Java Set集合的用法(非常详细)
在 Java 集合框架中,Set 集合与 List 集合有显著的区别,Set 集合存储的数据默认是无序并且不重复的,它的常用实现类有 HashSet 和 TreeSet,本节将详细讲解 Set 接口的使用。
Set 集合继承自 Collection,它对 Collection 没有做额外的扩展。Set 集合中的元素具有无序、不能重复的特点。另外,Set 集合可以存储 null 值。
Set 接口的主要实现类是 HashSet 和 TreeSet,它们存储的元素都是不能重复的:
HashSet使用哈希算法来存储元素,因此存储和查找效率比较高。HashSet 存储元素时不能保证元素的顺序,也就是存储次序和显示次序会不一致,并且在多线程场景下使用不太安全。
HashSet 在添加元素时,会调用元素对象的 hashCode() 方法得到该对象的哈希值,然后通过这个哈希值来决定该对象在集合中的存储位置:
HashSet 添加元素的过程如下图所示:
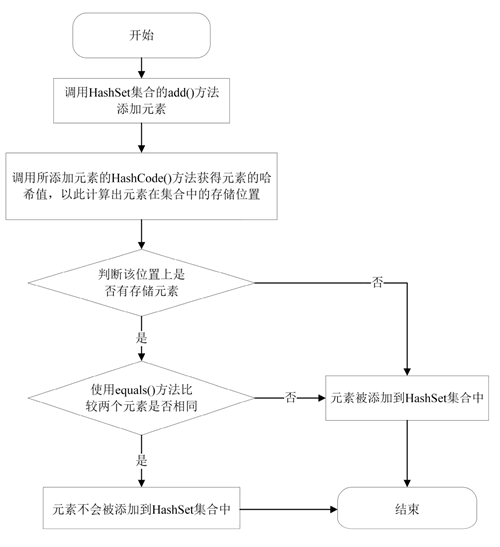
图 1 HashSet集合添加元素过程
接下来,通过案例来演示 HashSet 集合的使用:
但是,如果反复运行多次,会发现结果仍然不变,说明 HashSet 集合的存储也并不是随机的。另外,本例存入了两个“保时捷”,而运行结果中只有一个“保时捷”,说明 HashSet 的元素是不可重复的。
接下来,通过案例来演示在 HashSet 中存入没有重写 hashCode() 和 equals() 方法的对象时会有什么结果:
接下来,在 Car 类中重写 hashCode() 和 equals() 方法,来解决上面实例中出现的问题:
二叉树结构是指每个节点元素最多有两个子节点的有序树。在整个二叉树结构中,每个节点和其子节点构成一个子树,其中左边的子节点被称为“左子树”,右边的子节点被称为“右子树”,节点本身被称为“根节点”。
另外,使用二叉树存储数据时,要确保左子树的元素值小于根节点而右子树的元素值大于根节点。如下图所示,给出了二叉树的结构示意。
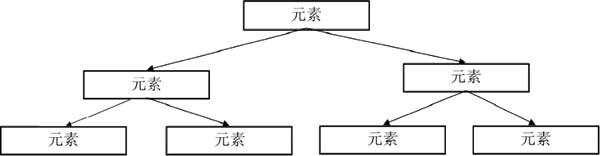
图 2 二叉树结构
根据图 2 所示,当使用二叉树存储一个新元素时,会首先与二叉树结构中的第 1 个元素(整个二叉树的根元素)比较大小:
对于 TreeSet 集合而言,如果新添加的数据和已有的数据重复,则不会再次添加。
为了便于读者更加直观地理解二叉树的使用,我们列举一个示例。例如,现在要存储这样一组数据:25、12、37、7、15、30、42、30,其最终的存储结果如下图所示。
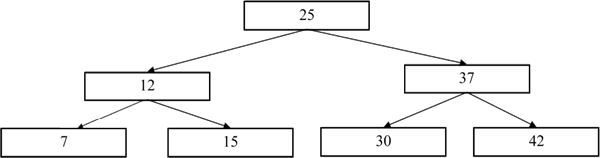
图 3 二叉树示例
图 3 中,按照次序将数据存入二叉树时:
以此类推,后续要存入的数据都会先与各个子树的根节点比较大小,从而决定存入左子树还是右子树。另外,在存储 30 这个数据时,第 1 次被存储之后,再次存入时因为重复会被排除掉。根据二叉树的这种存储规则,TreeSet 集合实现了数据有序并且不重复的效果。
这里给出 TreeSet 的一些特有的常用方法,如下表所示:
接下来,通过案例来演示 TreeSet 集合常用方法的具体使用:
TreeSet 有两种排序方法:自然排序和定制排序,其中自然排序是默认的排序规则,下面来讲解这两种不同的排序方式。
TreeSet 添加元素时,会调用要添加元素的 compareTo(Object obj) 方法和集合中的元素比较大小,根据比较结果将元素按升序排序,这就是自然排序。
在使用 TreeSet 集合时,添加的元素必须实现 Comparable 接口,否则程序会抛出 ClassCastException 异常。接下来,通过案例来演示这种情况:
此外,在向 TreeSet 集合中添加元素的时候,应该确保添加的元素都是同一个类型的对象,否则也会报 ClassCastException 异常:
接下来,修改上面实例的代码,使程序正确运行:
Java 中的 Comparator 接口定义了一个 compare(T t1,T t2) 方法,该方法能够实现 t1 和 t2 的大小比较:
如果要 TreeSet 集合使用定制排序方式为元素排序,只需在创建 TreeSet 集合时,为 TreeSet 集合提供一个实现了 Comparator 接口的比较器对象,并在比较器对象实现的 compare() 方法中编写排序逻辑。
接下来,通过案例来演示定制排序的具体使用:
Set 集合继承自 Collection,它对 Collection 没有做额外的扩展。Set 集合中的元素具有无序、不能重复的特点。另外,Set 集合可以存储 null 值。
Set 接口的主要实现类是 HashSet 和 TreeSet,它们存储的元素都是不能重复的:
- HashSet 集合在存储元素时,会根据对象的哈希值将元素散列存放在集合中,这种方式可以实现高效存取。
- TreeSet可以对集合中的元素排序,它的底层是用二叉树来实现的。
Java HashSet集合
HashSet 是 Set 接口的典型实现类。在使用 Set 集合时,实现类一般都用 HashSet。HashSet使用哈希算法来存储元素,因此存储和查找效率比较高。HashSet 存储元素时不能保证元素的顺序,也就是存储次序和显示次序会不一致,并且在多线程场景下使用不太安全。
HashSet 在添加元素时,会调用元素对象的 hashCode() 方法得到该对象的哈希值,然后通过这个哈希值来决定该对象在集合中的存储位置:
- 如果该位置没有元素,那么说明该元素在集合中是唯一的,就可以直接存入集合中。
-
如果该位置上有元素,那么继续调用该元素的 equals() 方法和集合中相同位置上的元素进行比较:
- 如果 equals() 方法返回为真,则说明该元素在集合中重复了,不能添加到集合中;
- 否则,说明该元素也是唯一的,可以存入集合中,此时集合中同一个位置会存储两个元素。
HashSet 添加元素的过程如下图所示:
图 1 HashSet集合添加元素过程
接下来,通过案例来演示 HashSet 集合的使用:
import java.util.*;
public class Demo{
public static void main(String[] args) {
Set set = new HashSet(); // 创建HashSet对象
set.add("布加迪"); // 向集合中存储元素
set.add(null);
set.add("保时捷");
set.add("兰博基尼");
set.add("劳斯莱斯");
set.add("保时捷");
for (Object object : set) { // 遍历集合
System.out.println(object); // 打印集合中元素
}
}
}
程序的运行结果如下:
null
兰博基尼
布加迪
保时捷
劳斯莱斯
但是,如果反复运行多次,会发现结果仍然不变,说明 HashSet 集合的存储也并不是随机的。另外,本例存入了两个“保时捷”,而运行结果中只有一个“保时捷”,说明 HashSet 的元素是不可重复的。
接下来,通过案例来演示在 HashSet 中存入没有重写 hashCode() 和 equals() 方法的对象时会有什么结果:
import java.util.*;
public class Demo {
public static void main(String[] args) {
Set set = new HashSet(); // 创建HashSet对象
set.add(new Car("保时捷", 20000000)); // 向集合中存储元素
set.add(new Car("兰博基尼", 5000000));
set.add(new Car("兰博基尼", 50000000));
for (Object o : set) { // 遍历集合
System.out.println(o); // 打印集合中元素
}
}
}
class Car {
String brand;
int price;
public Car(String brand, int price) { // 构造方法
this.brand = brand;
this.price = price;
}
public String toString() {
return brand + " - " + price + "元";
}
}
程序的运行结果如下:
保时捷 - 2000000元
兰博基尼 - 5000000元
兰博基尼 - 5000000元
接下来,在 Car 类中重写 hashCode() 和 equals() 方法,来解决上面实例中出现的问题:
import java.util.*;
public class Demo {
public static void main(String[] args) {
Set set = new HashSet(); // 创建HashSet对象
set.add(new Car("保时捷", 2000000)); // 向集合中存储元素
set.add(new Car("兰博基尼", 5000000));
set.add(new Car("兰博基尼", 5000000));
for (Object o : set) { // 遍历集合
System.out.println(o); // 打印集合中元素
}
}
}
class Car {
String brand;
int price;
public Car(String brand, int price) { // 构造方法
this.brand = brand;
this.price = price;
}
public String toString() { // 重写toString()方法
return brand + " - " + price + "元";
}
public int hashCode() { // 重写hashCode()方法
return Objects.hash(brand, price);
}
public boolean equals(Object object) { // 重写equals()方法
if (this == object)
return true;
if (!(object instanceof Car))
return false;
Car car = (Car) object;
return price == car.price &&
Objects.equals(brand, car.brand); // 对比每个变量返回最后的结果
}
}
程序的运行结果如下:
保时捷 – 2000000元
兰博基尼 - 5000000元
Java TreeSet集合
Set 接口的另一个实现类是 TreeSet,TreeSet 集合中的元素也是不可重复的。TreeSet 底层是用自平衡的排序二叉树来实现的,所以 TreeSet 中的元素是可以进行排序的。二叉树结构是指每个节点元素最多有两个子节点的有序树。在整个二叉树结构中,每个节点和其子节点构成一个子树,其中左边的子节点被称为“左子树”,右边的子节点被称为“右子树”,节点本身被称为“根节点”。
另外,使用二叉树存储数据时,要确保左子树的元素值小于根节点而右子树的元素值大于根节点。如下图所示,给出了二叉树的结构示意。
图 2 二叉树结构
根据图 2 所示,当使用二叉树存储一个新元素时,会首先与二叉树结构中的第 1 个元素(整个二叉树的根元素)比较大小:
- 如果小于根元素,那么新添加的元素就会进入左边的分支,并且继续和左边分支中的子元素比较大小,直到找到一个合适的位置进行存储;
- 如果新加的元素大于第 1 个元素,则该元素会进入右边的分支,并且继续和右边分支中的子元素比较大小,直到找到一个合适的位置进行存储。
对于 TreeSet 集合而言,如果新添加的数据和已有的数据重复,则不会再次添加。
为了便于读者更加直观地理解二叉树的使用,我们列举一个示例。例如,现在要存储这样一组数据:25、12、37、7、15、30、42、30,其最终的存储结果如下图所示。
图 3 二叉树示例
图 3 中,按照次序将数据存入二叉树时:
- 第 1 个数据是 25,会被作为根节点存储在二叉树的最顶端;
- 存储第 2 个数据 12 时,因为它比根节点小,所以会被存入左子树;
- 第 3 个数据 37,因为比根节点大,所以会被存入右子树。
以此类推,后续要存入的数据都会先与各个子树的根节点比较大小,从而决定存入左子树还是右子树。另外,在存储 30 这个数据时,第 1 次被存储之后,再次存入时因为重复会被排除掉。根据二叉树的这种存储规则,TreeSet 集合实现了数据有序并且不重复的效果。
这里给出 TreeSet 的一些特有的常用方法,如下表所示:
| 方法 | 方法描述 |
|---|---|
| Comparator comparator() | 针对定制排序和自然排序,该方法会返回不同的结果。如果 TreeSet 使用定制排序,则返回定制排序所使用的 Comparator 比较器对象;如果 TreeSet 使用自然排序,则返回 null |
| Object first() | 获取集合中第 1 个元素 |
| Object last() | 获取集合中最后一个元素 |
| Object lower(Object o) | 获取集合中位于 o 之前的元素 |
| Object higher(Object o) | 获取集合中位于 o 之后的元素 |
| SortedSet subset(Object o1, Object o2) | 获取此 Set 的子集合,范围从 o1(包括)到 o2(不包括) |
| SortedSet headSet(Object o) | 获取此 Set 的子集合,范围小于元素 o |
| SortedSet tailSet(Object o) | 获取此 Set 的子集合,范围大于或等于元素 o |
接下来,通过案例来演示 TreeSet 集合常用方法的具体使用:
import java.util.*;
public class Demo {
public static void main(String[] args) {
TreeSet tree = new TreeSet(); // 创建TreeSet集合
tree.add(60); // 添加元素
tree.add(180);
tree.add(360);
tree.add(120);
tree.add(560);
System.out.println(tree); // 打印集合
System.out.println(tree.first()); // 打印集合中第1个元素
// 打印集合中大于等于100小于400的元素
System.out.println(tree.subSet(100, 400));
}
}
程序的运行结果如下:
[60, 120, 180, 360, 560]
60
[120, 180, 360]
TreeSet 有两种排序方法:自然排序和定制排序,其中自然排序是默认的排序规则,下面来讲解这两种不同的排序方式。
1) TreeSet自然排序
Java 提供了一个 Comparable 接口,在这个接口中定义了一个 compareTo(Object obj)方法。实现类实现了 Comparable 接口的这个方法,就可以进行大小比较。例如,o1.compareTo(o2),如果该方法返回一个正整数,则说明 o1 大于 o2;如果该方法返回一个负整数,则说明 o1 小于 o2;如果该方法返回 0,则说明 o1 和 o2 相等。Java 的很多常用类已经实现了 Comparable 接口,并实现了比较大小的方式,如基本类型的包装类都实现了此接口。
TreeSet 添加元素时,会调用要添加元素的 compareTo(Object obj) 方法和集合中的元素比较大小,根据比较结果将元素按升序排序,这就是自然排序。
在使用 TreeSet 集合时,添加的元素必须实现 Comparable 接口,否则程序会抛出 ClassCastException 异常。接下来,通过案例来演示这种情况:
import java.util.*;
class Car {
}
public class Demo {
public static void main(String[] args) {
TreeSet treeSet = new TreeSet(); // 创建TreeSet集合
treeSet.add(new Car()); // 向集合中添加元素
}
}
程序运行报错,提示“ClassCastException”,中文含义是“类型转换异常”,出错的原因是因为实例中的 Car 类并没有实现 Comparable 接口,导致 TreeSet 集合无法实现对象比较排序,因此报错。此外,在向 TreeSet 集合中添加元素的时候,应该确保添加的元素都是同一个类型的对象,否则也会报 ClassCastException 异常:
