ClickHouse是什么(超级详细)
商务智能(Business Intelligence,BI)系统的典型应用场景是多维分析,某些时候可以直接使用 OLAP 指代这类场景。一款优秀的 BI 类产品应该需要具备一站式、自服务且简单易用、实时应答、专业化和智能化的特征。
ClickHouse 具有 ROLAP、在线实时查询、完整的数据库管理系统、列式存储、不需要任何数据预处理、支持批量更新、拥有非常完善的 SQL 支持和函数、支持高可用、不依赖 Hadoop 复杂生态、开箱即用等许多特点,因此非常适用于 BI 领域。同时,ClickHouse 也广泛应用于电信、金融、信息安全、物联网等领域。
在采集数据的过程中,Click(点击)一次页面会产生一个 Event(事件)。这个过程可以理解为基于页面的点击事件(流),面向数据仓库进行 OLAP 分析,因此 ClickHouse 的全称是 Click Stream,Data WareHouse。
下图展示了 ClickHouse 名称的含义:

图 1 ClickHouse 名称的含义
ClickHouse 的表从数据分布上来看,可以分为本地表和分布式表两种类型;从存储引擎上来看,可以分为单机表和复制表两种类型。
常用的分区字段是时间字段,数据量大的表可以按照小时进行分区,数据量小的表可以按照天或者月进行分区。查询时使用分区字段作为 Where 语句条件,可以有效过滤掉大量非结果集数据。
一个分片本身就是 ClickHouse 的一个实例节点。分片的本质是提高查询效率,将一份全量的数据分成多份(片)能够降低单节点的数据扫描数量,提高查询性能。
在逻辑构成上,一个 ClickHouse 集群可以包含多个数据库对象。
MergeTree 引擎是 ClickHouse 中最有特色,也是功能最强大的表引擎,实现了数据的分区、副本、突变、合并。我们在这里主要以使用 MergeTree 引擎为例,讲解数据表的组织和存储形式,以及内容。
数据表的目录组成可用如下树型结构表示:
在 ClickHouse 中,一个典型的数据表在文件系统中的目录结构如下图所示:
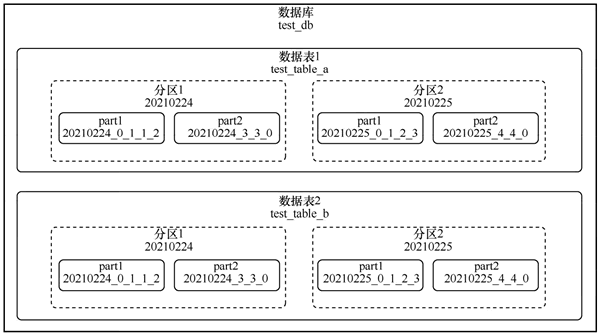
图 2 数据表的目录结构
数据库、数据表、分区都是按文件目录组织起来的,每个数据库会有对应的库目录,库中的每个表也会有各自对应的表目录。
每张表会包含若干个分区,这里的分区是一个逻辑概念,并不像数据表那样有目录与自己一一对应。在目录形式上,分区实际是一系列 Part(分区)的集合。每张表至少会有一个分区,如果不进行分区配置,则默认是一个全分区。
我们不再深入介绍 Part 的内容,对此有兴趣的读者可以自行查阅相关资料。
数据库的创建有以下两种情况:
第一种情况,使用默认引擎创建数据库的语法结构如下:
例如,创建 myDB 数据库,代码如下:
第二种情况,使用其他引擎创建数据库的语法结构如下:
这条语句会在 ClickHouse 中创建一个数据库,该数据库是其他引擎已存在的数据库的映射。我们可以对这个数据库执行 select 和 insert 命令,并把操作结果同步到指定引擎数据库。
例如,MySQL 中已存在一个名为 myMySQLDB 的数据库,我们使用以下代码在ClickHouse中创建数据库 myDB,并将该数据库映射到 myMySQLDB 上:
例如,使用 MergeTree 引擎创建工厂商品数据表 product,代码如下:
ClickHouse 的语法结构如下:
例如,在工厂商品数据表 product 中插入多条数据,代码如下:
例如,查询工厂商品数据表 product 的数据,代码如下:
ClickHouse 修改数据的语法结构如下:
例如,将工厂商品数据表 prodcut 中 shop_id 为 2 的 shop_name 修改为店铺 3 号,代码如下:
ClickHouse 的语法结构如下:
需要注意的是,清空一张表的数据必须要加集群的名字,具体语法结构如下:
ClickHouse 具有 ROLAP、在线实时查询、完整的数据库管理系统、列式存储、不需要任何数据预处理、支持批量更新、拥有非常完善的 SQL 支持和函数、支持高可用、不依赖 Hadoop 复杂生态、开箱即用等许多特点,因此非常适用于 BI 领域。同时,ClickHouse 也广泛应用于电信、金融、信息安全、物联网等领域。
在采集数据的过程中,Click(点击)一次页面会产生一个 Event(事件)。这个过程可以理解为基于页面的点击事件(流),面向数据仓库进行 OLAP 分析,因此 ClickHouse 的全称是 Click Stream,Data WareHouse。
下图展示了 ClickHouse 名称的含义:
