Go语言通道详解(小白必读)
在任何编程语言中,只要存在并发就会出现数据和资源争夺的情况,比如程序执行了两个并发操作,每个并发都是对同一个文件进行读写处理,这样很容易出现文件数据异常。
假如并发 A 读取文件 A 之后,再由并发 B 读取和修改文件 A,此时文件 A 的数据已经发生变化,但是并发 A 读取的文件内容仍然是未修改之前的数据,只要并发 A 修改文件内容,最终并发 B 修改的内容将被并发A覆盖。
为了解决数据和资源的不同步,大多数编程语言都会为数据资源加上锁,每次并发的时候确保只有一个并发占用数据资源,从而确保数据资源的同步性。
Go 语言为了解决数据资源的同步问题,引入了通信机制——通道,它是 Go 语言中一种特殊的数据类型,为多个协程之间提供数据资源共享,如下图所示。
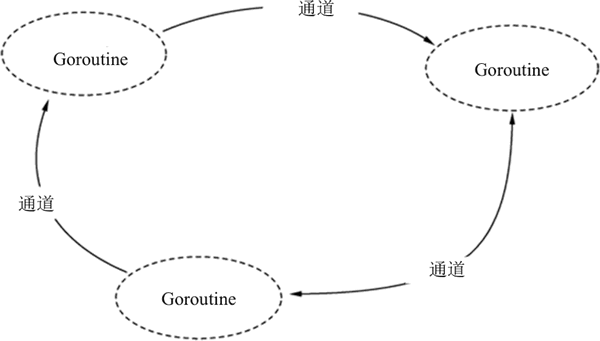
图 1 通道与协程
在并发过程中,多个协程为了争抢数据资源必然造成阻塞,降低了执行效率,为了保证执行效率,同一时刻只有一个协程访问通道进行写入和读取数据,协程之间也能实现数据通信。通道遵循先入先出(First In First Out)的原则,保证收发数据的顺序。
通道是一个特殊的数据类型,在使用之前必须定义和创建通道变量,定义通道的语法如下:
通道定义之后,还需要使用关键字 make 创建通道,通道的创建语法如下:
在实际编程中,我们直接使用关键字 make 创建通道即可使用,这样能省去定义通道的过程,示例代码如下:
关键字 make 创建通道默认为双向通道,双向通道可以执行写入和获取。此外,我们还可以定义单向通道,它只能写入数据,不能获取数据,或者只能获取数据,不能写入数据。单向通道的定义与创建如下:
单向通道只能执行特定的操作,比如只能写入不能获取的单向通道只能写入数据,如果获取数据将会提示异常:
无缓冲通道(Unbuffered Channel)是指在获取数据之前没有能力保存数据的通道,这种类型的通道要求两个协程同时处于执行状态才能完成写入和获取操作。
如果两个协程没有同时准备,某一个协程执行写入或获取操作将会处于阻塞等待状态,另一个协程无法执行写入或获取操作,程序将会提示异常,这种类型的通道执行写入和获取的交互行为是同步,任意一个操作都无法离开另一个操作单独存在。
当我们使用无缓冲通道的时候,必须注意通道变量的操作,确保程序中有两个或两个以上的协程同时执行通道的读写操作,读写操作必须是一读一写,不能只读不写或只写不读,示例如下:
如果程序中仅有一个协程,使用通道读写数据也会导致异常,比如在主函数 main() 中对通道写入数据,再读取通道数据,示例如下:
运行上述代码,运行结果如下图所示。
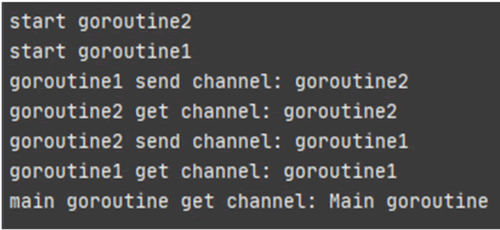
图 2 运行结果
综上所述,在并发编程中,使用无缓存通道必须考虑各个协程之间的数据读取和写入操作,必须遵从先写入后读取,再写入再读取的原则。
在无缓冲通道的基础上,只要为通道增加一个有限大小的存储空间就能形成带缓冲通道。带缓冲通道在写入时无须等待获取即可再次执行下一轮写入,并且不会发生阻塞,只有当存储空间满了才会发生阻塞。同理,如果带缓冲通道中有数据,获取时将不会发生阻塞,直到通道中没有数据可读时,通道才会阻塞。
从通道的定义角度分析,带缓冲和无缓冲通道的区别在于参数 num。创建通道的时候,如果没有设置参数num,则默认参数值为 0,通道为无缓冲通道,所以写入和获取数据必须同时进行才不会因阻塞而异常;如果参数 num 大于 0,则写入和获取数据无须同步执行,因为通道有足够的空间存放数据。
由于带缓冲通道没有读写同步限制,我们可以在同一个协程中执行多次写入和获取操作,具体示例如下:
带缓冲通道在很多特性上和无缓冲通道类似,无缓冲通道可以看作长度为 0 的带缓冲通道。根据这个特性,带缓冲通道在下列情况下会发生阻塞:
Go 语言为什么对通道要限制长度?因为多个协程之间使用通道必然存在写入和获取操作,这种模式类型的典型例子为生产者消费者模式。如果不限制通道长度,当写入数据速度大于获取速度,内存将不断膨胀直到应用崩溃。因此,限制通道的长度有利于约束数据生产速度,生产数据量必须在数据消费速度+通道长度的范围内,这样才能正常地处理数据。
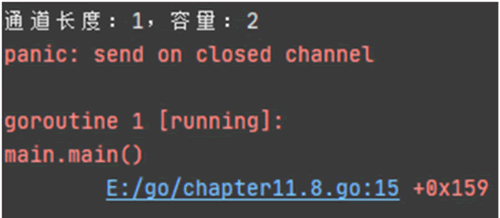
图 3 运行结果
从运行结果看到,使用 close() 关闭通道之后,如果再往通道里面写入数据,程序将提示异常,说明已关闭的通道是不支持数据写入操作的。但已关闭的通道支持数据获取操作,示例如下:
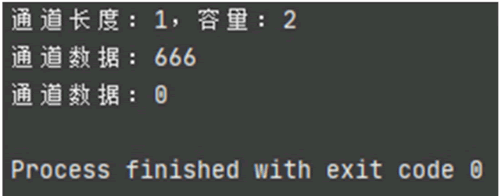
图 4 运行结果
示例代码说明如下:
综上所述,通过关闭通道的方式可以解决通道数据读取的阻塞问题,但此方式不适合数据写入,并且仅适用于带缓存通道。因为无缓冲通道只要写入数据必须在另一个并发中读取数据,否则提示异常,这个过程可视为同步,完全没必要关闭通道。
假如并发 A 读取文件 A 之后,再由并发 B 读取和修改文件 A,此时文件 A 的数据已经发生变化,但是并发 A 读取的文件内容仍然是未修改之前的数据,只要并发 A 修改文件内容,最终并发 B 修改的内容将被并发A覆盖。
为了解决数据和资源的不同步,大多数编程语言都会为数据资源加上锁,每次并发的时候确保只有一个并发占用数据资源,从而确保数据资源的同步性。
Go 语言为了解决数据资源的同步问题,引入了通信机制——通道,它是 Go 语言中一种特殊的数据类型,为多个协程之间提供数据资源共享,如下图所示。
图 1 通道与协程
在并发过程中,多个协程为了争抢数据资源必然造成阻塞,降低了执行效率,为了保证执行效率,同一时刻只有一个协程访问通道进行写入和读取数据,协程之间也能实现数据通信。通道遵循先入先出(First In First Out)的原则,保证收发数据的顺序。
通道是一个特殊的数据类型,在使用之前必须定义和创建通道变量,定义通道的语法如下:
var name chan type
语法格式说明如下:- var 是 Go 语言关键字,用于定义变量。
- name 是通道变量名称,可自行命名。
- chan 是 Go 语言关键字,将变量定义为通道类型。
- type 是通道存放的数据类型。
通道定义之后,还需要使用关键字 make 创建通道,通道的创建语法如下:
name := make(chan type, num)语法格式说明如下:
- name 是通道变量名称,可自行命名。
- make 是 Go 语言关键字,用于创建通道。
- chan type 的 chan 是 Go 语言关键字,type 是通道能存放的数据类型。
- num 是通道存放数据的数量上限。
在实际编程中,我们直接使用关键字 make 创建通道即可使用,这样能省去定义通道的过程,示例代码如下:
// 定义和创建通道 var ch chan string ch = make(chan string) // 直接创建通道,无须定义 ch := make(chan string)通道创建之后,使用通道完成写入和读取数据操作。在通道里面写入和读取数据需要由 <- 操作符实现,使用说明如下:
// 构建通道 ch := make(chan string) // 往通道写入数据 ch <- "Hello" // 从通道获取数据,赋予变量s s := <- ch从示例代码看到,在通道里面写入和读取数据的区别是通道变量在 <- 操作符的位置。如果通道变量在 <- 操作符的左边,说明是往通道里面写入数据;如果通道变量在 <- 操作符的右边,说明是读取通道里面的数据。
关键字 make 创建通道默认为双向通道,双向通道可以执行写入和获取。此外,我们还可以定义单向通道,它只能写入数据,不能获取数据,或者只能获取数据,不能写入数据。单向通道的定义与创建如下:
ch := make(chan int) // 定义只能写入不能获取的单向通道 var only_wirte chan<- int = ch // 定义只能获取不能写入的单向通道 var only_read <-chan int = ch // 对只能写入不能获取的单向通道写入数据 only_wirte <- 10 // 对只能写入不能获取的单向通道获取数据 <- only_wirte
单向通道只能执行特定的操作,比如只能写入不能获取的单向通道只能写入数据,如果获取数据将会提示异常:
invalid operation: <-only_wirte (receive from send-only type chan<- int)
单向通道在开发中有较大的局限性,应用场景也比较少,因此读者了解相关概念即可。无缓冲通道
通道是通过关键字 make 创建的,在创建过程中,如果没有设置参数 num,则视为创建无缓冲通道。无缓冲通道(Unbuffered Channel)是指在获取数据之前没有能力保存数据的通道,这种类型的通道要求两个协程同时处于执行状态才能完成写入和获取操作。
如果两个协程没有同时准备,某一个协程执行写入或获取操作将会处于阻塞等待状态,另一个协程无法执行写入或获取操作,程序将会提示异常,这种类型的通道执行写入和获取的交互行为是同步,任意一个操作都无法离开另一个操作单独存在。
当我们使用无缓冲通道的时候,必须注意通道变量的操作,确保程序中有两个或两个以上的协程同时执行通道的读写操作,读写操作必须是一读一写,不能只读不写或只写不读,示例如下:
// 只写入数据,不读取
ch := make(chan string)
ch <- "Tom"
fmt.Println("wait goroutine")
// 只读取数据,不写入
ch := make(chan string)
<- ch
fmt.Println("wait goroutine")
通道数据只写入不读取或者只读取不写入都会提示fatal error: all goroutines are asleep–deadlock异常,如果需要实现通道数据获取超时检测,可以使用关键字 select 实现。如果程序中仅有一个协程,使用通道读写数据也会导致异常,比如在主函数 main() 中对通道写入数据,再读取通道数据,示例如下:
package main
import (
"fmt"
)
func main() {
// 构建通道
ch := make(chan string)
// 写入通道数据
ch <- "Tom"
// 读取通道数据
<-ch
fmt.Println("wait goroutine")
}
根据无缓冲通道的语法特点,我们在程序中使用 3 个协程依次执行通道的读写操作,示例如下:
package main
import (
"fmt"
"time"
)
func Goroutine1(ch chan string){
fmt.Println("start goroutine1")
// 数据写入通道,由Goroutine2()读取
ch <- "goroutine2"
fmt.Println("goroutine1 send channel: goroutine2")
// 读取Goroutine2()写入的数据
data := <-ch
fmt.Printf("goroutine1 get channel: %v\n", data)
// 数据写入通道,由主函数main()读取
ch <- "Main goroutine"
}
func Goroutine2(ch chan string){
fmt.Println("start goroutine2")
// 读取Goroutine1()写入的数据
data := <-ch
fmt.Printf("goroutine2 get channel: %v\n", data)
// 数据写入通道,由Goroutine1()读取
ch <- "goroutine1"
fmt.Println("goroutine2 send channel: goroutine1")
}
func main() {
// 构建通道
ch := make(chan string)
// 执行并发
go Goroutine1(ch)
// 执行并发
go Goroutine2(ch)
// 延时5秒,使Goroutine1()和Goroutine2()相互读写通道数据
time.Sleep(5 * time.Second)
// 读取Goroutine1()写入的数据
data := <-ch
fmt.Printf("main goroutine get channel: %v\n", data)
}
上述代码定义了函数 Goroutine1() 和 Goroutine2(),函数参数为通道变量 ch,主函数 main() 分别对函数 Goroutine1() 和 Goroutine2() 执行并发操作,说明如下:
- 主函数 main() 创建通道变量ch,并对函数 Goroutine1() 和 Goroutine2() 执行并发操作,将通道变量 ch 分别以参数形式传入 Goroutine1() 和 Goroutine2()。
- 函数 Goroutine1() 往通道变量 ch 写入数据,再由函数 Goroutine2() 读取数据;然后到函数 Goroutine2() 写入数据,由函数 Goroutine1() 读取;最后 Goroutine1() 写入数据,由主函数 main() 读取。
- 主函数 main() 设置了等待5秒,这是为了让函数 Goroutine1() 和 Goroutine2() 有足够的时间写入和读取数据,过了等待时间后,再从通道变量读取数据。
运行上述代码,运行结果如下图所示。
图 2 运行结果
综上所述,在并发编程中,使用无缓存通道必须考虑各个协程之间的数据读取和写入操作,必须遵从先写入后读取,再写入再读取的原则。
带缓冲通道
带缓冲通道(Buffered Channel)是在被获取前能存储一个或者多个数据的通道,这种类型的通道并不强制要求协程之间必须同时完成写入和获取。当通道中没有数据的时候,获取动作才会阻塞;当通道没有可用缓冲区存储数据的时候,写入动作才会阻塞。在无缓冲通道的基础上,只要为通道增加一个有限大小的存储空间就能形成带缓冲通道。带缓冲通道在写入时无须等待获取即可再次执行下一轮写入,并且不会发生阻塞,只有当存储空间满了才会发生阻塞。同理,如果带缓冲通道中有数据,获取时将不会发生阻塞,直到通道中没有数据可读时,通道才会阻塞。
从通道的定义角度分析,带缓冲和无缓冲通道的区别在于参数 num。创建通道的时候,如果没有设置参数num,则默认参数值为 0,通道为无缓冲通道,所以写入和获取数据必须同时进行才不会因阻塞而异常;如果参数 num 大于 0,则写入和获取数据无须同步执行,因为通道有足够的空间存放数据。
由于带缓冲通道没有读写同步限制,我们可以在同一个协程中执行多次写入和获取操作,具体示例如下:
package main
import "fmt"
func main() {
// 创建一个3个元素缓冲大小的整型通道
ch := make(chan int, 3)
// 查看当前通道的大小
fmt.Println(len(ch))
// 发送3个整型元素到通道
for i := 0; i < 3; i++ {
ch <- i
}
// 查看当前通道的大小
fmt.Println(len(ch))
for i := 0; i < 3; i++ {
fmt.Println(<-ch)
}
// 查看当前通道的大小
fmt.Println(len(ch))
// 查看当前通道的容量
fmt.Println(cap(ch))
}
上述代码的说明如下:
- 通过 for 执行了 3 次循环,每次循环将变量 i 写入通道,然后通过 3 次循环从通道获取数据并输出。
- 通道写入和读取数据的时候,使用 len() 函数获取通道已有的数据量,判断当前通道存储的数据量是否达到上限,这样可以防止程序在运行时提示异常。
- 使用 cap() 函数能获取通道的容量大小,即获取创建通道 make() 的参数 num 的大小。
带缓冲通道在很多特性上和无缓冲通道类似,无缓冲通道可以看作长度为 0 的带缓冲通道。根据这个特性,带缓冲通道在下列情况下会发生阻塞:
- 带缓冲通道的存储数据达到上限时,再次写入数据将发生阻塞而导致异常。
- 带缓冲通道没有存储数据时,获取数据将发生阻塞而导致异常。
Go 语言为什么对通道要限制长度?因为多个协程之间使用通道必然存在写入和获取操作,这种模式类型的典型例子为生产者消费者模式。如果不限制通道长度,当写入数据速度大于获取速度,内存将不断膨胀直到应用崩溃。因此,限制通道的长度有利于约束数据生产速度,生产数据量必须在数据消费速度+通道长度的范围内,这样才能正常地处理数据。
关闭通道读取数据
当通道被阻塞的时候,程序为了防止无止境地等待而执行异常提示,在获取通道数据的时候,为了确保通道数据不出现阻塞,可以关闭通道再获取数据。关闭通道是使用关键字 close() 实现的,其使用示例如下:
package main
import "fmt"
func main() {
// 创建容量大小为2的通道
ch := make(chan int, 2)
// 往通道写入数据
ch <- 666
// 关闭通道
close(ch)
// 输出通道的长度和容量
fmt.Printf("通道长度:%v,容量:%v", len(ch), cap(ch))
// 关闭通道后再次写入数据
ch <- 777
}
运行上述示例,运行结果如下图所示。图 3 运行结果
从运行结果看到,使用 close() 关闭通道之后,如果再往通道里面写入数据,程序将提示异常,说明已关闭的通道是不支持数据写入操作的。但已关闭的通道支持数据获取操作,示例如下:
package main
import "fmt"
func main() {
// 创建容量大小为2的通道
ch := make(chan int, 2)
// 往通道写入数据
ch <- 666
// 关闭通道
close(ch)
// 输出通道的长度和容量
fmt.Printf("通道长度:%v,容量:%v\n", len(ch), cap(ch))
// 关闭通道后获取数据
fmt.Printf("通道数据:%v\n", <-ch)
fmt.Printf("通道数据:%v\n", <-ch)
}
运行上述示例,运行结果如下图所示。图 4 运行结果
示例代码说明如下:
- 当关闭通道之后,多次读取通道数据都不会提示异常,如上述代码的通道只存储一条数据,但执行两次数据读取操作。
- 在第二次读取的时候,通道已没有数据,所以读取结果为空值。不同数据类型的通道读取的空值各有不同:整型通道的空值为 0,字符串类型通道的空值为空字符串,布尔型通道的空值为 false,等等。
综上所述,通过关闭通道的方式可以解决通道数据读取的阻塞问题,但此方式不适合数据写入,并且仅适用于带缓存通道。因为无缓冲通道只要写入数据必须在另一个并发中读取数据,否则提示异常,这个过程可视为同步,完全没必要关闭通道。
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: