自然语言处理的3个模型(新手必看)
自然语言处理学科属于计算机与语言学的交叉学科,旨在研究使用计算机技术处理各类文本数据,主要的研究方向有语义分析、机器翻译等。
文本预训练对于自然语言处理任务有着巨大的提升和帮助,而预训练模型也越来越多,从最初的Word2Vec模型到Seq2Seq模型和Attention模型,本节深入介绍这些模型。
在日常生活中使用的自然语言不能够直接被计算机所理解,当我们需要对这些自然语言进行处理时,就需要使用特定的手段对其进行分析或预处理。使用 one-hot 编码形式对文字进行处理可以得到词向量,但是,对文字进行唯一编号进行分析的方式存在数据稀疏的问题,Word2Vec 能够解决这一问题,实现 Word Embedding(个人理解为:某文本中词汇的关联关系,例如北京-中国、伦敦-英国)。
Word2Vec 模型的主要用途有两点:
算法流程如下:
因此,Word2Vec 实质上是一种降维操作,即将 one-hot 形式的词向量转换为 Word2Vec 形式。
比如,当我们使用机器翻译时:输入(Hello)→输出(你好)。再比如,在人机对话中,我们问机器:“你是谁?”,机器会返回“我是某某”。
Seq2Seq 属于 Encoder-Decoder 结构的一种,常见的 Encoder-Decoder 结构的基本思想就是利用两个 RNN,一个 RNN 作为 Encoder,另一个 RNN 作为 Decoder。Encoder 负责将输入序列压缩成指定长度的向量,这个向量就可以看成这个序列的语义,这个过程称为编码,如下图所示。
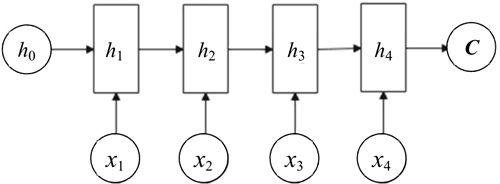
图 1 Encoder编码过程
获取语义向量最简单的方式就是直接将最后一个输入的隐状态作为语义向量 C。也可以对最后一个隐含状态做一个变换得到语义向量,还可以将输入序列的所有隐含状态做一个变换得到语义变量。
而 Decoder 则负责根据语义向量生成指定的序列,这个过程也称为解码,如下图所示:
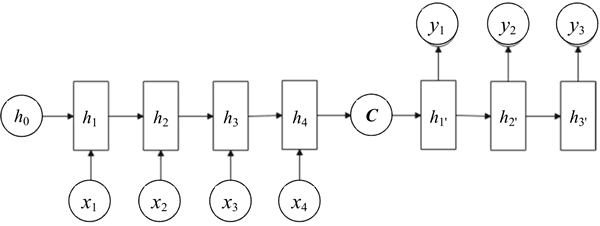
图 2 Decoder 解码过程
最简单的方式是将 Encoder 得到的语义变量作为初始状态输入 Decoder 的 RNN 中,得到输出序列。可以看到上一时刻的输出会作为当前时刻的输入,而且其中语义向量 C 只作为初始状态参与运算,后面的运算都与语义向量 C 无关。
Decoder 的处理方式还有一种,就是语义向量 C 参与了序列所有时刻的运算,如下图所示,上一时刻的输出仍然作为当前时刻的输入,但语义向量 C 会参与所有时刻的运算。
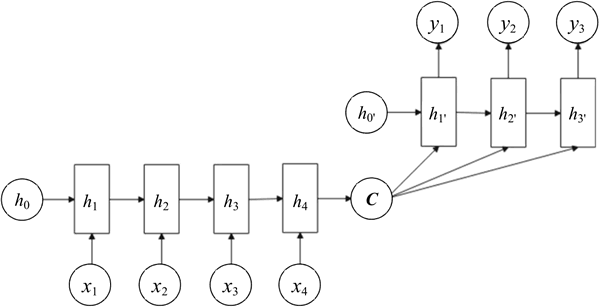
图 3 语义向量参与解码
如何衡量特征的重要性?最直观的方法就是权重,因此,Attention 模型的结果就是在每次识别时,首先计算每个特征的权值,然后对特征进行加权求和,权值越大,该特征对当前识别的贡献就越大。
机器翻译中的 Attention 模型最直观,也最易于理解,因为每生成一个单词,找到源句子中与其对应的单词,翻译才准确。此处就以机器翻译为例讲解 Attention 模型的基本原理,目前机器翻译领域应用最广泛的模型—— Encoder-Decoder 结构。
Encoder-Decoder 结构包括两部分,分别是 Encoder 和 Decoder:
Encoder 和 Decoder 是两个独立的模型,可以采用神经网络,也可以采用其他模型。
Attention 在 Encoder-Decoder 中介于 Encoder 和 Decoder 之间,首先根据 Encoder 和 Decoder 的特征计算权值,然后对 Encoder 的特征进行加权求和,作为 Decoder 的输入,其作用是将 Encoder 的特征以更好的方式呈献给 Decoder。
文本预训练对于自然语言处理任务有着巨大的提升和帮助,而预训练模型也越来越多,从最初的Word2Vec模型到Seq2Seq模型和Attention模型,本节深入介绍这些模型。
Word2Vec模型
Word2Vec 模型使用一层神经网络将 one-hot(独热编码)形式的词向量映射到分布式形式的词向量,使用了层次 Softmax、负采样(Negative Sampling)等技巧进行训练速度上的优化。在日常生活中使用的自然语言不能够直接被计算机所理解,当我们需要对这些自然语言进行处理时,就需要使用特定的手段对其进行分析或预处理。使用 one-hot 编码形式对文字进行处理可以得到词向量,但是,对文字进行唯一编号进行分析的方式存在数据稀疏的问题,Word2Vec 能够解决这一问题,实现 Word Embedding(个人理解为:某文本中词汇的关联关系,例如北京-中国、伦敦-英国)。
Word2Vec 模型的主要用途有两点:
- 一是用于其他复杂的神经网络模型的初始化(预处理);
- 二是把词与词之间的相似度用作某个模型的特征(分析)。
算法流程如下:
- 将 one-hot 形式的词向量输入单层神经网络中,其中输入层的神经元节点个数应该和 one-hot 形式的词向量维数相对应;
- 通过神经网络中的映射层中的激活函数计算目标单词与其他词汇的关联概率,在计算时使用了负采样的方式来提高其训练速度和正确率;
- 通过使用随机梯度下降(SGD)优化算法计算损失;
- 通过反向传播算法对神经元的各个权重和偏置进行更新。
因此,Word2Vec 实质上是一种降维操作,即将 one-hot 形式的词向量转换为 Word2Vec 形式。
Seq2Seq模型
Seq2Seq 模型在输出长度不确定时采用,这种情况一般是在机器翻译任务中出现,将一句中文翻译成英文,那么这句英文的长度有可能比中文短,也有可能比中文长,所以输出的长度就不确定了。比如,当我们使用机器翻译时:输入(Hello)→输出(你好)。再比如,在人机对话中,我们问机器:“你是谁?”,机器会返回“我是某某”。
Seq2Seq 属于 Encoder-Decoder 结构的一种,常见的 Encoder-Decoder 结构的基本思想就是利用两个 RNN,一个 RNN 作为 Encoder,另一个 RNN 作为 Decoder。Encoder 负责将输入序列压缩成指定长度的向量,这个向量就可以看成这个序列的语义,这个过程称为编码,如下图所示。
图 1 Encoder编码过程
获取语义向量最简单的方式就是直接将最后一个输入的隐状态作为语义向量 C。也可以对最后一个隐含状态做一个变换得到语义向量,还可以将输入序列的所有隐含状态做一个变换得到语义变量。
而 Decoder 则负责根据语义向量生成指定的序列,这个过程也称为解码,如下图所示:
图 2 Decoder 解码过程
最简单的方式是将 Encoder 得到的语义变量作为初始状态输入 Decoder 的 RNN 中,得到输出序列。可以看到上一时刻的输出会作为当前时刻的输入,而且其中语义向量 C 只作为初始状态参与运算,后面的运算都与语义向量 C 无关。
Decoder 的处理方式还有一种,就是语义向量 C 参与了序列所有时刻的运算,如下图所示,上一时刻的输出仍然作为当前时刻的输入,但语义向量 C 会参与所有时刻的运算。
图 3 语义向量参与解码
Attention模型
Attention 模型最初应用于图像识别,模仿人看图像时,目光的焦点在不同的物体上移动。当神经网络对图像或语言进行识别时,每次集中于部分特征上,识别更加准确。如何衡量特征的重要性?最直观的方法就是权重,因此,Attention 模型的结果就是在每次识别时,首先计算每个特征的权值,然后对特征进行加权求和,权值越大,该特征对当前识别的贡献就越大。
机器翻译中的 Attention 模型最直观,也最易于理解,因为每生成一个单词,找到源句子中与其对应的单词,翻译才准确。此处就以机器翻译为例讲解 Attention 模型的基本原理,目前机器翻译领域应用最广泛的模型—— Encoder-Decoder 结构。
Encoder-Decoder 结构包括两部分,分别是 Encoder 和 Decoder:
- Encoder 将输入数据(如图像或文本)编码为一系列特征;
- Decoder 以编码的特征作为输入,将其解码为目标输出。
Encoder 和 Decoder 是两个独立的模型,可以采用神经网络,也可以采用其他模型。
Attention 在 Encoder-Decoder 中介于 Encoder 和 Decoder 之间,首先根据 Encoder 和 Decoder 的特征计算权值,然后对 Encoder 的特征进行加权求和,作为 Decoder 的输入,其作用是将 Encoder 的特征以更好的方式呈献给 Decoder。