import java.util.*;
public class Demo {
public static void main(String[] args) {
TreeSet ts = new TreeSet(); // 创建TreeSet集合
ts.add(100); // 向集合中添加元素
ts.add("abc");
}
}
程序运行报错,提示“ClassCastException”,中文含义是“类型转换异常”,出错的原因是 Integer 类型不能转为 String 类型,也就是向 TreeSet 集合添加了不同类型的对象,所以导致错误。接下来,修改上面实例的代码,使程序正确运行:
import java.util.*;
public class Demo {
public static void main(String[] args) {
TreeSet treeSet = new TreeSet(); // 创建TreeSet集合
treeSet.add(new Car()); // 向集合中添加元素
treeSet.add(new Car());
System.out.println(treeSet); // 打印集合
}
}
class Car implements Comparable {
public int compareTo(Object o) { // 重写compareTo()方法
return 1; // 设置固定返回1(也可以写别的值)
}
}
程序的运行结果如下:
[Car@4d7e1886, Car@3cd1a2f1]
以上程序运行结果打印了集合中 2 个元素的地址值,说明添加元素成功。程序中 Car 类实现了 Comparable 接口,并且重写了 compareTo(Object o) 方法,所以添加成功。2) TreeSet定制排序
自然排序是根据集合元素的数值大小,默认按升序排序。但有些情况需要按特殊规则排序,比如降序排列,就需要用到定制排序。Java 中的 Comparator 接口定义了一个 compare(T t1,T t2) 方法,该方法能够实现 t1 和 t2 的大小比较:
- 若该方法比较结果返回正整数,则说明 t1 大于 t2;
- 若返回 0,则说明 t1 等于 t2;
- 若返回负整数,则说明 t1 小于 t2。
如果要 TreeSet 集合使用定制排序方式为元素排序,只需在创建 TreeSet 集合时,为 TreeSet 集合提供一个实现了 Comparator 接口的比较器对象,并在比较器对象实现的 compare() 方法中编写排序逻辑。
接下来,通过案例来演示定制排序的具体使用:
import java.util.*;
public class Demo {
public static void main(String[] args) {
// 创建TreeSet集合对象,提供一个实现了Comparator接口的比较器对象
TreeSet treeSet = new TreeSet(new MyComparator());
treeSet.add(new Car("布加迪", 1200000000));
treeSet.add(new Car("保时捷", 1100000));
treeSet.add(new Car("兰博基尼", 2100000));
System.out.println(treeSet);
}
}
class Car {
private String brand; // 定义Car
private Integer price;
public Car(String brand, Integer price) {
this.brand = brand;
this.price = price;
}
public String getBrand() {
return brand;
}
public void setBrand(String brand) {
this.brand = brand;
}
public Integer getPrice() {
return price;
}
public void setPrice(Integer price) {
this.price = price;
}
public String toString() {
return brand + " - " + price;
}
}
class MyComparator implements Comparator { // 实现Comparator
// 实现compare()方法
public int compare(Object o1, Object o2) {
if (o1 instanceof Car && o2 instanceof Car) {
Car c1 = (Car) o1;
Car c2 = (Car) o2;
if (c1.getPrice() > c2.getPrice()) {
return -1;
} else if (c1.getPrice() < c2.getPrice()) {
return 1;
}
}
return 0;
}
}
程序的运行结果如下:
[兰博基尼 - 2100000, 布加迪 - 1200000, 保时捷 - 1100000]
程序中,自定义类 MyComparator 实现了 Comparator 接口,在实现的接口方法 compare 中实现了降序排序规则,因此集合中的元素打印输出是以降序排列的。 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: