PyTorch模型评估的多种方法(附带实例)
当我们建立好相关模型以后,怎么评价建立的模型好坏,以及优化建立的模型呢?本节介绍机器学习中模型评估的方法及其案例。
混淆矩阵是机器学习中统计分类模型预测结果的表,它以矩阵形式将数据集中的记录按照真实的类别与分类模型预测的类别进行汇总,其中矩阵的行表示真实值,矩阵的列表示模型的预测值。
下面我们举一个例子,建立一个二分类的混淆矩阵,假如宠物店有 10 只动物,其中 6 只狗,4 只猫,现在有一个分类器将这 10 只动物进行分类,分类结果为 5 只狗,5 只猫,我们画出分类结果的混淆矩阵,如下表所示(把狗作为正类)。
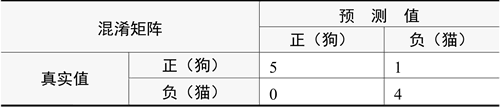
通过混淆矩阵可以计算出真实狗的数量(行相加)为 6(5+1),真实猫的数量为 4(0+4),预测值分类得到狗的数量(列相加)为 5(5+0),分类得到猫的数量为 5(1+4)。
下面介绍几个指标:
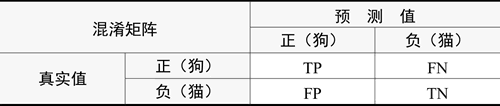
同时,我们不难发现,对于二分类问题,矩阵中的 4 个元素刚好表示 TP、TN、FP、TN 这 4 个指标,如下表所示。
如果一个学习器的 ROC 曲线能将另一个学习器的 ROC 曲线完全包括,则说明该学习器的性能优于另一个学习器。ROC 曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC 曲线能够保持不变。
ROC 曲线的横轴表示 FPR,即错误地预测为正例的概率,纵轴表示 TPR,即正确地预测为正例的概率,二者的计算公式如下:
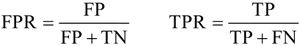
使用 AUC 值作为评价标准是因为很多时候 ROC 曲线并不能清晰地说明哪个分类器的效果更好,而作为一个数值,对应 AUC 更大的分类器效果更好。与 F1-score 不同的是,AUC 值并不需要先设定一个阈值。
当然,AUC 值越大,当前的分类算法越有可能将正样本排在负样本前面,即能够更好地分类,可以从 AUC 判断分类器(预测模型)优劣的标准:
判定系数是一个解释性系数,在回归分析中,其主要作用是评估回归模型对因变量y产生变化的解释程度,即判定系数 R 平方是评估回归模型好坏的指标。
R 平方的取值范围为 0~1,通常以百分数表示。比如回归模型的 R 平方等于 0.7,那么表示此回归模型对预测结果的可解释程度为 70%。
一般认为,R 平方大于 0.75,表示模型拟合度很好,可解释程度较高;R 平方小于 0.5,表示模型拟合有问题,不宜进行回归分析。
在多元回归实际应用中,判定系数 R 平方的最大缺陷:增加自变量的个数时,判定系数就会增加,即随着自变量的增多,R 平方会越来越大,会显得回归模型精度很高,有较好的拟合效果。而实际上可能并非如此,有些自变量与因变量完全不相关,增加这些自变量并不会提升拟合水平和预测精度。
为解决这个问题,即避免增加自变量而高估 R 平方,需要对 R 平方进行调整。采用的方法是用样本量 n 和自变量的个数 k 来调整 R 平方,调整后的 R 平方的计算公式如下:
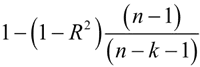
从公式可以看出,调整后的 R 平方同时考虑了样本量(n)和回归中自变量的个数(k)的影响,这使得调整后的 R 平方永远小于 R 平方,并且调整后的 R 平方的值不会由于回归中自变量个数的增加而越来越接近 1。
因调整后的 R 平方较 R 平方测算得更准确,在回归分析尤其是多元回归中,通常使用调整后的 R 平方对回归模型进行精度测算,以评估回归模型的拟合度和效果。
一般认为,在回归分析中,0.5 为调整后的 R 平方的临界值,如果调整后的 R 平方小于 0.5,则要分析我们所采用和未采用的自变量。如果调整后的 R 平方与 R 平方存在明显差异,则意味着所用的自变量不能很好地测算因变量的变化,或者是遗漏了一些可用的自变量。调整后的 R 平方与原来 R 平方之间的差距越大,模型的拟合效果就越差。
通常,回归算法的残差评价指标有均方误差(Mean Squared Error,MSE)、均方根误差(Root Mean Square Error,RMSE)、平均绝对误差(Mean Absolute Error,MAE)3个。
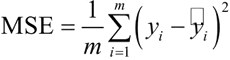
即真实值减去预测值,然后再求平方和,最后求平均值。这个公式其实就是线性回归的损失函数,线性回归的目的就是让这个损失函数的数值最小。
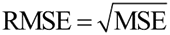
即均方误差的平方根,均方根误差是有单位的,与样本数据是一样的。
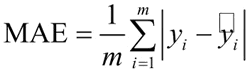
MAE 是一种线性分数,所有个体差异在平均值上的权重都相等,而 RMSE 相比 MAE,会对高的差异惩罚更多。
混淆矩阵
在机器学习中,正样本就是使模型得出正确结论的例子,负样本是使得模型得出错误结论的例子。比如你要从一张猫和狗的图片中检测出狗,那么狗就是正样本,猫就是负样本;反过来,你如果想从中检测出猫,那么猫就是正样本,狗就是负样本。混淆矩阵是机器学习中统计分类模型预测结果的表,它以矩阵形式将数据集中的记录按照真实的类别与分类模型预测的类别进行汇总,其中矩阵的行表示真实值,矩阵的列表示模型的预测值。
下面我们举一个例子,建立一个二分类的混淆矩阵,假如宠物店有 10 只动物,其中 6 只狗,4 只猫,现在有一个分类器将这 10 只动物进行分类,分类结果为 5 只狗,5 只猫,我们画出分类结果的混淆矩阵,如下表所示(把狗作为正类)。
表:混淆矩阵
通过混淆矩阵可以计算出真实狗的数量(行相加)为 6(5+1),真实猫的数量为 4(0+4),预测值分类得到狗的数量(列相加)为 5(5+0),分类得到猫的数量为 5(1+4)。
下面介绍几个指标:
- TP(True Positive):被判定为正样本,事实上也是正样本。真的正样本也叫真阳性。
- FN(False Negative):被判定为负样本,但事实上是正样本。假的负样本也叫假阴性。
- FP(False Positive):被判定为正样本,但事实上是负样本。假的正样本也叫假阳性。
- TN(True Negative):被判定为负样本,事实上也是负样本。真的负样本也叫真阴性。
同时,我们不难发现,对于二分类问题,矩阵中的 4 个元素刚好表示 TP、TN、FP、TN 这 4 个指标,如下表所示。
表:混淆矩阵
ROC曲线
ROC 曲线的全称是“受试者工作特征”,通常用来衡量一个二分类学习器的好坏。如果一个学习器的 ROC 曲线能将另一个学习器的 ROC 曲线完全包括,则说明该学习器的性能优于另一个学习器。ROC 曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC 曲线能够保持不变。
ROC 曲线的横轴表示 FPR,即错误地预测为正例的概率,纵轴表示 TPR,即正确地预测为正例的概率,二者的计算公式如下:
AUC
AUC 是一个数值,它是 ROC 曲线与坐标轴围成的面积。很明显,TPR 越大、FPR 越小,模型效果越好,ROC 曲线就越靠近左上角,表明模型效果越好,此时 AUC 值越大,极端情况下为 1。由于 ROC 曲线一般都处于 y=x 直线的上方,因此 AUC 的取值范围一般在 0.5 和 1 之间。使用 AUC 值作为评价标准是因为很多时候 ROC 曲线并不能清晰地说明哪个分类器的效果更好,而作为一个数值,对应 AUC 更大的分类器效果更好。与 F1-score 不同的是,AUC 值并不需要先设定一个阈值。
当然,AUC 值越大,当前的分类算法越有可能将正样本排在负样本前面,即能够更好地分类,可以从 AUC 判断分类器(预测模型)优劣的标准:
- AUC = 1:是完美分类器,采用这个预测模型时,存在至少一个阈值能得出完美预测。绝大多数预测的场合不存在完美分类器;
- 0.5 < AUC < 1:优于随机猜测。这个分类器(模型)妥善设定阈值的话,有预测价值;
- AUC = 0.5:跟随机猜测一样,模型没有预测价值;
- AUC < 0.5:比随机猜测还差。
R平方
判定系数 R 平方,又叫决定系数,是指在线性回归中,回归可解释离差平方和与总离差平方和的比值,其数值等于相关系数 R 的平方。判定系数是一个解释性系数,在回归分析中,其主要作用是评估回归模型对因变量y产生变化的解释程度,即判定系数 R 平方是评估回归模型好坏的指标。
R 平方的取值范围为 0~1,通常以百分数表示。比如回归模型的 R 平方等于 0.7,那么表示此回归模型对预测结果的可解释程度为 70%。
一般认为,R 平方大于 0.75,表示模型拟合度很好,可解释程度较高;R 平方小于 0.5,表示模型拟合有问题,不宜进行回归分析。
在多元回归实际应用中,判定系数 R 平方的最大缺陷:增加自变量的个数时,判定系数就会增加,即随着自变量的增多,R 平方会越来越大,会显得回归模型精度很高,有较好的拟合效果。而实际上可能并非如此,有些自变量与因变量完全不相关,增加这些自变量并不会提升拟合水平和预测精度。
为解决这个问题,即避免增加自变量而高估 R 平方,需要对 R 平方进行调整。采用的方法是用样本量 n 和自变量的个数 k 来调整 R 平方,调整后的 R 平方的计算公式如下:
从公式可以看出,调整后的 R 平方同时考虑了样本量(n)和回归中自变量的个数(k)的影响,这使得调整后的 R 平方永远小于 R 平方,并且调整后的 R 平方的值不会由于回归中自变量个数的增加而越来越接近 1。
因调整后的 R 平方较 R 平方测算得更准确,在回归分析尤其是多元回归中,通常使用调整后的 R 平方对回归模型进行精度测算,以评估回归模型的拟合度和效果。
一般认为,在回归分析中,0.5 为调整后的 R 平方的临界值,如果调整后的 R 平方小于 0.5,则要分析我们所采用和未采用的自变量。如果调整后的 R 平方与 R 平方存在明显差异,则意味着所用的自变量不能很好地测算因变量的变化,或者是遗漏了一些可用的自变量。调整后的 R 平方与原来 R 平方之间的差距越大,模型的拟合效果就越差。
残差
残差在数理统计中是指实际观察值与估计值(拟合值)之间的差,它蕴含了有关模型基本假设的重要信息。如果回归模型正确的话,我们可以将残差看作误差的观测值。通常,回归算法的残差评价指标有均方误差(Mean Squared Error,MSE)、均方根误差(Root Mean Square Error,RMSE)、平均绝对误差(Mean Absolute Error,MAE)3个。
1) 均方误差
均方误差(MSE)表示预测值和观测值之间差异(残差平方)的平均值,公式如下:即真实值减去预测值,然后再求平方和,最后求平均值。这个公式其实就是线性回归的损失函数,线性回归的目的就是让这个损失函数的数值最小。
2) 均方根误差
均方根误差(RMSE)表示预测值和观测值之间差异(残差)的样本标准差,公式如下:即均方误差的平方根,均方根误差是有单位的,与样本数据是一样的。
3) 平均绝对误差
平均绝对误差(MAE)表示预测值和观测值之间绝对误差的平均值,公式如下:MAE 是一种线性分数,所有个体差异在平均值上的权重都相等,而 RMSE 相比 MAE,会对高的差异惩罚更多。