Go语言GMP调度模型详解(新手必看)
GMP 调度模型是 Go 语言实现并发的基础,在介绍 GMP 调度模型之前,我们先思考下面几个问题:
这些问题你可能了解一些,也可能不了解,不了解也不用担心,学习完本文之后,相信你会对 GMP 有一个比较清晰的认识。
首先明确一个概念,协程是 Go 语言的概念,操作系统是感知不到协程的,也就是说操作系统压根就不知道协程的存在,所以协程肯定不是由操作系统调度执行的。
其实协程是由线程 M 调度执行的。所以理论上只需要维护一个协程队列,再有个线程 M 能调度这些协程就可以了。
那逻辑处理器 P 是做什么的呢?貌似没有也行。其实 Go 语言最初版本确实就是这么设计的,这时候应该称之为 GM 调度模型,如下图所示:
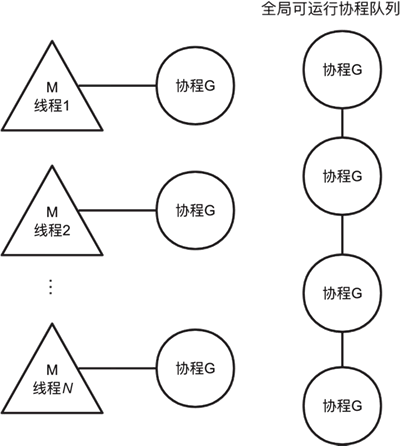
图 1 GM调度模型
但是需要注意的是,现代计算机通常是多核 CPU,也就是说,通常会有多个线程 M 调度协程 G。想想多个线程 M 从全局可运行协程队列获取协程的时候,是不是需要加锁呢?而加锁意味着低效。
所以,Go 语言在后续版本引入了逻辑处理器 P,每一个逻辑处理器 P 都有一个本地可运行协程队列,而线程 M 想要调度协程 G,必须绑定一个逻辑处理器 P,并且每一个逻辑处理器 P 只能被一个线程 M 绑定。这时候线程 M 只需要从其绑定的逻辑处理器 P 的本地可运行协程队列获取协程即可,显然这一操作是不需要加锁的。
那么,逻辑处理器 P 到底是什么呢?其实逻辑处理器 P 只是一个有很多字段的数据结构而已,可以简单地将逻辑处理器 P 理解成为一种资源,一般建议逻辑处理器 P 的数目和计算机 CPU 核数保持一致。这时候的调度模型称为 GMP 调度模型,如下图所示:
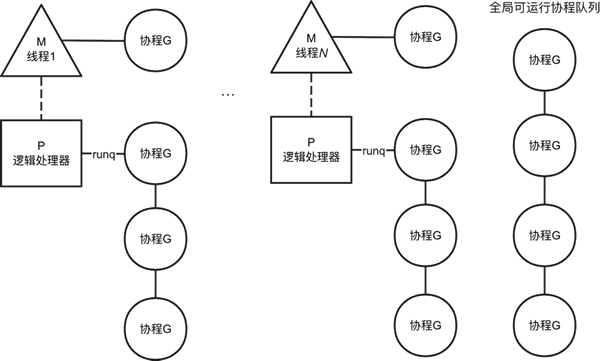
图 2 GMP调度模型
如图 2 所示,每一个逻辑处理器 P 都有一个本地可运行协程队列,线程 M 绑定逻辑处理器 P 之后才能调度协程。Go 语言调度协程比操作系统调度线程简单得多,目前只有简单的时间片调度以及抢占式调度。
另外可以看到,实际上还有一个全局可运行协程队列,这是为了避免多个逻辑处理器 P 的负载分配不均衡,新创建的协程在某些条件下会加入全局可运行协程队列,线程 M 在调度协程时,也有可能从全局可运行协程队列获取协程,当然这时候就需要加锁了。
我们已经知道,逻辑处理器 P 在一定程度上避免了低效的加锁操作,而 Go 语言后续的很多设计都采取了这种思想,包括定时器、内存分配等,都是通过将共享数据关联到逻辑处理器 P 上来避免加锁。
简单了解 GMP 调度模型后,接下来要研究的是我们的重点协程 G。协程到底是什么呢?创建一个协程只是简单地创建一个数据结构吗?参考我们了解的线程,创建一个线程,操作系统会分配对应的线程栈,线程切换时,操作系统会保存线程上下文,同时恢复另一个线程上下文。协程需要协程栈吗?当然需要,因为协程和线程一样,都有可能被并发调度执行。
这里还有一个问题需要解决,线程创建后,操作系统自动分配线程栈,而操作系统根本不知道协程,那么如何为其分配协程栈呢?
