执行任务;
- 当不存在任务时使用条件变量等候通知,新增任务的新增函数会发出通知以调度程序执行调度操作。
run_task__() 函数用于在线程池中循环执行任务,是线程池处理调度的核心代码。它的主要作用是不断地从任务队列中获取任务并执行它们,实际上会根据线程池的池容量启动若干个 run_task__() 线程。当线程池被标记为停止并且任务队列为空时,该函数会退出,具体步骤见图 1,run_task__() 函数的代码如下:
// threadPool.h
void run_task__() {
while(!m_stop__.load()) {
std::function<void()> task; // 实际要执行的任务
{
std::unique_lock<std::mutex> lock(m_queue_mutex__);
// 等候队列任务就绪
m_condition__.wait(lock, [&] {
return m_stop__ || !m_tasks__.empty();
});
// 结束执行
if (m_stop__ && m_tasks__.empty()) { return; }
// 获取任务
task = std::move(m_tasks__.front());
m_tasks__.pop();
}
// 执行任务
task();
}
}
public:
// 参数 numThreads 是线程池的线程容量
threadPool(size_t numThreads) : m_stop__(true), m_count__(numThreads) {}
~threadPool() { stop(); }
add() 用于向线程池中添加任务,对需要执行的任务进行排队。它接收一个函数对象 f 和任意数量的参数 args,并返回一个 std::future 对象,后期用于获取任务的返回值。模板参数 Func_t 是函数类型,Args... 是 Func_t 参数表类型。
在 add() 函数的实现中返回的返回值使用类型推导的方式实现,所以返回值类型使用了 auto,通过 -> 操作对返回值进行推导。在这里是 std::future<返回值类型>,无论函数的实际返回值是什么都返回一个 std::future 类型。函数的实际返回值类型则通过 std::result_of<> 元函数获取 std::result_of<F(Args...)>::type,代码如下:
//threadPool.h
template<class Func_t, class...Args >
auto add(Func_t&&f, Args&&...args) -> std::future<typename std::result_of<F(Args...) >::type >
{
using return_type = typename std::result_of<F(Args...) >::type;
std::packaged_task() 用于包装任何可调用目标(如函数、lambda 表达式、bind 表达式或函数对象),以便它可以被异步调用,其主要功能是将可调用对象的执行结果传递给一个 std::future 对象,这样可以在另一个线程中异步获取该结果。要返回的 std::future 对象通过 std::packaged_task 的成员函数 get_future() 获取。
最后任务的返回值通过 std::future 读取,代码如下:
//threadPool.h
auto task =std::make_shared<std::packaged_task<return_type() >>( std::bind(std::forward<F >(f),std::forward<Args >(args)...));
std::future<return_type > res = task->get_future();
{
std::unique_lock<std::mutex > lock(m_queue_mutex__);
m_tasks__.emplace([task](){(* task)();});
}
m_condition__.notify_one();
return res;
}
start() 函数的功能是启动线程池操作,函数参数 start 的默认值为 true,在参数值为 true 的情况下启动线程池,在参数值为 false 的情况下停止线程池。for 循环根据构造函数配置的线程池数量启动对应数量的线程,线程执行的任务就是 run_task__() 函数。
当需要结束线程池时首先清理掉还没有执行的任务列表,然后根据操作系统结束正在运行的线程,代码如下:
//container/variant.h
void start(bool sw = true) {
if(sw) {
if(!m_stop__.load()) return; // 线程池正在运行
m_stop__ = !sw;
// 根据线程池的线程容量启动 m_count__ 个线程
for (int i = 0; i < m_count__.load(); ++i) {
m_works__.emplace_back(
std::bind(&threadPool::run_task__, this));
}
m_condition__.notify_all();
} else {
clearNotRunning();
m_stop__ = !sw;
m_condition__.notify_all();
// 根据平台情况停止正在运行的线程任务
for (std::thread& worker : m_works__) {
#if defined(__POSIX__) || defined(__LINUX__)
pthread_t id = worker.native_handle();
pthread_cancel(id);
#elif defined(WIN32)
HANDLE id = worker.native_handle();
TerminateThread(id, 0);
#endif
}
}
}
inline void stop() { start(false); }
使用 std::queue 针对任务进行排队处理,使用 std::future 处理异步返回值,并利用条件变量进行任务调度和数据的同步处理,可以有效地控制系统负载和任务平衡。在实际使用时可以根据计算机的硬件特点选择线程数量,能够保证在每个核上运行一个任务以达到对 CPU 算力的最好利用。在这个模块完成了基础的线程池功能,但是并没有考虑任务数量的上限,这可能会造成内存负载过高,在使用时需要注意这点,读者可以根据自己的需要调整代码,以便添加任务上限的约束,例如当任务数量达到上限时拒绝添加任务。如果要进行这样的修改,则可以将判断的内容添加到 add() 函数的实现中。
下面是一个简单的使用线程池的示例程序,演示如何使用 threadPool 模块,代码如下:
//threadPool.cpp
class a
{
public:
int taskFunction(int id) {
std::cout << "Task " << id << " started" << std::endl;
// 模拟一些工作任务,使用 sleep_for 函数等候一段时间
std::this_thread::sleep_for(std::chrono::seconds(1));
std::cout << "Task " << id << " finished" << std::endl;
return id * 2;
}
};
int main()
{
a a1;
threadPool pool(4); // 创建一个线程池,有 4 个工作线程
std::vector<std::future<int> > rst(8); // 结果数组
// 将任务提交到线程池
for (int i = 0; i < 8; ++i) {
rst[i] = pool.add(
std::bind(&a::taskFunction, &a1, std::placeholders::_1), i);
}
// 启动线程池
pool.start(true);
// 等待所有任务完成
std::this_thread::sleep_for(std::chrono::seconds(5));
// 输出结果
for(int i = 0; i < 8; i++) {
std::cout << "thread " << i << " result: " << rst[i].get() << std::endl;
}
return 0;
}