图 1 ClickHouse 名称的含义
ClickHouse基础内容
下面介绍 ClickHouse 中涉及的一些基本名词,以便于读者能够更好地理解 ClickHouse。1) 表引擎
表引擎即表的类型,它是 ClickHouse 的核心概念,决定了:- 数据的存储方式和位置,写到哪里以及从哪里读取数据;
- 支持哪些查询以及如何支持;
- 并发访问数据;
- 索引的使用(如果存在);
- 是否可以执行多线程请求。
2) 数据库
数据库是 ClickHouse 集群中的最高级别对象,内部包含表、列、视图、函数、数据类型等。3) 表
表是数据的组织形式,由行和列构成。ClickHouse 的表从数据分布上来看,可以分为本地表和分布式表两种类型;从存储引擎上来看,可以分为单机表和复制表两种类型。
4) 表分区
表中的数据可以按照指定的字段进行分区存储,每个分区在文件系统中以目录的形式存在。常用的分区字段是时间字段,数据量大的表可以按照小时进行分区,数据量小的表可以按照天或者月进行分区。查询时使用分区字段作为 Where 语句条件,可以有效过滤掉大量非结果集数据。
5) 分片
在超大规模数据的处理场景下,单台服务器的存储、计算资源会成为性能瓶颈。为了进一步提高效率,ClickHouse 将海量数据分散存储到多台服务器上,每台服务器只存储和处理海量数据的一部分。在这种架构下,每台服务器称为一个分片。一个分片本身就是 ClickHouse 的一个实例节点。分片的本质是提高查询效率,将一份全量的数据分成多份(片)能够降低单节点的数据扫描数量,提高查询性能。
6) 副本
为了在异常情况下保证数据的安全性和服务的高可用性,ClickHouse 提供了副本机制,将单台服务器的数据冗余地存储在2台或更多台服务器上。7) 集群
在物理构成上,ClickHouse 集群是由多个 ClickHouse Server 实例组成的分布式数据库。这些 ClickHouse Server 根据购买规格的不同,可能包含 1 个或多个副本、1 个或多个分片。在逻辑构成上,一个 ClickHouse 集群可以包含多个数据库对象。
ClickHouse数据表定义
ClickHouse 中有众多表引擎,不同的表引擎在底层数据存储上千差万别,在功能和性能上各有侧重。但实际生产中,使用最广泛的表引擎就是 MergeTree 引擎。MergeTree 引擎是 ClickHouse 中最有特色,也是功能最强大的表引擎,实现了数据的分区、副本、突变、合并。我们在这里主要以使用 MergeTree 引擎为例,讲解数据表的组织和存储形式,以及内容。
数据表的目录组成可用如下树型结构表示:
clickhouse
└─ test_db
├─ test_table_a
│ ├─ 20210224_0_1_1_2
│ ├─ 20210224_3_3_0
│ ├─ 20210225_0_1_2_3
│ └─ 20210225_4_4_0
└─ test_table_b
├─ 20210224_0_1_1_2
├─ 20210224_3_3_0
├─ 20210225_0_1_2_3
└─ 20210225_4_4_0
在 ClickHouse 中,一个典型的数据表在文件系统中的目录结构如下图所示:
图 2 数据表的目录结构
数据库、数据表、分区都是按文件目录组织起来的,每个数据库会有对应的库目录,库中的每个表也会有各自对应的表目录。
每张表会包含若干个分区,这里的分区是一个逻辑概念,并不像数据表那样有目录与自己一一对应。在目录形式上,分区实际是一系列 Part(分区)的集合。每张表至少会有一个分区,如果不进行分区配置,则默认是一个全分区。
我们不再深入介绍 Part 的内容,对此有兴趣的读者可以自行查阅相关资料。
ClickHouse基本操作
1) 创建数据库
ClickHouse 可以通过指定表引擎的方式来创建数据库。在默认情况下,ClickHouse 使用的是原生的数据库引擎 Ordinary,当然也可以使用其他引擎,比如 MySQL 引擎。数据库的创建有以下两种情况:
第一种情况,使用默认引擎创建数据库的语法结构如下:
CREATE database [if not exists] < database-name >;语法结构中的 database-name 表示数据库名称。
例如,创建 myDB 数据库,代码如下:
CREATE database if not exists myDB;
第二种情况,使用其他引擎创建数据库的语法结构如下:
CREATE DATABASE [IF NOT EXISTS] < database-name > [ON CLUSTER< cluster-name >] [ENGINE = engine(...)]
- <cluster-name> 表示 ClickHouse 集群的名称;
- ENGINE 关键字用于指定使用的引擎。
这条语句会在 ClickHouse 中创建一个数据库,该数据库是其他引擎已存在的数据库的映射。我们可以对这个数据库执行 select 和 insert 命令,并把操作结果同步到指定引擎数据库。
例如,MySQL 中已存在一个名为 myMySQLDB 的数据库,我们使用以下代码在ClickHouse中创建数据库 myDB,并将该数据库映射到 myMySQLDB 上:
CREATE database if not exists myDB ENGINE = MySQL('127.0.0.1:3306',
'myMy SQLDB', 'root', '123456');
2) 删除数据库
删除数据库的语法结构与 SQL 语法结构基本相同,具体如下:DROP database < database-name >;例如,删除创建的 myDB 数据库,代码如下:
DROP database myDB;
3) 创建数据表
与创建数据库不同,创建数据表必须指定引擎,否则系统会报错,其语法结构如下:
CREATE table < table-name > (
< field-name > type [COMMENT ...],
...
) ENGINE = (...)
[option]
- table-name 表示创建的数据表的表名;
- field-name 表示数据表中所包含字段的字段名;
- type 表示字段对应的数据类型;
- COMMENT 用于说明当前字段的含义;
- ENGINE 用于指定创建数据表时使用的表引擎;
- option 选项表示创建表时的其他操作。
例如,使用 MergeTree 引擎创建工厂商品数据表 product,代码如下:
CREATE table product (
factory_goods_id UInt32 COMMENT ’工厂商品编号’,
goods_name String COMMENT ’商品名称’,
shop_id UInt32 COMMENT ’店铺编号’,
shop_name String COMMENT ’店铺名称’,
create_time DateTime COMMENT ’创建时间’,
update_time DateTime COMMENT ’更新时间’
) ENGINE = MergeTree()
PRIMARY KEY factory_goods_id
ORDER BY factory_goods_id;
4) 删除数据表
删除数据表的语法结构与 SQL 语法结构基本相同,具体如下:DROP table if exists < table-name >;例如,删除创建的工厂商品数据表 product,代码如下:
DROP table if exists product;如果 ClickHouse 是在集群上部署的,那么删除数据表应该带着集群的名称。例如,删除 factoryCluster 集群上的工厂商品数据表 product,代码如下:
DROP table product on CLUSTER elune;
5) 插入数据
插入数据的语法结构与SQL语法结构相似,二者不同之处主要体现在 ClickHouse 可以进行字段的批量插入。ClickHouse 的语法结构如下:
INSERT into [database-name.]< table-name > [(< field-name >, …)] VALUES (<value>, …), (<value>, …), …;可以看到,VALUES 关键字后面可以跟多组数据,这说明 ClickHouse 的插入数据可以用于批量插入数据。
例如,在工厂商品数据表 product 中插入多条数据,代码如下:
INSERT into product(factory_goods_id, goods_name, shop_id, shop_name,
create_time, update_time)
values(1, ’商品1号’, 1, ’店铺1号’, '2023-07-06', '2023-07-07'),
(2, ’商品2号’, 2, ’店铺2号’, '2023-07-06', '2023-07-07'),
(3, ’商品3号’, 1, ’店铺3号’, '2023-07-06', '2023-07-07');
6) 查询数据
查询数据的语法结构与 SQL 语法结构基本相同,具体如下:SELECT < field-name >, ...FROM < table-name > [where < condition >];condition 表示查询条件。
例如,查询工厂商品数据表 product 的数据,代码如下:
SELECT factory_goods_id, goods_name, shop_id, shop_name, create_time, update_time FROM product;另外,在查询过程中,如分组、排序、聚合函数甚至表连接的语法结构都与 SQL 对应的语法结构相似,此处不再赘述。感兴趣的读者可以自行查阅相关资料。
7) 修改数据
修改数据的语法结构与 SQL 语法结构略有不同,可以简单地理解为 ClickHouse 将 SQL 中 DDL 的修改与 DML 的修改合二为一。ClickHouse 修改数据的语法结构如下:
ALTER table < table_name > UPDATE field = value, … WHERE < condition >;
例如,将工厂商品数据表 prodcut 中 shop_id 为 2 的 shop_name 修改为店铺 3 号,代码如下:
ALTER table product UPDATE shop_name = ’店铺3号’ WHERE shop_id = 2;
8) 删除数据
删除数据的语法结构与 SQL 语法结构略有不同,可以简单地理解为 ClickHouse 将 SQL 中 DDL 的修改与 DML 的删除合二为一。ClickHouse 的语法结构如下:
ALTER table < table_name > DELETE WHERE < condition >;例如,删除工厂商品数据表 prodcut 中 factory_goods_id 为 3 的记录,代码如下:
ALTER table product DELETE WHERE factory_goods_id = 3;
需要注意的是,清空一张表的数据必须要加集群的名字,具体语法结构如下:
TRUNCATE table < table-name > on CLUSTER < cluster-name >;例如,清空 factoryCluster 集群中的工厂商品数据表 prodcut 的数据,代码如下:
TRUNCATE table product on CLUSTER factoryCluster;