Python lxml库下载和安装教程(附安装包)
lxml 是 Python 生态中处理 XML 与 HTML 的高性能库,底层用 C 语言封装了 libxml2 与 libxslt,兼具执行效率与 Python 的简洁语法。
lxml 提供 ElementTree、XPath、XSLT、XML Schema 等全套接口,可在内存中快速构建、查询、修改、序列化文档,也能自动修补不规范的标签,常被爬虫、数据清洗、接口报文转换等场景当作“瑞士军刀”。
2) 进入 lxml 文件夹,在菜单栏中按照下图依次选择:
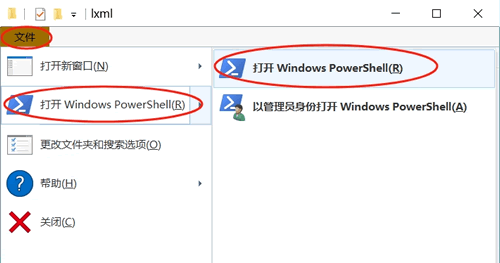
运行
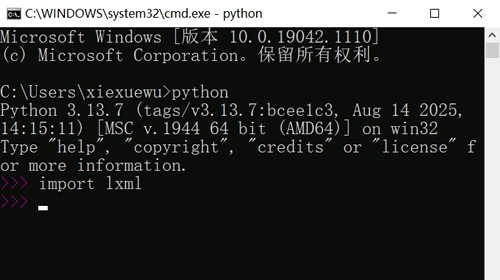
3) 安装成功后,在控制台命令中输入 python,并且可以正确引入 lxml 库,表示最终安装成功:
lxml 提供 ElementTree、XPath、XSLT、XML Schema 等全套接口,可在内存中快速构建、查询、修改、序列化文档,也能自动修补不规范的标签,常被爬虫、数据清洗、接口报文转换等场景当作“瑞士军刀”。
下载lxml
这里为大家提供了 lxml 最新版的安装包:安装lxml
1) 将下载好的 lxml-6.0.2-cp310-cp310-win_amd64.whl 库放到一个新的文件夹中,比如命名为 lxml。2) 进入 lxml 文件夹,在菜单栏中按照下图依次选择:
运行
pip install lxml-4.9.1-cp36-cp36m-win_amd64.whl 命令安装 lxml。3) 安装成功后,在控制台命令中输入 python,并且可以正确引入 lxml 库,表示最终安装成功:
lxml使用流程
lxml 库提供了一个 etree 模块,该模块专门用来解析 HTML/XML 文档,下面我们简单介绍一下 lxml 库的使用流程,如下所示:1) 导入模块
from lxml import etree
2) 创建解析对象
调用 etree 模块的 HTML() 方法来创建 HTML 解析对象。如下所示:parse_html = etree.HTML(html)HTML() 方法能够将 HTML 标签字符串解析为 HTML 文件,该方法可以自动修正 HTML 文本。示例如下:
from lxml import etree
html_str = '''
<div>
<ul>
<li class="item1"><a href="link1.html">Python</a></li>
<li class="item2"><a href="link2.html">Java</a></li>
<li class="site1"><a href="c.biancheng.net">C语言中文网</a>
<li class="site2"><a href="www.baidu.com">百度</a></li>
<li class="site3"><a href="www.jd.com">京东</a></li>
</ul>
</div>
'''
html = etree.HTML(html_str)
# tostring()将标签元素转换为字符串输出,注意:result为字节类型
result = etree.tostring(html)
print(result.decode('utf-8'))
输出结果如下:
<html><body><div>
<ul>
<li class="item1"><a href="link1.html">Python</a></li>
<li class="item2"><a href="link2.html">Java</a></li>
<li class="site1"><a href="c.biancheng.net">C语言中文网</a></li>
<li class="site2"><a href="www.baidu.com">百度</a></li>
<li class="site3"><a href="www.jd.com">京东</a>
</li></ul>
</div>
</body></html>
上述 HTML 字符串存在缺少标签的情况,比如“C语言中文网”缺少一个 </li> 闭合标签,当使用了 HTML() 方法后,会将其自动转换为符合规范的 HTML 文档格式。
3) 调用xpath表达式
最后使用第二步创建的解析对象调用 xpath() 方法,完成数据的提取,如下所示:
r_list = parse_html.xpath('xpath表达式')
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: