Pandas merge()的用法(附带实例)
Pandas 模块的 merge() 方法可将两个列名相同的列合并,两个 DataFrame 对象必须含有同名的列。
merge() 方法的语法格式如下:

图 1 数据合并效果示意图
程序代码如下:

图 2 合并结果
【实例】如果通过索引合并数据,则需要将 right_index 参数和 left_index 参数的值设置为 True。例如,对于上述示例,若通过索引合并数据,主要代码如下:
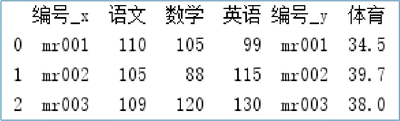
图 3 通过索引合并数据
【实例】从图 3 所示的运行结果得知,数据中存在重复列(如编号),如果不想要重复列可以通过 how 参数解决这一问题。例如,设置该参数值为 left,就是让 df1 保留所有的行列数据,df2 则根据 df1 的行列进行补全,主要代码如下:
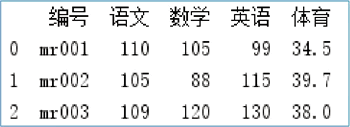
图 4 去重结果
例如,df1 中的“编号”是唯一的,而 df2 中的“编号”有重复的值,类似这种就是多对一的关系,示意图如下图所示:
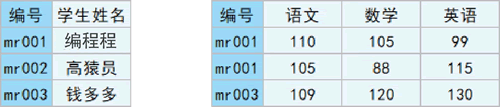
图 5 多对一合并示意图
【实例】根据共有列中的数据进行合并,df2 根据 df1 的行列进行补全,主要代码如下:

图 6 合并结果
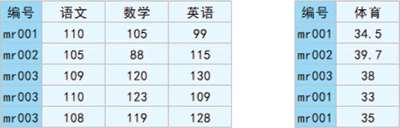
图 7 多对多示意图
【实例】根据共有列中的数据进行合并,df2、df1 相互补全,主要代码如下:
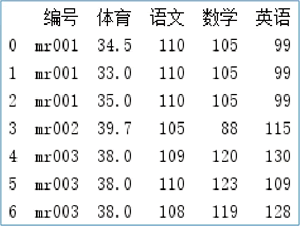
图 8 合并结果
merge() 方法的语法格式如下:
pandas.merge(right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
merge() 方法会返回 DataFrame 对象,两个合并对象的数据集。各个参数的含义如下表所示:| 参数 | 说明 |
|---|---|
| right | 合并对象,DataFrame 对象或 Series 对象。 |
| how |
合并类型,参数值可以是 left(左合并)、right(右合并)、outer(外部合并)或inner(内部合并),默认值为 inner。 各个值的说明如下: left:只使用来自左数据集的键,类似于 SQL 的左外部连接,保留键的顺序; right:只使用来自右数据集的键,类似于 SQL 的右外部连接,保留键的顺序; outer:使用来自两个数据集的键,类似于 SQL 的外部连接,按字典顺序对键进行排序; inner:使用来自两个数据集的键的交集,类似于 SQL 的内部连接,保留左键的顺序。 |
| on | 标签、列表或数组,默认值为 None。DataFrame 对象中要合并的列或索引级别名称,也可以是 DataFrame 对象长度的数组或数组列表。 |
| left_on | 标签、列表或数组,默认值为 None。要合并的左数据集的列或索引级名称,也可以是左数据集长度的数组或数组列表。 |
| right_on | 标签、列表或数组,默认值为 None。要合并的右数据集的列或索引级名称,也可以是右数据集长度的数组或数组列表。 |
| left_index | 布尔型,默认值为 False。使用左数据集的索引作为合并键。如果是多重索引,则其他数据中的键数(索引或列数)必须匹配索引的级数。 |
| right_index | 布尔型,默认值为 False,使用右数据集的索引作为合并键。 |
| sort | 布尔型,默认值为 False,在合并结果中按字典顺序对合并键进行排序。如果为 False,则合并键的顺序取决于连接类型how参数。 |
| suffixes | 元组类型,默认值为 _x 或 _y。当左侧数据集和右侧数据集的列名相同时,数据合并后列名将带上“_x”和“_y”后缀。 |
| copy | 是否复制数据,默认值为 True,如果为 False,则不复制数据。 |
| indicator | 布尔型或字符串,默认值为 False。如果值为 True,则添加一列,用来输出名为“_Merge”的 DataFrame 对象,其中包含每一行的信息。如果是字符串,则向输出的 DataFrame 对象中添加包含每一行信息的列,并将列命名为字符型的值。 |
| validate |
字符串,检查合并数据是否为指定类型。可选参数,其值说明如下:
|
Pandas merge()常规合并
假设一个 DataFrame 对象中包含学生的“语文”、“数学”和“英语”成绩,而另一个 DataFrame 对象中包含了学生的“体育”成绩,现在将它们合并,示意图如下图所示。图 1 数据合并效果示意图
程序代码如下:
# 导入pandas模块
import pandas as pd
# 解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
# 创建数据
df1 = pd.DataFrame({'编号':['mr001','mr002','mr003'],
'语文':[110,105,109],
'数学':[105,88,120],
'英语':[99,115,130]})
df2 = pd.DataFrame({'编号':['mr001','mr002','mr003'],
'体育':[34.5,39.7,38]})
# 数据合并
df_merge=pd.merge(df1,df2,on='编号')
print(df_merge)
运行程序,结果如下图所示:图 2 合并结果
【实例】如果通过索引合并数据,则需要将 right_index 参数和 left_index 参数的值设置为 True。例如,对于上述示例,若通过索引合并数据,主要代码如下:
df_merge = pd.merge(df1, df2, right_index=True, left_index=True) print(df_merge)运行程序,结果如下图所示:
图 3 通过索引合并数据
【实例】从图 3 所示的运行结果得知,数据中存在重复列(如编号),如果不想要重复列可以通过 how 参数解决这一问题。例如,设置该参数值为 left,就是让 df1 保留所有的行列数据,df2 则根据 df1 的行列进行补全,主要代码如下:
df_merge = pd.merge(df1, df2, on='编号', how='left')运行程序,结果如下图所示:
图 4 去重结果
Pandas merge()多对一的数据合并
多对一是指两个数据集(df1、df2)的共有列中的数据不是一对一的关系。例如,df1 中的“编号”是唯一的,而 df2 中的“编号”有重复的值,类似这种就是多对一的关系,示意图如下图所示:
图 5 多对一合并示意图
【实例】根据共有列中的数据进行合并,df2 根据 df1 的行列进行补全,主要代码如下:
# 按编号列合并数据 df_merge = pd.merge(df1, df2, on='编号') print(df_merge)运行程序,结果如下图所示:
图 6 合并结果
Pandas merge()多对多的数据合并
多对多是指两个数据集(df1、df2)的共有列中的数据不全是一对一的关系,都有重复数据,示意图如下图所示。图 7 多对多示意图
【实例】根据共有列中的数据进行合并,df2、df1 相互补全,主要代码如下:
# 数据合并 df_merge = pd.merge(df1, df2) print(df_merge)运行程序,结果如下图所示:
图 8 合并结果
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: