C++自定义迭代器(非常详细,附带实例)
迭代器是 C++ 标准库中的一个核心概念,用于访问和遍历容器(如数组、列表和向量)中的元素。这些容器中的元素通常组成一个“序列”,迭代器允许按顺序访问序列中的每个元素。
虽然标准库提供了多种迭代器,但在某些情况下,为特定的数据结构实现自定义迭代器是非常有用的。
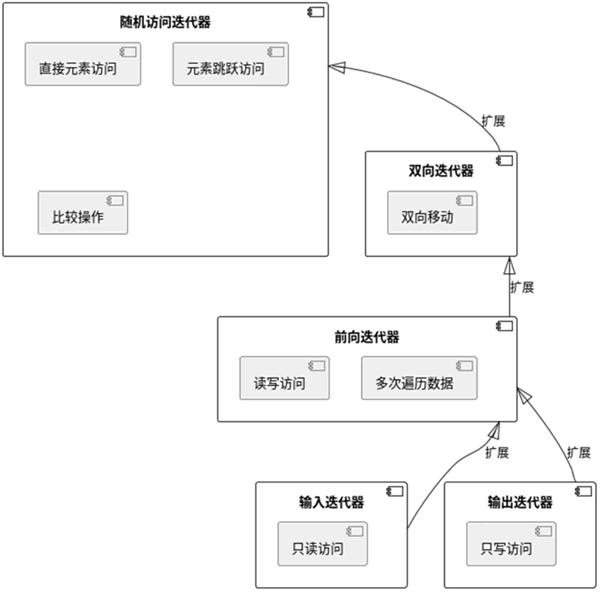
图 1 迭代器分类图
在了解了迭代器种类的基本知识后,我们可以进一步思考:如何在实际编程中判断并应用不同类型的迭代器呢?这不仅有助于提高代码效率,还能在设计泛型算法时做出更精确的操作决策。
在 C++ 标准库中,std::iterator_traits 是一个模板结构,它为迭代器类型提供了统一的方式来查询其特性。迭代器的特性包括:
这些特性对于编写通用和高效的模板代码非常关键。例如,当开发一个通用算法时,通过 std::iterator_traits 可以不需要知道迭代器的具体类型,就能获取关于其指向的元素类型的信息,从而使算法能够适用于不同类型的迭代器。
此外,迭代器类别的信息可以帮助算法决定使用哪种操作,比如只有随机访问迭代器才能进行快速跳跃访问和算术运算。
【实例】使用 std::iterator_traits 来编写一个泛型函数,该函数根据迭代器的类别执行不同的操作:
此示例清晰地展示了利用 std::iterator_traits 编写通用且高效的代码的方法。通过识别迭代器的类型,我们可以选择最适合的操作策略,特别是在处理支持随机访问的容器时,这种方法能显著提高性能。
std::iterator_traits 的应用不仅增强了代码的灵活性,而且优化了数据处理效率,尤其在面对大数据量时。在实现自定义迭代器的过程中,通过特化 std::iterator_traits,可以确保这些迭代器与期望使用标准迭代器特性的模板代码兼容。这一步骤不仅提升了自定义迭代器的可用性,而且确保了与现有标准库算法的无缝集成。
【实例】假设有一个简单的容器 std::vector<int>,使用迭代器遍历这个容器中的所有元素。
实现一个自定义迭代器通常涉及创建一个类,该类实现了迭代器应有的一系列操作符(或称运算符),如递增(++)、解引用(*)、比较(== 和 !=)等。
【实例】实现一个简单的数组迭代器。
例如:
切换不同的迭代器是一种高级技巧,它可以极大增强程序的灵活性和效率,特别是在处理复杂或不同特性的数据结构时。
切换迭代器主要涉及以下几个关键点:
例如,如果一个容器支持随机访问迭代器,那么在执行需要频繁随机访问的操作时使用随机访问迭代器将极大提高效率;如果容器仅支持前向迭代器,则可能需要使用不同的策略或优化技术。
【实例】假设有一个数据处理库,需要根据数据的大小和类型选择最适合的迭代器,可以使用策略模式和模板特化这样设计:
总之,迭代器的灵活使用和切换是提高 C++ 程序设计效率和性能的关键策略之一,特别是在处理复杂或多样化数据结构的场景中,通过合理地应用这些技术,可以极大地提升程序的灵活性和响应能力。
虽然标准库提供了多种迭代器,但在某些情况下,为特定的数据结构实现自定义迭代器是非常有用的。
C++迭代器的基本概念
在 C++ 中,迭代器是用来访问和遍历容器(如数组、列表和向量)元素的对象。它们模拟了指针的功能,但提供了更高级的操作,允许以统一的方式对各种数据结构进行操作。迭代器是现代 C++ 编程中不可或缺的工具,特别是在处理集合数据时。1) 迭代器的分类
迭代器可以根据它们支持的操作类型分为 5 种不同的类别,如下图所示:图 1 迭代器分类图
- 输入迭代器:允许读取容器中的数据,但不允许修改数据。它们只能单向移动(只能递增)。
- 输出迭代器:只能用于在容器中写入数据,不能读取或修改数据。它们同样只能单向移动。
- 前向迭代器:比输入和输出迭代器的功能更强,允许读写操作,并可以多次遍历容器中的数据。前向迭代器同样只支持单向移动。
- 双向迭代器:在前向迭代器的基础上增加了向后移动的能力,允许双向操作容器中的数据。
- 随机访问迭代器:提供了最强大的功能,支持全面的数据访问,包括直接访问任何元素、元素之间的跳跃访问(例如,通过加法和减法),以及比较操作。这种迭代器的功能类似于原始指针,广泛用于数组和向量中。
在了解了迭代器种类的基本知识后,我们可以进一步思考:如何在实际编程中判断并应用不同类型的迭代器呢?这不仅有助于提高代码效率,还能在设计泛型算法时做出更精确的操作决策。
在 C++ 标准库中,std::iterator_traits 是一个模板结构,它为迭代器类型提供了统一的方式来查询其特性。迭代器的特性包括:
- iterator_category:迭代器的类别,如输入迭代器、输出迭代器、前向迭代器、双向迭代器或随机访问迭代器。
- value_type:迭代器指向的元素类型。
- difference_type:用于表示两个迭代器之间的距离的类型。
- pointer:指向迭代器元素类型的指针类型。
- reference:迭代器元素类型的引用类型。
这些特性对于编写通用和高效的模板代码非常关键。例如,当开发一个通用算法时,通过 std::iterator_traits 可以不需要知道迭代器的具体类型,就能获取关于其指向的元素类型的信息,从而使算法能够适用于不同类型的迭代器。
此外,迭代器类别的信息可以帮助算法决定使用哪种操作,比如只有随机访问迭代器才能进行快速跳跃访问和算术运算。
【实例】使用 std::iterator_traits 来编写一个泛型函数,该函数根据迭代器的类别执行不同的操作:
#include <iostream>
#include <vector>
#include <iterator>
#include <list>
// 泛型函数,根据迭代器的类型使用不同的逻辑
template <typename Iterator>
void process_elements(Iterator begin, Iterator end) {
using Category = typename std::iterator_traits<Iterator>::iterator_category;
if constexpr (std::is_same<Category, std::random_access_iterator_tag>::value) {
// 如果是随机访问迭代器,可以使用加法快速跳跃
std::cout << "随机访问迭代器,支持快速跳跃访问:" << std::endl;
size_t distance = end - begin;
for (size_t i = 0; i < distance; i += 2) {
std::cout << begin[i] << " "; // 直接跳跃访问
}
} else {
// 对于其他类型的迭代器,使用标准的递增
std::cout << "标准迭代器,逐元素访问:" << std::endl;
while (begin != end) {
std::cout << *begin << " ";
++begin;
}
}
std::cout << std::endl;
}
int main() {
std::vector<int> v{1, 2, 3, 4, 5, 6, 7, 8, 9};
std::list<int> l{10, 20, 30, 40, 50, 60, 70, 80, 90};
std::cout << "使用vector:" << std::endl;
process_elements(v.begin(), v.end());
std::cout << "使用list:" << std::endl;
process_elements(l.begin(), l.end());
return 0;
}
在这个示例中:
- 定义了一个泛型函数 process_elements,它接收任意类型的迭代器。
- 使用了 std::iterator_traits 来检查迭代器的类别,并据此决定使用的逻辑。
- 对于随机访问迭代器(如 std::vector 的迭代器),使用了索引来实现快速跳跃访问。
- 对于非随机访问迭代器(如 std::list 的迭代器),使用了标准的逐个元素访问。
此示例清晰地展示了利用 std::iterator_traits 编写通用且高效的代码的方法。通过识别迭代器的类型,我们可以选择最适合的操作策略,特别是在处理支持随机访问的容器时,这种方法能显著提高性能。
