数据结构中的双向链表(Java详解版)
我们知道,单链表每个结点的指针域只有一个,用来存放后继结点的指针,而没有关于前驱结点的信息。因此,从某个结点出发,只能顺着指针往后查找其他结点。若要查找结点的前驱,则需要从表头结点开始,顺着指针寻找,显然,使用单链表处理不够方便。同样,从单链表中删除一个结点也会遇到类似的问题。
为了克服单链表的这种缺点,可以使用双向链表。
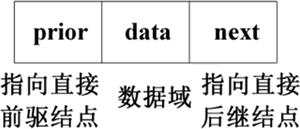
图 1 双向链表的结点结构
在双向链表中,每个结点包括 3 个域,分别是 data 域、prior 域和 next 域:
双向链表也可分为带头结点结构和不带头结点结构,带头结点结构使某些操作更加方便。另外,双向链表也有循环结构,称为双向循环链表。
带头结点的双向循环链表如下图所示。

图 2 带头结点的双向循环链表
双向循环链表为空的情况如下图所示,判断带头结点的双循环链表为空的条件是 head.prior==head 或 head.next==head。
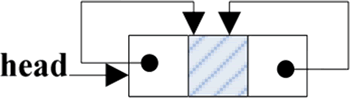
图 3 带头结点的双向循环链表为空的情况
在双向链表中,每个结点既有前驱结点的指针域又有后继结点的指针域,因此查找结点非常方便。若 p 是指向链表中某个结点的指针,则有 p=p.prior.next=p.next.prior。
双向链表的结点类型描述如下:
实现思路是:先找到第 i 个结点,用 p 指向该结点。再申请一个新结点,由 s 指向该结点,将 e 放入到据域。然后开始修改 p 和 s 指向的结点的指针域:
插入操作指针修改情况如下图所示:
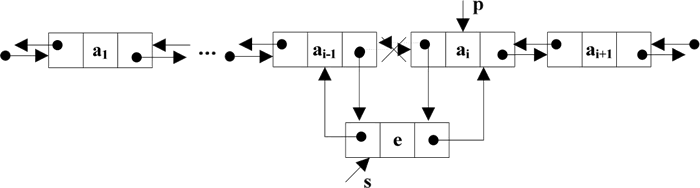
图 4 双向循环链表的插入操作过程
插入操作的算法实现如下:
实现思路是:先找到第 i 个结点,用 p 指向该结点。然后开始修改 p 指向的结点的直接前驱结点和直接后继结点的指针域,从而将 p 与链表断开。
将 p 指向的结点与链表断开需要两步:
删除操作指针修改情况如下图所示。

图 5 双向循环链表删除操作过程
删除操作的算法实现如下:
为了克服单链表的这种缺点,可以使用双向链表。
双向链表的存储结构
在双向链表中,每个结点有两个指针域:一个指向直接前驱结点,另一个指向直接后继结点。双向链表的结点结构如下图所示。图 1 双向链表的结点结构
在双向链表中,每个结点包括 3 个域,分别是 data 域、prior 域和 next 域:
- data 域为数据域,用于存放数据元素;
- prior 域为前驱结点指针域,指向直接前驱结点;
- next 域为后继结点指针域,指向直接后继结点。
双向链表也可分为带头结点结构和不带头结点结构,带头结点结构使某些操作更加方便。另外,双向链表也有循环结构,称为双向循环链表。
带头结点的双向循环链表如下图所示。
图 2 带头结点的双向循环链表
双向循环链表为空的情况如下图所示,判断带头结点的双循环链表为空的条件是 head.prior==head 或 head.next==head。
图 3 带头结点的双向循环链表为空的情况
在双向链表中,每个结点既有前驱结点的指针域又有后继结点的指针域,因此查找结点非常方便。若 p 是指向链表中某个结点的指针,则有 p=p.prior.next=p.next.prior。
双向链表的结点类型描述如下:
class DListNode {
int data;
DListNode prior, next;
DListNode(int data) {
this.data = data;
prior = null;
next = null;
}
}
public class DLinkList {
DListNode head;
DLinkList() {
head = new DListNode(0);
head.next = head.prior = head;
}
}
双向链表的插入操作和删除操作
对于双向链表的一些操作,如求链表的长度、查找链表的第 i 个结点等,与单链表中的算法实现基本没什么差异。但是,对于双向循环链表的插入和删除操作,因为涉及前驱结点指针和后继结点指针,所以需要修改两个方向的指针。1) 插入操作
插入操作就是在双向循环链表的第 i 个位置插入一个元素值为 e 的结点。若插入成功,则返回 true,否则返回 false。实现思路是:先找到第 i 个结点,用 p 指向该结点。再申请一个新结点,由 s 指向该结点,将 e 放入到据域。然后开始修改 p 和 s 指向的结点的指针域:
- 修改 s 的 prior 域,使其指向 p 的直接前驱结点,即 s.prior=p.prior;
- 将 p 的直接前驱结点的 next 域指向 s 指向的结点,即 p.prior.next=s;
- 修改 s 的 next 域,使其指向 p 指向的结点,即 s.next=p;
- 修改 p 的 prior 域,使其指向 s 指向的结点,即 p.prior=s。
插入操作指针修改情况如下图所示:
图 4 双向循环链表的插入操作过程
插入操作的算法实现如下:
public boolean InsertDList(int i, int e) {
DListNode p = head.next;
int j = 1;
while (p != head && j < i) {
p = p.next;
j++;
}
if (j != i) {
System.out.println("插入位置不正确!");
return true;
}
DListNode s = new DListNode(e);
s.prior = p.prior;
p.prior.next = s;
s.next = p;
p.prior = s;
return false;
}
2) 删除操作
删除操作就是将带头结点的双向循环链表中的第 i 个结点删除。若删除成功,则返回 true,否则返回 false。实现思路是:先找到第 i 个结点,用 p 指向该结点。然后开始修改 p 指向的结点的直接前驱结点和直接后继结点的指针域,从而将 p 与链表断开。
将 p 指向的结点与链表断开需要两步:
- 修改 p 的前驱结点的 next 域,使其指向 p 的直接后继结点,即 p.prior.next=p.next;
- 修改 p 的直接后继结点的 prior 域,使其指向 p 的直接前驱结点,即 p.next.prior=p.prior。
删除操作指针修改情况如下图所示。
图 5 双向循环链表删除操作过程
删除操作的算法实现如下:
public boolean DeleteDList(int i) {
DListNode p = head.next;
int j = 1;
while (p != head && j < i) {
p = p.next;
j++;
}
if (j != i) {
System.out.println("删除位置不正确!");
return false;
}
p.prior.next = p.next;
p.next.prior = p.prior;
return true;
}
插入和删除操作的时间主要耗费在查找结点上,两者的时间复杂度都为 O(n)。双向链表的插入和删除操作需要修改结点的 prior 域和 next 域,因此要注意修改结点指针域的顺序。
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: