管道过滤器架构模式详解(附带C++实例)
管道过滤器架构主要是为了处理数据流,特别是需要对其进行一系列的处理和转换操作的情况。
这种架构的核心思想强调了以下几个关键点:
实现这种架构的基本步骤如下:
【实例】首先,定义一个过滤器接口:
然后,创建一些具体的过滤器:
接着,定义一个管道来管理和连接这些过滤器:
最后,使用这个架构处理数据:
本例的管道与过滤器架构如下图所示:
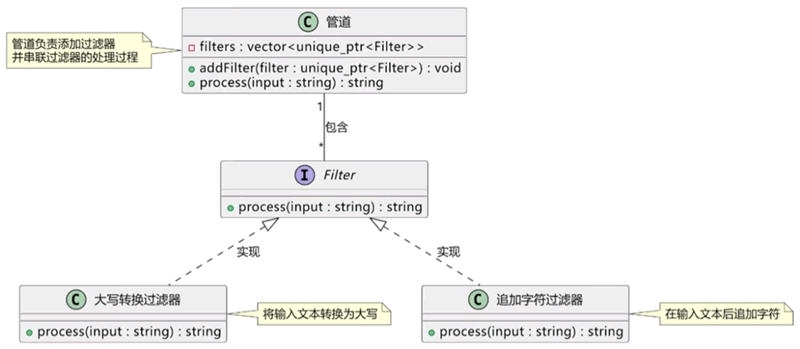
图 1 管道与过滤器架构图
展示了如何通过管道模式将字符串先转换为大写,然后在其后追加字符串。读者可以根据需要添加更多的过滤器或修改现有过滤器来处理不同类型的数据。
在 C++ 编程和开发中,管道与过滤器架构主要适用于以下几种类型的需求:
例如,在图像处理软件中,原始图像数据可能需要经过一系列的处理过程,如缩放、滤镜应用、边缘检测等,这些都可以通过管道与过滤器架构来实现,每个处理步骤作为一个独立的过滤器。这样的设计不仅使得每个步骤的实现清晰,也方便以后根据需求添加或修改处理步骤。
总之,管道与过滤器架构提供了一种强大的方法来处理序列化的数据流和复杂的数据转换任务,其模块化和可扩展的特性使得它非常适合处理需要清晰处理逻辑和高并行性的应用场景。这种架构的实践不仅凸显了在 C++ 中处理数据流的效率,还展示了良好架构设计在软件开发中的重要性。
管道过滤器架构的核心思想
管道过滤器架构的核心思想是将数据处理过程分解为一系列独立的处理步骤(即过滤器),并通过管道将这些步骤连接起来。每个过滤器都有明确定义的输入和输出,它负责接收输入数据,对其进行某种处理或转换,然后输出结果。管道则负责数据的传输,将数据从一个过滤器传送到下一个过滤器。这种架构的核心思想强调了以下几个关键点:
- 独立性:每个过滤器都是独立的处理单元,只关注自己的处理任务,具有高内聚性,不与其他过滤器直接交互。这种独立性使得系统更易于模块化和维护;
- 数据流转:数据通过管道在过滤器之间流动,每个过滤器对数据进行特定的处理,并将处理后的数据传递给下一个过滤器。这种流式处理方式使得数据处理流程清晰、灵活且可扩展。
管道过滤器架构C++实现
在 C++ 中,实现管道与过滤器架构通常涉及定义一系列的处理单元(过滤器),每个处理单元对数据进行处理后将结果传递给下一个处理单元。这种架构模式非常适合于数据流处理和信号处理等应用。实现这种架构的基本步骤如下:
- 定义过滤器接口:所有的过滤器都应该实现一个共同的接口,这样它们可以在管道中互换使用;
- 创建具体的过滤器类:实现具体的处理逻辑;
- 构建管道:将不同的过滤器连接起来,形成数据处理的流程;
- 处理数据:通过管道发送数据,并让它流经各个过滤器。
【实例】首先,定义一个过滤器接口:
class Filter {
public:
virtual ~Filter() {}
virtual std::string process(const std::string& input) = 0;
};
然后,创建一些具体的过滤器:
class CapitalizeFilter : public Filter {
public:
std::string process(const std::string& input) override {
std::string output = input;
std::transform(output.begin(), output.end(), output.begin(), ::toupper);
return output;
}
};
class AppendFilter : public Filter {
public:
std::string process(const std::string& input) override {
return input + " - Appended";
}
};
接着,定义一个管道来管理和连接这些过滤器:
class Pipeline {
private:
std::vector<std::unique_ptr<Filter>> filters;
public:
void addFilter(std::unique_ptr<Filter> filter) {
filters.push_back(std::move(filter));
}
std::string process(const std::string& input) {
std::string data = input;
for (auto& filter : filters) {
data = filter->process(data);
}
return data;
}
};
最后,使用这个架构处理数据:
int main() {
Pipeline myPipeline;
myPipeline.addFilter(std::make_unique<CapitalizeFilter>());
myPipeline.addFilter(std::make_unique<AppendFilter>());
std::string inputData = "hello world";
std::string result = myPipeline.process(inputData);
std::cout << "Processed Output: " << result << std::endl;
return 0;
}
本例的管道与过滤器架构如下图所示:
图 1 管道与过滤器架构图
展示了如何通过管道模式将字符串先转换为大写,然后在其后追加字符串。读者可以根据需要添加更多的过滤器或修改现有过滤器来处理不同类型的数据。
在 C++ 编程和开发中,管道与过滤器架构主要适用于以下几种类型的需求:
- 数据流处理:当程序需要处理的数据可以视为一个连续的流,并且这些数据需要经过多个处理步骤时,管道与过滤器架构非常合适。例如,音视频数据处理、实时数据监控系统等;
- 可复用性需求高:当不同的处理功能需要在不同的场景下复用时,将这些功能封装成独立的过滤器可以提高代码的可复用性。每个过滤器实现特定的数据处理任务,可独立于其他过滤器运行;
- 可扩展性和灵活性:在需要频繁修改或扩展处理逻辑的系统中,使用管道与过滤器架构可以轻松地添加、移除或替换过滤器,而不需要修改管道的其他部分。这种模式使得系统的维护和升级变得更加灵活;
- 并行处理需求:如果数据处理的各个步骤可以并行执行,管道与过滤器架构能够有效地利用多核处理器的优势,提高处理效率。每个过滤器可以在不同的线程或处理器上执行,提高整体的处理速度;
- 清晰的数据处理逻辑:在需要清晰定义数据处理各个阶段的系统中,使用管道与过滤器架构可以帮助开发者和设计者更好地理解数据流动和处理过程。这有助于降低系统的复杂性,并提高可理解性;
- 串行数据处理任务:适用于那些需要数据按照特定顺序经过多个处理阶段的应用,每个阶段对数据进行某种转换或提取信息,然后传递给下一个阶段。
例如,在图像处理软件中,原始图像数据可能需要经过一系列的处理过程,如缩放、滤镜应用、边缘检测等,这些都可以通过管道与过滤器架构来实现,每个处理步骤作为一个独立的过滤器。这样的设计不仅使得每个步骤的实现清晰,也方便以后根据需求添加或修改处理步骤。
总之,管道与过滤器架构提供了一种强大的方法来处理序列化的数据流和复杂的数据转换任务,其模块化和可扩展的特性使得它非常适合处理需要清晰处理逻辑和高并行性的应用场景。这种架构的实践不仅凸显了在 C++ 中处理数据流的效率,还展示了良好架构设计在软件开发中的重要性。