std::iterator_traits 的应用不仅增强了代码的灵活性,而且优化了数据处理效率,尤其在面对大数据量时。在实现自定义迭代器的过程中,通过特化 std::iterator_traits,可以确保这些迭代器与期望使用标准迭代器特性的模板代码兼容。这一步骤不仅提升了自定义迭代器的可用性,而且确保了与现有标准库算法的无缝集成。
2) 迭代器的工作原理
迭代器通过重载指针运算符(如解引用 * 和成员访问 ->)以及增加和减少操作符(如 ++ 和 --),模拟指针的行为。例如,随机访问迭代器还会重载加法和减法运算符,使得可以实现类似于指针的算术运算。【实例】假设有一个简单的容器 std::vector<int>,使用迭代器遍历这个容器中的所有元素。
#include <iostream>
#include <vector>
int main() {
std::vector<int> vec = {1, 2, 3, 4, 5};
std::vector<int>::iterator it;
std::cout << "使用迭代器遍历vector:" << std::endl;
for (it = vec.begin(); it != vec.end(); ++it) {
std::cout << *it << " ";
}
std::cout << std::endl;
return 0;
}
在这个例子中,begin() 函数返回一个指向容器中的第一个元素的迭代器,而 end() 返回一个指向容器中的最后一个元素之后的位置的迭代器。通过不断增加迭代器 it(++it),我们可以遍历整个容器。
C++实现自定义迭代器
虽然标准库为常用的容器提供了迭代器,但在开发自定义数据结构(如链表或树结构)时,标准迭代器可能无法满足特定需求。此时,定义符合该数据结构特性的迭代器,能够提高代码的封装性和可复用性,同时使得数据结构可以无缝集成到 C++ 标准库算法中,从而保持代码的清晰和一致。实现一个自定义迭代器通常涉及创建一个类,该类实现了迭代器应有的一系列操作符(或称运算符),如递增(++)、解引用(*)、比较(== 和 !=)等。
【实例】实现一个简单的数组迭代器。
template<typename T>
class ArrayIterator {
public:
// 定义类型别名
using value_type = T;
using pointer = T*;
using reference = T&;
private:
pointer ptr; // 指向数组元素的指针
public:
ArrayIterator(pointer p) : ptr(p) {}
// 前缀递增
ArrayIterator& operator++() {
ptr++;
return *this;
}
// 后缀递增
ArrayIterator operator++(int) {
ArrayIterator temp = *this;
++(*this);
return temp;
}
// 解引用
reference operator*() const {
return *ptr;
}
// 指针访问
pointer operator->() {
return ptr;
}
// 等于
bool operator==(const ArrayIterator& other) const {
return ptr == other.ptr;
}
// 不等于
bool operator!=(const ArrayIterator& other) const {
return ptr != other.ptr;
}
};
C++使用自定义迭代器
一旦定义了迭代器,就可以将它用于标准算法中或用来构造支持迭代的自定义容器。例如:
int main() {
int arr[] = {1, 2, 3, 4, 5};
ArrayIterator<int> begin(arr);
ArrayIterator<int> end(arr + sizeof(arr)/sizeof(arr[0]));
for (ArrayIterator<int> it = begin; it != end; ++it) {
std::cout << *it << " ";
}
std::cout << std::endl;
}
通过自定义迭代器,开发者可以为特定的数据结构提供自然和高效的遍历方法。这不仅增强了代码的可读性,还提高了与 C++ 标准库其他部分的兼容性。C++切换不同的迭代器
在讨论了自定义迭代器的创建和使用之后,一个进阶的话题是如何在不同迭代器之间进行切换,以应对不同的编程需求和场景。切换不同的迭代器是一种高级技巧,它可以极大增强程序的灵活性和效率,特别是在处理复杂或不同特性的数据结构时。
切换迭代器主要涉及以下几个关键点:
1) 动态选择迭代器
在某些情况下,根据容器的特定属性或数据的特定状态选择最适合的迭代器类型是非常有用的。例如,如果一个容器支持随机访问迭代器,那么在执行需要频繁随机访问的操作时使用随机访问迭代器将极大提高效率;如果容器仅支持前向迭代器,则可能需要使用不同的策略或优化技术。
2) 使用策略模式实现迭代器切换
策略模式是一种设计模式,允许在运行时选择算法的行为。通过将迭代器封装在具有公共接口的类中,可以根据不同的情况动态切换不同的迭代器。这种方式非常适合需要处理多种数据结构,且每种结构需要不同遍历策略的场景。3) 模板特化和条件编译
在编译时根据不同的条件选择不同的迭代器实现。使用预处理指令或模板特化可以在编译时决定使用哪种类型的迭代器,这种方法常用于依赖特定硬件或编译环境的程序。4) 利用using别名简化迭代器切换
在 C++ 中,using 关键字可以用来定义类型别名,这使得更换迭代器类型变得非常简单。通过在类或模板的顶部定义迭代器别名,可以轻松地在不同类型的迭代器间切换,而无须大量修改代码。【实例】假设有一个数据处理库,需要根据数据的大小和类型选择最适合的迭代器,可以使用策略模式和模板特化这样设计:
// 抽象基类,定义迭代器的接口
template<typename T>
class AbstractIterator {
public:
virtual T& operator*() = 0;
virtual AbstractIterator<T>& operator++() = 0;
virtual bool operator!=(const AbstractIterator<T>& other) = 0;
virtual ~AbstractIterator() {}
};
// 具体迭代器类,实现随机访问迭代器
template<typename T>
class RandomAccessIterator : public AbstractIterator<T> {
private:
T* ptr;
public:
RandomAccessIterator(T* p) : ptr(p) {}
T& operator*() override { return *ptr; }
AbstractIterator<T>& operator++() override { ++ptr; return *this; }
bool operator!=(const AbstractIterator<T>& other) const override {
return ptr != dynamic_cast<const RandomAccessIterator<T>&>(other).ptr;
}
};
// 迭代器选择器,运行时决定使用哪种迭代器
template<typename T, typename Container>
AbstractIterator<T>* createIterator(Container& container, bool isRandomAccess) {
if (isRandomAccess) {
return new RandomAccessIterator<T>(container.data());
} else {
// 返回其他类型的迭代器
}
}
在这个设计中,根据容器是否支持随机访问,在运行时选择相应的迭代器实现。这种设计允许在不同的迭代器之间进行切换,以适应不同的数据结构和需求,同时保持代码的一致性和可维护性。总之,迭代器的灵活使用和切换是提高 C++ 程序设计效率和性能的关键策略之一,特别是在处理复杂或多样化数据结构的场景中,通过合理地应用这些技术,可以极大地提升程序的灵活性和响应能力。
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: