分布式数据库详解(新手必看)
大数据需要通过分布式的集群方式来解决存储和访问的问题。本小节将从分布式的角度来介绍数据库的数据管理。
分布式系统的核心理念是让多台服务器协同工作,完成单台服务器无法处理的任务,尤其是高并发或者数据量大的任务。
分布式数据库是数据库技术与网络技术相结合的产物,通过网络技术将物理上分开的数据库连接在一起,实现逻辑层上的集中管理。在分布式系统中,一个应用程序可以对数据库进行透明操作,数据库中的数据被存储在不同场地的数据库中,由不同机器上的数据库管理系统进行管理。
分布式数据库的体系结构如下图所示,其中,R 表示一个逻辑上的整体(对外展示的分布式数据库),S 表示一个具体的场地(如 S1 可以理解为一台服务器)。
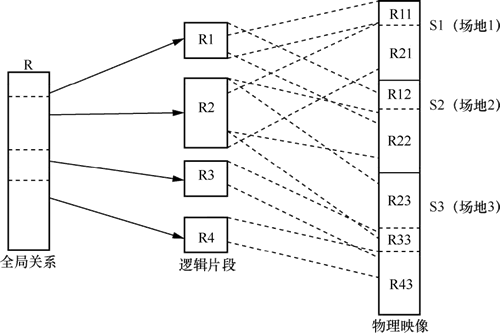
图 1 分布式数据库的体系结构
在关系数据库发展的早期阶段,这两个功能其实不难实现,而且出现了很多优秀的商业关系数据库产品,如 Oracle、DB2。
在 1990 年之后,开源数据库 MySQL 和 PostgreSQL 出现了。这些数据库不断地提升单机实例性能,再加上遵循摩尔定律的硬件性能提升规律,往往能够很好地支撑业务发展。
随着互联网的不断普及,特别是移动互联网的兴起,数据规模呈爆炸式增长,而硬件性能的提升速度却不如以前,人们开始担心摩尔定律会失效。在这种情况下,单机数据库越来越难以满足用户需求,即使是将数据保存下来这个最基本的需求也无法满足。
2005 年左右,人们开始探索分布式数据库,掀起了 NoSQL 数据库这波浪潮。分布式数据库首先要解决的问题是单机上无法保存全部数据,以 HBase、Cassandra、MongoDB 为代表的分布式数据库很好地解决了这个问题。为了实现容量的水平扩展,这些数据库往往要放弃事务,或者是只提供简单的 K-V 接口。存储模型的简化为存储系统的开发带来了便利,但是降低了对业务的支撑水平。
用户访问数据时无须指出数据存储在哪里,也无须知道由分布式系统中的哪台服务器来完成相关操作。
这种多副本的方式对于用户来说是透明的,即不需要用户知道副本的存在,而是由系统进行副本的统一管理、协调和调用。
但是,在分布式系统中,事务是并发的,即不同用户可能在同一时间对同一数据源进行访问,这要求系统支持分布式的并发控制,并能保证系统中数据的一致性。
分布式系统可以解决海量数据的存储和访问问题,但是在分布式环境下,数据库会遇到更为复杂的问题,举例如下:
上述问题给分布式数据库管理系统的设计与开发带来了挑战,也是分布式系统固有的复杂性的体现。相对于分布式数据库管理系统的设计与开发,对分布数据的管理、控制数据之间的一致性以及数据访问的安全性更为重要。
NoSQL 数据库的分类和特点如下表所示,具体如下:
从下图中可以看出,列族数据库中的每一行是它们的特点是指向了多个列:
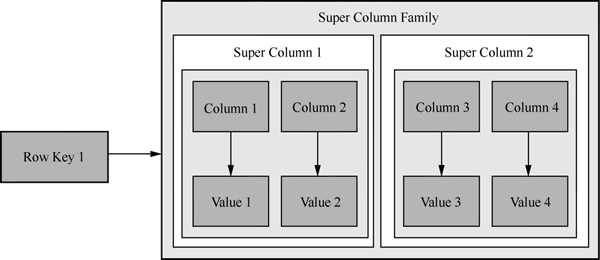
图 2 列族数据库示例
从图 2 中可以看出,列族数据库中的每一行都有关键字 Row Key,并由多个列族组成,即 Super Column Family 中的 Super Column 1 和 Super Column 2。每个列族由多个列组成。
文档数据库可以看作键值数据库的升级版,允许键值之间嵌套键值,如下图所示:
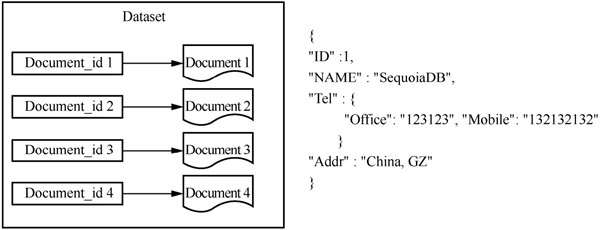
图 3 文档数据库示例
文档数据库比键值数据库的查询效率更高,因为文档数据库不仅可以根据键创建索引,同时还可以根据文档内容创建索引。
对于信息系统来说,键值模型的优势在于简单、易部署。键值数据库可以按照键对数据进行定位,还可以通过对键进行排序和分区来实现更快速的数据定位。
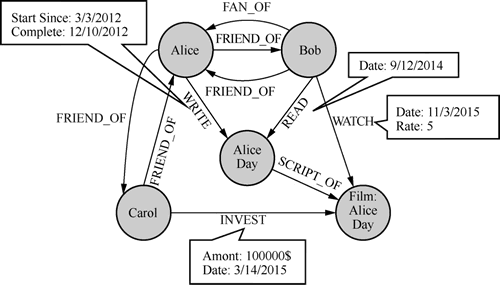
图 4 图数据库示例
这种拓扑结构类似实体联系图(Entity Relationship Diagram, E-R 图),在图形模式中,关系和节点本身就是数据。而在 E-R 图中,关系描述的是一种结构。
分布式系统的核心理念是让多台服务器协同工作,完成单台服务器无法处理的任务,尤其是高并发或者数据量大的任务。
分布式数据库是数据库技术与网络技术相结合的产物,通过网络技术将物理上分开的数据库连接在一起,实现逻辑层上的集中管理。在分布式系统中,一个应用程序可以对数据库进行透明操作,数据库中的数据被存储在不同场地的数据库中,由不同机器上的数据库管理系统进行管理。
分布式数据库的体系结构如下图所示,其中,R 表示一个逻辑上的整体(对外展示的分布式数据库),S 表示一个具体的场地(如 S1 可以理解为一台服务器)。
图 1 分布式数据库的体系结构
分布式数据库的发展
关系数据库起源于 1970 年代,其基本功能主要有两个:- 把数据存储下来;
- 满足用户对数据的计算需求。
在关系数据库发展的早期阶段,这两个功能其实不难实现,而且出现了很多优秀的商业关系数据库产品,如 Oracle、DB2。
在 1990 年之后,开源数据库 MySQL 和 PostgreSQL 出现了。这些数据库不断地提升单机实例性能,再加上遵循摩尔定律的硬件性能提升规律,往往能够很好地支撑业务发展。
随着互联网的不断普及,特别是移动互联网的兴起,数据规模呈爆炸式增长,而硬件性能的提升速度却不如以前,人们开始担心摩尔定律会失效。在这种情况下,单机数据库越来越难以满足用户需求,即使是将数据保存下来这个最基本的需求也无法满足。
2005 年左右,人们开始探索分布式数据库,掀起了 NoSQL 数据库这波浪潮。分布式数据库首先要解决的问题是单机上无法保存全部数据,以 HBase、Cassandra、MongoDB 为代表的分布式数据库很好地解决了这个问题。为了实现容量的水平扩展,这些数据库往往要放弃事务,或者是只提供简单的 K-V 接口。存储模型的简化为存储系统的开发带来了便利,但是降低了对业务的支撑水平。
分布式数据库的数据管理
分布式数据库处理使用分而治之的办法来解决大规模数据的管理问题,这种方式有以下几个特点。1) 数据分布的透明管理
在分布式系统中,数据不是存储在同一个场地上,而是存储在计算机网络所覆盖的多个场地上。这些数据在逻辑上是一个整体,被所有用户共享,并由一个数据库管理系统统一管理。用户访问数据时无须指出数据存储在哪里,也无须知道由分布式系统中的哪台服务器来完成相关操作。
2) 复制数据的透明管理
分布式数据库中数据的复制有助于提高性能,易于协调不同而又冲突的用户需求。同时,当某台服务器出现故障时,此服务器上的数据在其他服务器上还有备份,从而提高了系统的可用性。这种多副本的方式对于用户来说是透明的,即不需要用户知道副本的存在,而是由系统进行副本的统一管理、协调和调用。
3) 事务的可靠性
分布式数据处理具有冗余性,因而消除了单点故障的隐患,即系统中一台或多台服务器发生的故障不会使整个系统瘫痪,这提高了系统的可靠性。但是,在分布式系统中,事务是并发的,即不同用户可能在同一时间对同一数据源进行访问,这要求系统支持分布式的并发控制,并能保证系统中数据的一致性。
分布式系统可以解决海量数据的存储和访问问题,但是在分布式环境下,数据库会遇到更为复杂的问题,举例如下:
- 数据在分布式环境下以多个副本的方式进行存储,那么在为用户提供数据访问时,系统如何选择一个副本,或者当用户修改了某一副本的数据时,系统中的其他副本如何得到更新?
- 如果所有副本信息正在更新,某台服务器因网络或硬/软件功能出现问题而发生故障,那么在这种情况下,当故障恢复时,如何确保此服务器上的副本与其他副本一致?
上述问题给分布式数据库管理系统的设计与开发带来了挑战,也是分布式系统固有的复杂性的体现。相对于分布式数据库管理系统的设计与开发,对分布数据的管理、控制数据之间的一致性以及数据访问的安全性更为重要。
分布式数据库的分类
NoSQL 数据库并没有统一的模型,常见的包括键值数据库、列族数据库、文档数据库和图数据库。NoSQL 数据库的分类和特点如下表所示,具体如下:
| 分类 | 相关产品 | 应用场景 | 数据模型 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 列族数据库 | BigTable、HBase、Cassandra | 分布式数据存储与管理 | 采用列族式存储,将同一列数据存储在一起 | 可扩展性强,查找速度快,复杂性低 | 功能局限,不支持事务的强一致性 |
| 文档数据库 | MongoDB、CouchDB | Web 应用,存储面向文档或类似半结构化的数据 | <key, value>,其中 value 表示 JSON 结构的文档 | 数据结构灵活,可以根据 value 来构建索引 | 缺乏统一的查询语法 |
| 键值数据库 | Redis、Memcached、Riak | 缓存内容,如会话、配置文件、参数等;频繁读/写,拥有简单数据模型的应用 | <key, value>,通过散列表来实现 | 扩展性好,灵活性好,大量操作时性能高 | 数据无结构化,通常只被当作字符串或者二进制数据,只能通过键来查询值 |
| 图数据库 | Neo4j、InfoGrid | 社交网络、推荐系统,专注于构建关系图谱 | 图结构 | 支持复杂的图形算法 | 复杂性高,只能支持一定的数据规模 |
1) 列族数据库
列族数据库通常用于分布式存储所对应的海量数据。键(Key)仍然存在,但是它们的特点是指向了多个列。从下图中可以看出,列族数据库中的每一行是它们的特点是指向了多个列:
图 2 列族数据库示例
从图 2 中可以看出,列族数据库中的每一行都有关键字 Row Key,并由多个列族组成,即 Super Column Family 中的 Super Column 1 和 Super Column 2。每个列族由多个列组成。
2) 文档数据库
文档数据库的灵感来自 Lotus Notes 办公软件,它与键值数据库类似。该类型的数据模型是版本化的文档,文档以特定的格式(如 JSON)存储。文档数据库可以看作键值数据库的升级版,允许键值之间嵌套键值,如下图所示:
图 3 文档数据库示例
文档数据库比键值数据库的查询效率更高,因为文档数据库不仅可以根据键创建索引,同时还可以根据文档内容创建索引。
3) 键值数据库
这一类数据库主要使用散列表,该表中有一个特定的键和一个指针指向特定的数据。对于信息系统来说,键值模型的优势在于简单、易部署。键值数据库可以按照键对数据进行定位,还可以通过对键进行排序和分区来实现更快速的数据定位。
4) 图数据库
图数据库来源于图论中的拓扑学,通过节点、边及节点之间的关系来存储复杂网络中的数据,如下图所示:图 4 图数据库示例
这种拓扑结构类似实体联系图(Entity Relationship Diagram, E-R 图),在图形模式中,关系和节点本身就是数据。而在 E-R 图中,关系描述的是一种结构。