实际上,协程栈是由 Go 语言自己管理的。看到这里你可能会觉得奇怪,Go 语言能自己管理协程栈吗?写过 C 程序的人都知道,开发者只能申请与管理堆内存,并不能管理线程栈,那么 Go 语言是如何管理协程栈的呢?这就不得不说一下 Linux 虚拟内存结构了,如下图所示。
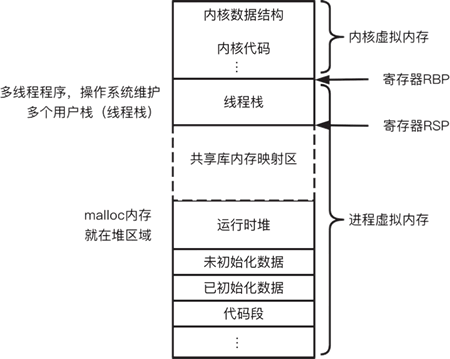
图 3 Linux 虚拟内存结构
如图 3 所示,Linux 虚拟内存被划分为代码段、数据段、运行时堆、共享库内存映射区、线程栈和内核区域。线程栈是由操作系统维护的,开发者通过 malloc 申请的内存大多在运行时堆区域。既然操作系统不能维护协程栈,那么 Go 语言是否可以自己申请一块堆内存,将其用作协程栈呢?可是,这明明是运行时堆啊,协程运行过程中,操作系统怎么知道这块堆内存就是栈呢?
其实栈内存是由两个寄存器标识的,寄存器 RSP 指向栈顶,寄存器 RBP 指向栈底,而用户程序可以修改寄存器的内容。也就是说,Go 语言只需要申请一块堆内存,并且修改寄存器 RBP 以及 RSP 的内容,使其指向这块堆内存就行了。这样对操作系统而言,这块堆内存就是栈了。
总结一下,操作系统并不知道协程的概念,并且协程可以像线程一样被调度执行,所以我们才说协程就是用户态的线程。协程栈就是将堆内存当成栈来用而已,每一个协程都对应一个协程栈,协程间的切换对 Go 语言来说,也只不过是寄存器 RBP 和 RSP 的保存以及恢复,并不需要陷入内核态。
Go 语言针对 GMP 分别定义了对应的数据结构,如下面代码所示:
结构体 m 的各字段解释如下:
结构体 g 的各字段解释如下:
结构体 p 的各字段解释如下:
看到了吧,GMP 调度模型其实并没有多复杂,扒开 Go 底层源码来看,GMP 只不过是三个比较复杂的数据结构罢了。针对逻辑处理器 P 再强调一点,我们一直说线程 M 必须绑定逻辑处理器 P 才能调度协程 G,而且逻辑处理器 P 只能被一个线程 M 绑定。
针对这一个设计理念,Go 语言还定义了逻辑处理器 P 的状态,定义如下:
逻辑处理器 P 的各状态含义如下:
结合 Go 语言对 GMP 模型的定义,以及我们对协程栈的理解,我们可以得到下图:
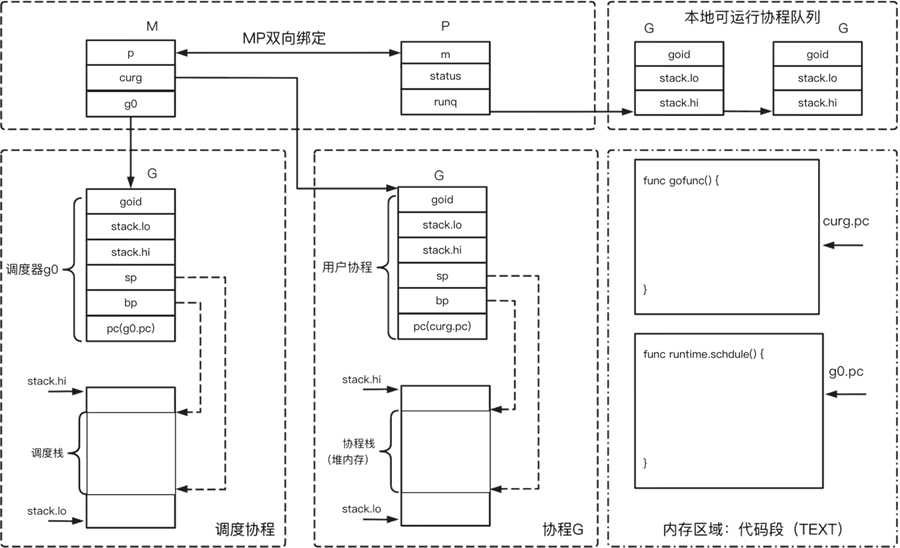
图 4 GMP 结构示意图
参考图 4,每一个线程 M 都有一个调度协程 g0,g0 协程的主函数是 runtime.schedule,该函数实现了协程调度功能。每一个协程都有一个协程栈,这个栈不是操作系统维护的,而是 Go 语言在运行时堆申请的一块内存。线程 M 必须绑定逻辑处理器 P 才能调度协程 G,每一个逻辑处理器 P 都有一个本地可运行协程队列。协程在切换时,需要保存/恢复上下文信息,如栈寄存器 RBP、RSP,指令寄存器 PC,这些信息在协程 G 对应的结构体都有定义。
最后需要注意的是,协程 G 的主函数 gofunc、调度协程 g0 的主函数 runtime.schedule,都存储在 Linux 虚拟内存的代码段,协程 G 的 pc 字段指向的是 gofunc 函数的某一条指令,协程 g0 的 pc 字段指向的是 runtime.schedule 函数的某一条指令。
- 协程为什么能并发执行呢?想想我们了解的线程,每一个线程都有一个栈帧,操作系统负责调度线程,而线程切换必然伴随着栈帧的切换。协程有栈帧吗?协程的调度由谁负责呢?
- 总是听到别人说协程是用户态线程,用户态是什么意思?协程与线程有什么关系?协程的创建以及切换不需要陷入内核态吗?
- Go 语言如何管理以及调度成千上万个协程?是否和操作系统一样,维护着可运行队列和阻塞队列?有没有所谓的按照时间片调度?或者是优先级调度?又或者是抢占式调度?
这些问题你可能了解一些,也可能不了解,不了解也不用担心,学习完本文之后,相信你会对 GMP 有一个比较清晰的认识。
首先明确一个概念,协程是 Go 语言的概念,操作系统是感知不到协程的,也就是说操作系统压根就不知道协程的存在,所以协程肯定不是由操作系统调度执行的。
其实协程是由线程 M 调度执行的。所以理论上只需要维护一个协程队列,再有个线程 M 能调度这些协程就可以了。
那逻辑处理器 P 是做什么的呢?貌似没有也行。其实 Go 语言最初版本确实就是这么设计的,这时候应该称之为 GM 调度模型,如下图所示:
图 1 GM调度模型
但是需要注意的是,现代计算机通常是多核 CPU,也就是说,通常会有多个线程 M 调度协程 G。想想多个线程 M 从全局可运行协程队列获取协程的时候,是不是需要加锁呢?而加锁意味着低效。
所以,Go 语言在后续版本引入了逻辑处理器 P,每一个逻辑处理器 P 都有一个本地可运行协程队列,而线程 M 想要调度协程 G,必须绑定一个逻辑处理器 P,并且每一个逻辑处理器 P 只能被一个线程 M 绑定。这时候线程 M 只需要从其绑定的逻辑处理器 P 的本地可运行协程队列获取协程即可,显然这一操作是不需要加锁的。
那么,逻辑处理器 P 到底是什么呢?其实逻辑处理器 P 只是一个有很多字段的数据结构而已,可以简单地将逻辑处理器 P 理解成为一种资源,一般建议逻辑处理器 P 的数目和计算机 CPU 核数保持一致。这时候的调度模型称为 GMP 调度模型,如下图所示:
图 2 GMP调度模型
如图 2 所示,每一个逻辑处理器 P 都有一个本地可运行协程队列,线程 M 绑定逻辑处理器 P 之后才能调度协程。Go 语言调度协程比操作系统调度线程简单得多,目前只有简单的时间片调度以及抢占式调度。
另外可以看到,实际上还有一个全局可运行协程队列,这是为了避免多个逻辑处理器 P 的负载分配不均衡,新创建的协程在某些条件下会加入全局可运行协程队列,线程 M 在调度协程时,也有可能从全局可运行协程队列获取协程,当然这时候就需要加锁了。
我们已经知道,逻辑处理器 P 在一定程度上避免了低效的加锁操作,而 Go 语言后续的很多设计都采取了这种思想,包括定时器、内存分配等,都是通过将共享数据关联到逻辑处理器 P 上来避免加锁。
简单了解 GMP 调度模型后,接下来要研究的是我们的重点协程 G。协程到底是什么呢?创建一个协程只是简单地创建一个数据结构吗?参考我们了解的线程,创建一个线程,操作系统会分配对应的线程栈,线程切换时,操作系统会保存线程上下文,同时恢复另一个线程上下文。协程需要协程栈吗?当然需要,因为协程和线程一样,都有可能被并发调度执行。
这里还有一个问题需要解决,线程创建后,操作系统自动分配线程栈,而操作系统根本不知道协程,那么如何为其分配协程栈呢?
实际上,协程栈是由 Go 语言自己管理的。看到这里你可能会觉得奇怪,Go 语言能自己管理协程栈吗?写过 C 程序的人都知道,开发者只能申请与管理堆内存,并不能管理线程栈,那么 Go 语言是如何管理协程栈的呢?这就不得不说一下 Linux 虚拟内存结构了,如下图所示。
图 3 Linux 虚拟内存结构
如图 3 所示,Linux 虚拟内存被划分为代码段、数据段、运行时堆、共享库内存映射区、线程栈和内核区域。线程栈是由操作系统维护的,开发者通过 malloc 申请的内存大多在运行时堆区域。既然操作系统不能维护协程栈,那么 Go 语言是否可以自己申请一块堆内存,将其用作协程栈呢?可是,这明明是运行时堆啊,协程运行过程中,操作系统怎么知道这块堆内存就是栈呢?
其实栈内存是由两个寄存器标识的,寄存器 RSP 指向栈顶,寄存器 RBP 指向栈底,而用户程序可以修改寄存器的内容。也就是说,Go 语言只需要申请一块堆内存,并且修改寄存器 RBP 以及 RSP 的内容,使其指向这块堆内存就行了。这样对操作系统而言,这块堆内存就是栈了。
总结一下,操作系统并不知道协程的概念,并且协程可以像线程一样被调度执行,所以我们才说协程就是用户态的线程。协程栈就是将堆内存当成栈来用而已,每一个协程都对应一个协程栈,协程间的切换对 Go 语言来说,也只不过是寄存器 RBP 和 RSP 的保存以及恢复,并不需要陷入内核态。
深入理解GMP调度模型
经过前面的学习,我们已经对 GMP 调度模型有了比较清晰的认识:- G(goroutine)代表协程,每一个协程都有一个协程栈;
- M(machine)代表线程,运行调度程序,负责协程 G 的调度执行;
- P(processor)代表逻辑处理器,可以理解为一种资源,线程 M 必须绑定逻辑处理器 P 才能调度协程 G。
Go 语言针对 GMP 分别定义了对应的数据结构,如下面代码所示:
type m struct {
g0 *g // g0就是调度“协程”,执行调度程序
curg *g // 当前正在调度执行的协程
p puintptr // 当前绑定的逻辑处理器P
}
type g struct {
goid int64 // 协程ID
stack stack // 协程栈
m *m // 当前协程被哪一个线程M调度执行
sched gobuf // 协程上下文,用于保存协程栈寄存器RBP、RSP,以及指令寄存器PC
}
type p struct {
status uint32 // 逻辑处理器P的状态,如空闲、正在运行(已经被线程M绑定)等
m muintptr // 当前绑定的线程M
runq [256]guintptr // 本地可运行协程队列
}
结构体 m、g、p 的定义非常复杂,上面的代码只是列出了一些与 GMP 调度模型相关的字段。结构体 m 的各字段解释如下:
- g0:g 指针,说明该字段指向了一个协程。线程 M 是一个标准的线程,也有线程栈,这个线程栈上运行的程序就是调度程序,负责调度协程 G。Go 语言将调度程序也封装为一个协程,称为 g0 协程;
- curg:g 指针,指向线程 M 正在调度执行的协程;
- p:是一个指针,指向线程 M 绑定的逻辑处理器 P。
结构体 g 的各字段解释如下:
- goid:协程 ID,每一个协程在创建的时候都会分配一个协程 ID。
- stack:顾名思义协程栈,该字段类型为 stack,包含两个指针类型的字段,分别指向协程栈的栈顶以及栈底。
- m:m指针,表示协程是被哪一个线程 M 调度执行的。
- sched:存储与协程调度相关的上下文信息,协程切换时,会将待换出协程的栈寄存器RBP、RSP,以及指令寄存器 PC 缓存在 sched 字段,同时从待换入协程的 sched 字段恢复栈寄存器 RBP、RSP,以及指令寄存器 PC。
结构体 p 的各字段解释如下:
- status:描述逻辑处理器 P 的状态,如空闲状态,正在运行状态(说明当前逻辑处理器P已经被线程M绑定了)等。
- m:逻辑处理器 P 与线程 M 是双向绑定关系,该字段指向当前逻辑处理器 P 绑定的线程 M。
- runq:逻辑处理器 P 的本地可运行协程队列,线程 M 调度协程 G 时,一般情况下优先从其绑定的逻辑处理器 P 的本地可运行协程队列调度协程 G。
看到了吧,GMP 调度模型其实并没有多复杂,扒开 Go 底层源码来看,GMP 只不过是三个比较复杂的数据结构罢了。针对逻辑处理器 P 再强调一点,我们一直说线程 M 必须绑定逻辑处理器 P 才能调度协程 G,而且逻辑处理器 P 只能被一个线程 M 绑定。
针对这一个设计理念,Go 语言还定义了逻辑处理器 P 的状态,定义如下:
const (
_Pidle = iota // 空闲,没有绑定线程M
_Prunning // 正在运行,已经绑定了线程M
_Psyscall // 正在执行系统调用
_Pgcstop // 暂停中,垃圾回收可能需要暂停所有用户代码,需要暂停所有的P
_Pdead // 已死亡
)
逻辑处理器 P 的各状态含义如下:
- _Pidle:空闲状态,说明当前逻辑处理器 P 没有绑定线程 M,线程 M 绑定逻辑处理器 P 时,查找的就是这种状态的逻辑处理器 P。
- _Prunning:正在运行,说明当前逻辑处理器 P 已经绑定了线程 M。
- _Psyscall:顾名思义系统调用,说明当前逻辑处理器 P 绑定的线程 M 正在执行系统调用,这是一个比较特殊的状态。
- _Pgcstop:暂停中,什么情况下需要暂停逻辑处理器 P 呢?有一个典型的场景是垃圾回收。在垃圾回收的过程中,是有可能需要暂停所有用户代码的,这时候会暂停所有的逻辑处理器P。
- _Pdead:已死亡,这种状态的逻辑处理器 P 不能再被使用了。比如当我们通过 GOMAXPROCS 函数调整(减小)逻辑处理器 P 的数目时,多余的逻辑处理器 P 就转换为这种状态了。
结合 Go 语言对 GMP 模型的定义,以及我们对协程栈的理解,我们可以得到下图:
图 4 GMP 结构示意图
参考图 4,每一个线程 M 都有一个调度协程 g0,g0 协程的主函数是 runtime.schedule,该函数实现了协程调度功能。每一个协程都有一个协程栈,这个栈不是操作系统维护的,而是 Go 语言在运行时堆申请的一块内存。线程 M 必须绑定逻辑处理器 P 才能调度协程 G,每一个逻辑处理器 P 都有一个本地可运行协程队列。协程在切换时,需要保存/恢复上下文信息,如栈寄存器 RBP、RSP,指令寄存器 PC,这些信息在协程 G 对应的结构体都有定义。
最后需要注意的是,协程 G 的主函数 gofunc、调度协程 g0 的主函数 runtime.schedule,都存储在 Linux 虚拟内存的代码段,协程 G 的 pc 字段指向的是 gofunc 函数的某一条指令,协程 g0 的 pc 字段指向的是 runtime.schedule 函数的某一条指令。